(二)ODS层更新:源表和目标表,没有last_update,比对取增量,却重复抽到某部分数据,怎么解决?

源表和目标表,比对的时候,某部分数据,每次比对都被认为是“新数据”,然后每次抽取比对都会被过滤到目标表,从而造成目标表有很多重复数据,是什么原因呢?原因是该表的多个字段“数据缺失严重”,我们比对数据前是已经给空值/空格填了默认值,也就是说这些被填充过的字段,是有很多重复值的。我们联表查询时,关联字段时有重复值时,那这次查询肯定会发散,而我们用的kettle【合并记录】插件的原理也是联表查询。
我的上一篇文章《ODS层更新:如果源数据没有“更新时间“字段,如何作增量抽取?我都踩过这些坑》提到用来联表的字段,一定是该条的数据的唯一标识。如果不是的话,那就造一个,多个字段作为“关联字段”避免发散。如果一条数据,10个字段,7个字段缺失,你怎么造“唯一标识”,最后联表比对时,还是会发散。也就是说,联表时,某部分数据字段值缺失严重,多对多联表是有风险的,那有没有其他取增量更优的解决方案呢?
即然多对多联表有风险,那就一对一联表,不就解决了吗?
- 取增量思路:
源表
LEFT OUTER JOIN
目标表
WHERE 目标表.关联字段 IS NULL - 建【源表】
CREATE TABLE work_exper(
id NUMBER(10),
name VARCHAR2(10),
company VARCHAR2(10),
job VARCHAR2(10),
work_start_date date,
work_end_date date
);
- 给【源表】插入数据
INSERT INTO work_exper VALUES(1001,'丧彪','百度','清洁工',to_date('1997-05-17','yyyy-mm-dd'),to_date('1998-08-15','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1001,'丧彪','腾讯','保安',to_date('1998-09-17','yyyy-mm-dd'),to_date('1999-12-15','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1001,'丧彪','阿里','炊事员',to_date('2000-07-17','yyyy-mm-dd'),to_date('2002-03-18','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1002,'段坤','快手','运营专员',to_date('1996-08-27','yyyy-mm-dd'),to_date('1998-02-08','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1002,'段坤','抖音','主播',to_date('1997-01-17','yyyy-mm-dd'),to_date('1998-02-14','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1002,'段坤','爱奇艺','COO',to_date('1999-05-19','yyyy-mm-dd'),to_date('2008-08-15','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1003,'阿祖','建行','催收员',to_date('2001-05-17','yyyy-mm-dd'),to_date('2018-04-12','yyyy-mm-dd'));
INSERT INTO work_exper VALUES(1001,'丧彪','阿里','炊事班长',to_date('2003-07-17','yyyy-mm-dd'),to_date('2020-03-18','yyyy-mm-dd'));
- 查询【源表】:
SELECT
id
,name
,job
,work_start_date
,work_end_date
FROM
work_exper

从上面的源表来看,字段ID+NAME+COMPANY+JOB就可以确定为该行数据的唯一标识了,但这是“多对多联表”,现实的业务场景,数据可不是那么规整的,一定是有很多缺失值的,所以我们如何作“一对一联表”呢?
- 用窗口函数row_number()over()给源数据造一个唯一标识
一个员工只有一个ID,但有多条工作记录,那我们可以以“ID"进行分组,在组内进行排序,最终将ID+排序结果,这样便可以得到"唯一标识"
SELECT
id||'_'||row_number()over(partition by id order by company,job,work_start_date,work_end_date) as pk_id
,id
,name
,job
,work_start_date
,work_end_date
FROM
work_exper

接下来建ods层目标表
- 建ods层【目标表】
CREATE TABLE ods_work_exper(
pk_id VARCHAR2(10),
id NUMBER(10),
name VARCHAR2(10),
company VARCHAR2(10),
job VARCHAR2(10),
work_start_date date,
work_end_date date
);
你可以看出,我并没有给字段pk_id建立“唯一主键约束”,也就是说我允许目标中出现重复的pk_id。为什么这样做呢?因为id分组组内排序是动态的,难免会出现有一天新数据的pk_id 和某条旧数据的pk_id一样,但其他字段不一样的。所以我们取增量的脚本可以改进成。
-
取增量思路改进:
源表
LEFT OUTER JOIN
目标表
WHERE 目标表.关联字段 IS NULL
OR 源表.字段 <>目标表字段.字段 -
脚本实例:
SELECT
A.pk_id
,A.id
,A.name
,A.company
,A.job
,A.work_start_date
,A.work_end_date
FROM
(
SELECT
id||'_'||row_number()over(partition by id order by company,job,work_start_date,work_end_date) as pk_id
, id
, name
, company
, job
, work_start_date
, work_end_date
FROM
work_exper
) A --源表
LEFT OUTER JOIN
ods_work_exper B --目标表
ON A.pk_id = B.pk_id
WHERE B.pk_id IS NULL
OR A.name <> B.name
OR A.company <> B.company
OR A.job <> B.job
OR A.work_start_date <> B.work_start_date
OR A.work_end_date <> B.work_end_date
实际的业务场景中,源表和目标表都是来自不同的数据库。如果源数据库没有赋权的情况下,异构数据联表查询是实现不了的。我们可以借助kettle的【记录集连接】插件
(流程概览)

- 1.1 源表:work_exper

- 1.2目标表:ods_work_exper

- 2.记录集连接

- 3.过滤记录
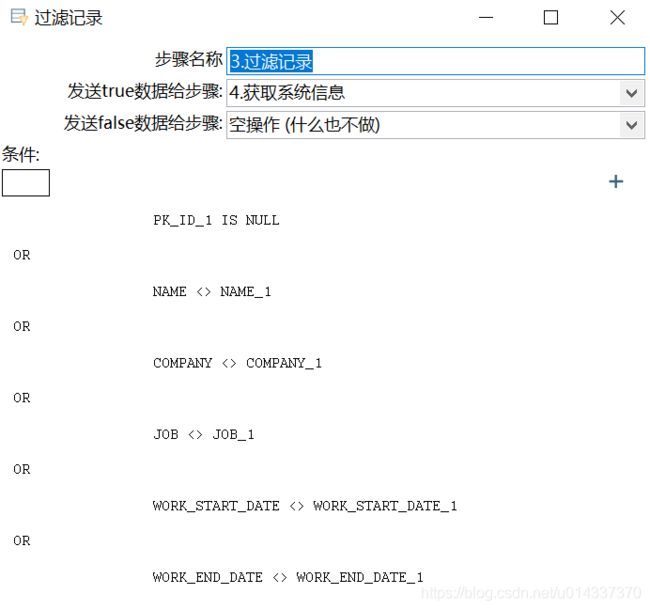
- 4.获取系统信息:给新增数据增加“last_update"字段

- 5.新增数据插入目标表:ods_work_exper
