python 写hello world 之深入爬虫爬取水文信息(四)
之前想到,用自己的所学的编程知识,来为自己的爱好,做一些事情,比如提供长江,嘉陵江,乌江水文信息。我用了1个星期,从数据抓取,到网站建设。
目前水文爬虫是从重庆水利局爬取的,这个数据是公开的,我们应该感谢zf提供如此好的,精准的数据,为我们泳友提供游泳水文信息,方便我们游泳。
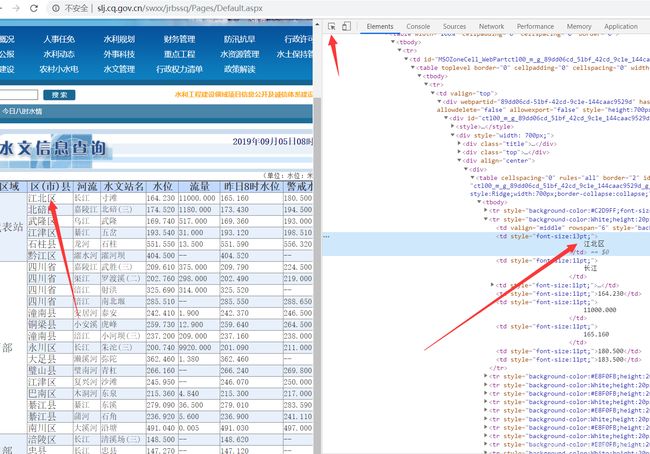
爬虫第一步查看数据来源,进入 http://slj.cq.gov.cn/swxx/jrbssq/Pages/Default.aspx 这个网站然后F12,进入浏览器调试模式,然后,点击调试模式的选取箭头,在左边页面上,点击想要查看的元素,然后调试器,就回自动的跳转到html中的元素中,然后右键,点击copy xpath,复制元素的路径:
//*[@id="ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv"]/tbody/tr[2]/td[2]
注意,这个xpath,直接用于python的话,是获取不到江北区的。
真实的xpath 是 :
//*[@id="ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv"]/tr[2]/td[3]/font
我也是找了好久,才试出来了。然后水文站名等,就很容易试出来了。
于是开始建立数据库,我用的是sqlite数据库,python自带的,不用安装其他的程序了。我把每一个水文站的数据,单独用一张表存放,然后用一张表存放映射,这样一来,方便程序代码读取,特别是后面前台程序的读取。当然你也可以全部数据放在一张表里面。
写这个程序,有一个难点:动态的改变 SQLAlchemy ORM 中models 类的数据库表。因为在数据库中,相同结构的数据库表,有许多,不可能每一张表都对应一个Python类,而我想法是,用一个类,对应多张表,每次使用这个类时,只需要改变类的表名字就好了。
所以就有了这么一段代码也就是改变,类的__table__.name 与 __tablename__,而且,在每次使用后,数据库需要close.
StationInfo.__table__.name = "station_info" + str(i - 2)
StationInfo.__tablename__ = "station_info" + str(i - 2)
u = models.StationInfo(station_city=station_city,
station_river=station_river,
station_name=station_name,
water_levev=water_levev,
flowrate=flowrate,
warnning_levev=warnning_levev,
ensure_levev=ensure_levev,
levev_time=intTime,
MD5=str_md5)
try:
db.session.add(u)
db.session.commit()
except Exception:
print("insert error")
db.session.rollback()
db.session.close()
db.session.flush()一下是本爬虫程序的完整代码:
# #coding=utf-8
import json
import lxml
from lxml import etree
import urllib
from urllib import request
from app import models
from app import db,g_tabelindex
import hashlib
import time
from app.models import StationInfo
"""
nStart = html.find('[{')
nEnd = html.find('}];')
html = html[nStart:nEnd+2]
json_data = json.loads(html)
cuntan =json_data[0]['stnm']
"""
if __name__=='__main__':
url = "http://slj.cq.gov.cn/swxx/jrbssq/Pages/Default.aspx"
response = urllib.request.urlopen(url)
html = response.read()
html = html.decode('utf-8')
mytree = lxml.etree.HTML(html)
# 时间单独列出来
levev_time = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_Label3\"]/text()")[0].strip('\r\n ')
# 2019年08月29日08时江河实时水情
# 20190829
levev_time = levev_time.replace("08时江河实时水情", "")
levev_time = levev_time.replace("年","")
levev_time = levev_time.replace("月","")
levev_time = levev_time.replace("日","")
intTime = int(levev_time)
ensure_levev = '111'
for i in range(2,41):
# 解析数据
if i == 2 or i == 8 or i==23 or i==26 or i==36:
station_city = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[2]/font/text()")[0].strip('\r\n ')
station_river = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[3]/font/text()")[0].strip('\r\n ')
station_name = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[4]/font/text()")[0].strip('\r\n ')
water_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[5]/font/text()")[0].strip('\r\n ')
flowrate = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[6]/font/text()")[0].strip('\r\n ')
yesterday_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[7]/font/text()")[0].strip('\r\n ')
warnning_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[8]/font/text()")[0].strip('\r\n ')
ensure_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[9]/font/text()")[0].strip('\r\n ')
else:
station_city = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[1]/font/text()")[0].strip('\r\n ')
station_river = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[2]/font/text()")[0].strip('\r\n ')
station_name = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[3]/font/text()")[0].strip('\r\n ')
water_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[4]/font/text()")[0].strip('\r\n ')
flowrate = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[5]/font/text()")[0].strip('\r\n ')
yesterday_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[6]/font/text()")[0].strip('\r\n ')
warnning_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[7]/font/text()")[0].strip('\r\n ')
ensure_levev = mytree.xpath("//*[@id=\"ctl00_m_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_g_89dd06cd_51bf_42cd_9c1e_144caac9529d_ASP_wpresources_jrbssqdefault_ascx_gv\"]/tr["+str(i)+"]/td[8]/font/text()")[0].strip('\r\n ')
if water_levev == '--':
water_levev = 0
if flowrate == '--':
flowrate = 0
if yesterday_levev == '--':
yesterday_levev = 0
if warnning_levev == '--':
warnning_levev = 0
if ensure_levev == '--':
ensure_levev = 0
MD5 = station_city + station_river + station_name + str(water_levev) + str(flowrate) + str(yesterday_levev) + str(warnning_levev) + str(ensure_levev) + levev_time
m = hashlib.md5()
b = MD5.encode(encoding='utf-8')
m.update(b)
str_md5 = m.hexdigest()
StationInfo.__table__.name = "station_info" + str(i - 2)
StationInfo.__tablename__ = "station_info" + str(i - 2)
u = models.StationInfo(station_city=station_city,
station_river=station_river,
station_name=station_name,
water_levev=water_levev,
flowrate=flowrate,
warnning_levev=warnning_levev,
ensure_levev=ensure_levev,
levev_time=intTime,
MD5=str_md5)
try:
db.session.add(u)
db.session.commit()
except Exception:
print("insert error")
db.session.rollback()
db.session.close()
db.session.flush()这个程序,还需要简单的Flask,Flask中的SQLAlchemy ,来配置数据库,因为这样使用数据库简直是太方便了。我会把全部代码放在QQ群文件中。
如过更多疑问与交流,请加python学习交流QQ群:475733139。