SharedPreferences替换:MMKV集成与原理
前言
SharedPreferences是谷歌提供的轻量级存储方案,使用起来比较方便,可以直接进行数据存储,不必另起线程
不过也带来很多问题,尤其是由SP引起的ANR问题,非常常见。
正因如此,后来也出现了一些SP的替代解决方案,比如MMKV
本文主要包括以下内容
1.SharedPreferences存在的问题
2.MMKV的基本使用与介绍
3.MMKV的原理
SharedPreferences存在的问题
- SP的效率比较低
1.读写方式:直接I/O
2.数据格式:xml
3.写入方式:全量更新
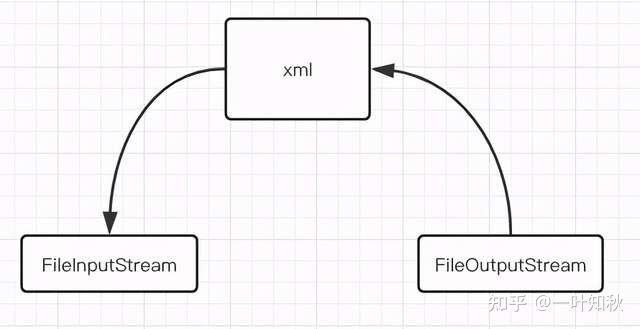
由于SP使用的xml格式保存数据,所以每次更新数据只能全量替换更新数据
这意味着如果我们有100个数据,如果只更新一项数据,也需要将所有数据转化成xml格式,然后再通过io写入文件中
这也导致SP的写入效率比较低
- commit导致的ANR
public boolean commit() {
// 在当前线程将数据保存到mMap中
MemoryCommitResult mcr = commitToMemory();
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, null);
try {
// 如果是在singleThreadPool中执行写入操作,通过await()暂停主线程,直到写入操作完成。
// commit的同步性就是通过这里完成的。
mcr.writtenToDiskLatch.await();
} catch (InterruptedException e) {
return false;
}
/*
* 回调的时机:
* 1\. commit是在内存和硬盘操作均结束时回调
* 2\. apply是内存操作结束时就进行回调
*/
notifyListeners(mcr);
return mcr.writeToDiskResult;
}
如上所示
1.commit有返回值,表示修改是否提交成功
2.commit提交是同步的,直到磁盘操作成功后才会完成
所以当数据量比较大时,使用commit很可能引起ANR
- Apply导致的ANR
commit是同步的,同时SP也提供了异步的apply
apply是将修改数据原子提交到内存, 而后异步真正提交到硬件磁盘, 而commit是同步的提交到硬件磁盘,因此,在多个并发的提交commit的时候,他们会等待正在处理的commit保存到磁盘后在操作,从而降低了效率。而apply只是原子的提交到内容,后面有调用apply的函数的将会直接覆盖前面的内存数据,这样从一定程度上提高了很多效率
但是apply同样会引起ANR的问题
public void apply() {
final long startTime = System.currentTimeMillis();
final MemoryCommitResult mcr = commitToMemory();
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
mcr.writtenToDiskLatch.await(); // 等待
......
}
};
// 将 awaitCommit 添加到队列 QueuedWork 中
QueuedWork.addFinisher(awaitCommit);
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);
}
};
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);
}
- 将一个 awaitCommit 的 Runnable 任务,添加到队列 QueuedWork 中,在 awaitCommit 中会调用 await() 方法等待,在 handleStopService 、 handleStopActivity 等等生命周期会以这个作为判断条件,等待任务执行完毕
- 将一个 postWriteRunnable 的 Runnable 写任务,通过 enqueueDiskWrite 方法,将写入任务加入到队列中,而写入任务在一个线程中执行
为了保证异步任务及时完成,当生命周期处于 handleStopService() 、 handlePauseActivity() 、 handleStopActivity() 的时候会调用 QueuedWork.waitToFinish() 会等待写入任务执行完毕
private static final ConcurrentLinkedQueue sPendingWorkFinishers =
new ConcurrentLinkedQueue();
public static void waitToFinish() {
Runnable toFinish;
while ((toFinish = sPendingWorkFinishers.poll()) != null) {
toFinish.run(); // 相当于调用 `mcr.writtenToDiskLatch.await()` 方法
}
}
- sPendingWorkFinishers 是 ConcurrentLinkedQueue 实例,apply 方法会将写入任务添加到 sPendingWorkFinishers队列中,在单个线程的线程池中执行写入任务,线程的调度并不由程序来控制,也就是说当生命周期切换的时候,任务不一定处于执行状态
- toFinish.run() 方法,相当于调用 mcr.writtenToDiskLatch.await() 方法,会一直等待
- waitToFinish() 方法就做了一件事,会一直等待写入任务执行完毕,其它什么都不做,当有很多写入任务,会依次执行,当文件很大时,效率很低,造成 ANR 就不奇怪了
所以当数据量比较大时,apply也会造成ANR
- getXXX() 导致ANR
不仅是写入操作,所有 getXXX() 方法都是同步的,在主线程调用 get 方法,必须等待 SP 加载完毕,也有可能导致ANR
调用 getSharedPreferences() 方法,最终会调用 SharedPreferencesImpl#startLoadFromDisk() 方法开启一个线程异步读取数据。
private final Object mLock = new Object();
private boolean mLoaded = false;
private void startLoadFromDisk() {
synchronized (mLock) {
mLoaded = false;
}
new Thread("SharedPreferencesImpl-load") {
public void run() {
loadFromDisk();
}
}.start();
}
正如你所看到的,开启一个线程异步读取数据,当我们正在读取一个比较大的数据,还没读取完,接着调用 getXXX() 方法。
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
awaitLoadedLocked();
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}
private void awaitLoadedLocked() {
......
while (!mLoaded) {
try {
mLock.wait();
} catch (InterruptedException unused) {
}
}
......
}
在同步方法内调用了 wait() 方法,会一直等待 getSharedPreferences() 方法开启的线程读取完数据才能继续往下执行,如果读取几 KB 的数据还好,假设读取一个大的文件,势必会造成主线程阻塞。
MMKV的使用
MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今在微信上使用,其性能和稳定性经过了时间的验证。近期也已移植到 Android / macOS / Win32 / POSIX 平台,一并开源。
- MMKV优点
1.MMKV实现了SharedPreferences接口,可以无缝切换
2.通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
3.MMKV数据序列化方面选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现
4.SP是全量更新,MMKV是增量更新,有性能优势
MMKV原理
- 为什么MMKV写入速度更快
- IO操作
我们知道,SP是写入是基于IO操作的,为了了解IO,我们需要先了解下用户空间与内核空间
虚拟内存被操作系统划分成两块:用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。

写文件流程:
1、调用write,告诉内核需要写入数据的开始地址与长度
2、内核将数据拷贝到内核缓存
3、由操作系统调用,将数据拷贝到磁盘,完成写入
- MMAP
Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。
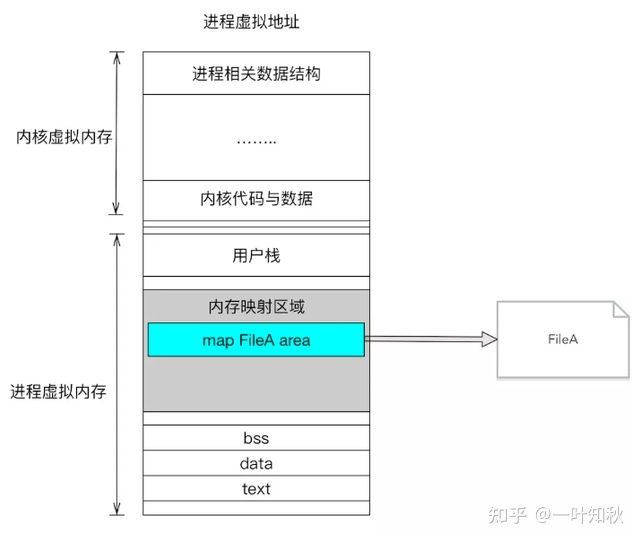
对文件进行mmap,会在进程的虚拟内存分配地址空间,创建映射关系。
实现这样的映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上
- MMAP优势
- MMAP对文件的读写操作只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件读写效率。
- MMAP使用逻辑内存对磁盘文件进行映射,操作内存就相当于操作文件,不需要开启线程,操作MMAP的速度和操作内存的速度一样快;
- MMAP提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统如内存不足、进程退出等时候负责将内存回写到文件,不必担心 crash 导致数据丢失。

可以看出,MMAP的写入速度基本与内存写入速度一致,远高于SP,这就是MMKV写入速度更快的原因
- MMKV写入方式
- SP的数据结构
SP是使用XML格式存储数据的,如下所示

但是这也导致SP如果要更新数据的话,只能全量更新
- MMKV数据结构
MMKV数据结构如下
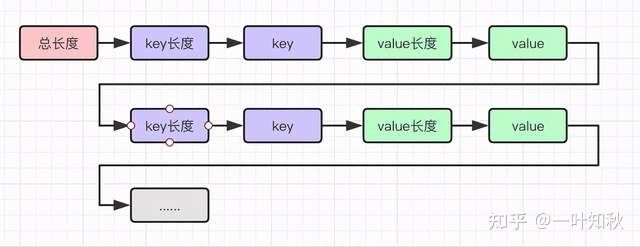
MMKV使用Protobuf存储数据,冗余数据更少,更省空间,同时可以方便地在末尾追加数据
- 写入方式
增量写入
不管key是否重复,直接将数据追加在前数据后。 这样效率更高,更新数据只需要插入一条数据即可。
当然这样也会带来问题,如果不断增量追加内容,文件越来越大,怎么办?
当文件大小不够,这时候需要全量写入。将数据去掉重复key后,如果文件大小满足写入的数据大小,则可以直接更新全量写入,否则需要扩容。(在扩容时根据平均每个K-V大小计算未来可能需要的文件大小进行扩容,防止经常性的全量写入)
MMKV三大优势
- mmap防止数据丢失,提高读写效率;
- 精简数据,以最少的数据量表示最多的信息,减少数据大小;
- 增量更新,避免每次进行相对增量来说大数据量的全量写入。
Android资料分享
为了让大家更好的去学习和提升自己,我和几位大佬一起收录整理的 Flutter进阶资料以及Android学习PDF+架构视频+面试文档+源码笔记 ,并且还有 高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料……
这些都是我闲暇时还会反复翻阅的精品资料。可以有效的帮助大家掌握知识、理解原理。当然你也可以拿去查漏补缺,提升自身的竞争力。
如果你有需要的话,可以前往 GitHub 自行查阅。