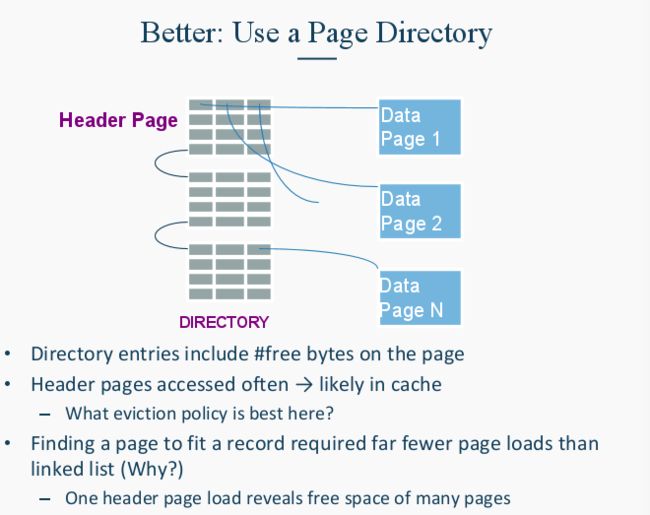
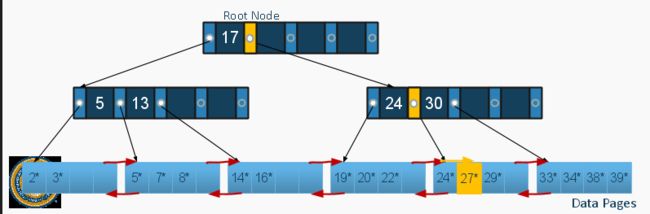
在数据库里,数据都是存在Page里的, 然后Pages是存放在Disk里的。
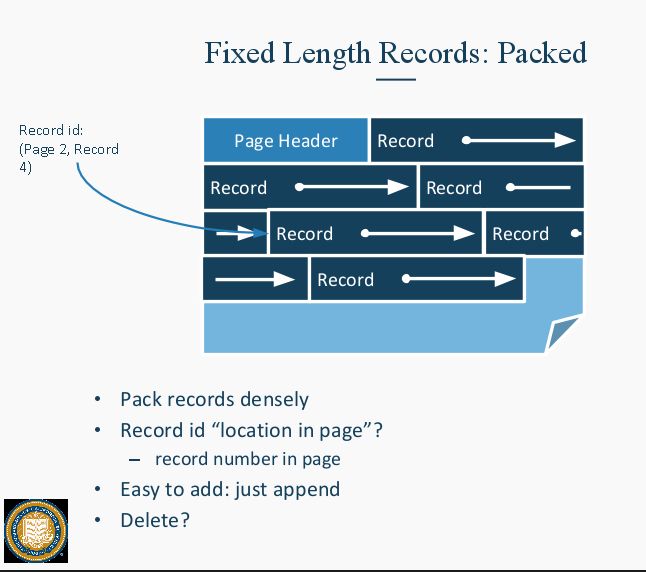
每一个Data Page里,有一个Page Header, 然后是Records。 可以设计为所有数据都是一样的长度的这种。 坏处是可能有的数据才1Byte,你给所有人都设计10Bytes的大小,浪费。好处是,从header里可以很容易找到哪个record是空的,哪个是满的。因为你知道record section起始点,然后知道每个record的大小。这样就很好iterate page里的东西。
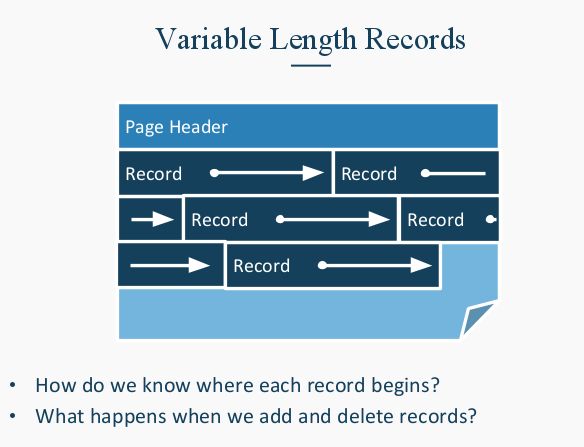
对于Variable的records,我们用Slot Directory. 每个Record ID都记录在slot table. Slot Directory里每个Id 用一个pointer, 指向record所在的地方。要删除东西的时候,设置pointer to Null. 要插入东西的话, 把record放在free space, 然后create pointer in next open slot in slot directory.

知道了page长什么样,所以要用什么数据结构存储数据呢?这个数据结构要在搜索,删除,插入上都非常牛逼。

B+ Tree:
整个储存data,查找数据, insert data之类的都会非常快速。
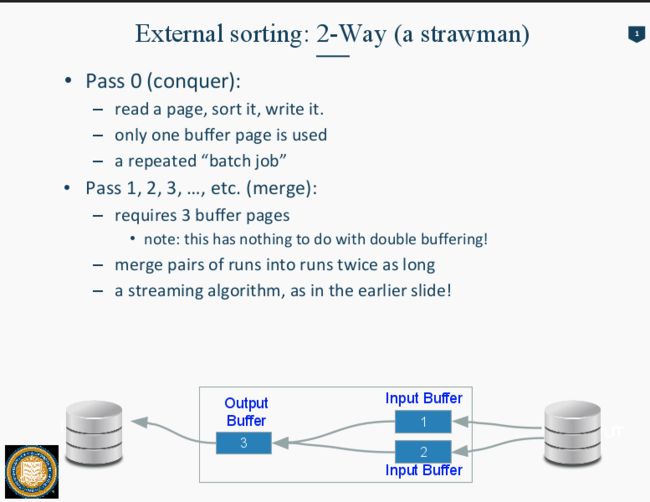
External Sorting是面试重点中的重点,设计了内存,大数据的考点。
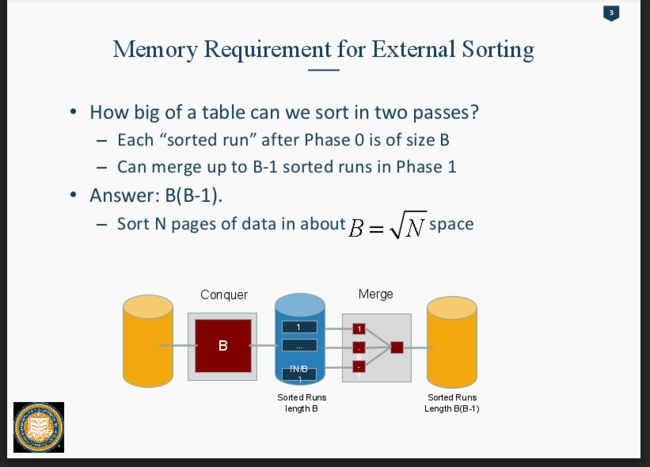
External Sorting过程: 假设我们有10 个page空间的内存。memory里一次可以放10个page
Input 为 90 page的File。
Phase0: 把90个Page依次存入内存里。 每次用B个Buffer,先进10个, output出来,再进10个。
每次存10个Page, 【因为内存也就10个page】,然后内存会在里面sorting,Sort成一个chunk of data.
最后一共会 output出9个chunk of data, 每个chunk 里面有10个page都排好序了.
Phase 1: 从这9个chunk里,每个chunk拿出第一张page,也就是每个chunk里最小的数据出来,装入内存里 进行排序。 这个时候内存的9个buffer装着9张page,然后拿一个buffer用来output to Disk. 每排序好一张page of data from 9 pages, buffer就打包这些到disk。当9个page里有一个page没有数据了,我们在disk里, 从那个page 所属的chunk里read more data to memory. 重复此操作直到结束。
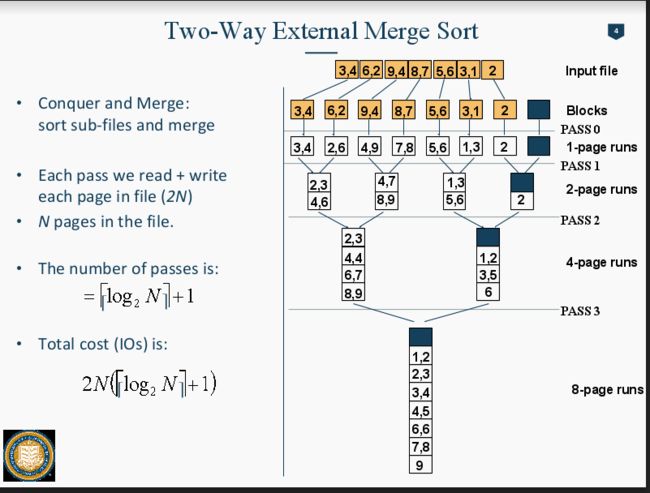

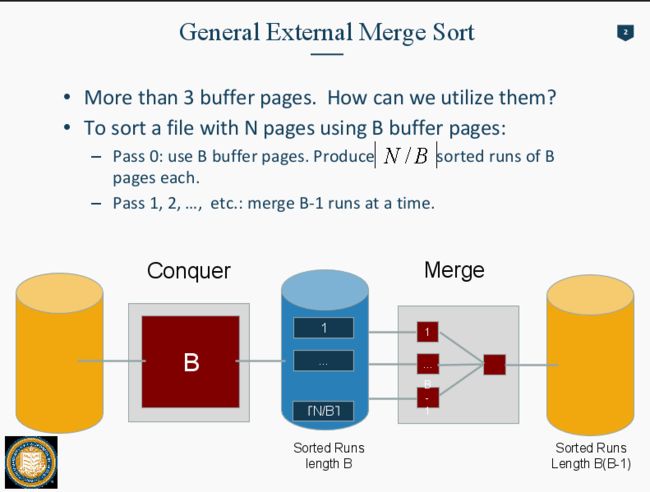
计算Number of Pass:
pass0: 是会分出N/B chunk of data
pass1,2.... 每个 Pass 可以merge B-1 Pages. 因为内存容量是B pages, 一个page要作为output to disk的工具,所以每次只能merge B-1 pages。
所以Number of pass: 1+logb-1[N/B]. 也就是pass 0 分出的chunk数量 能够除 Memory每次能merge的Page 数 的次数 +1

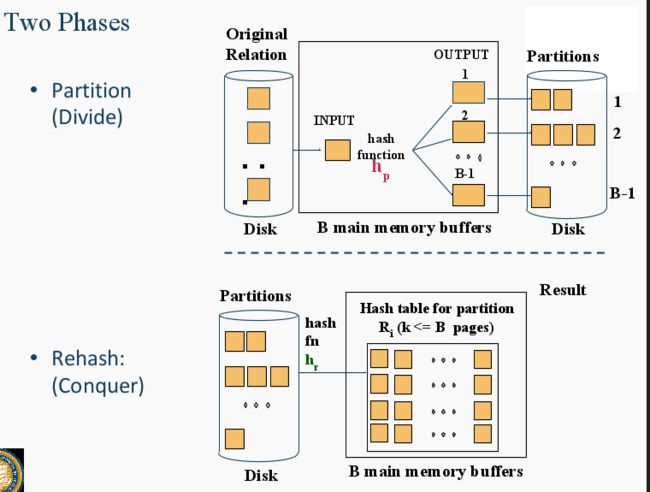
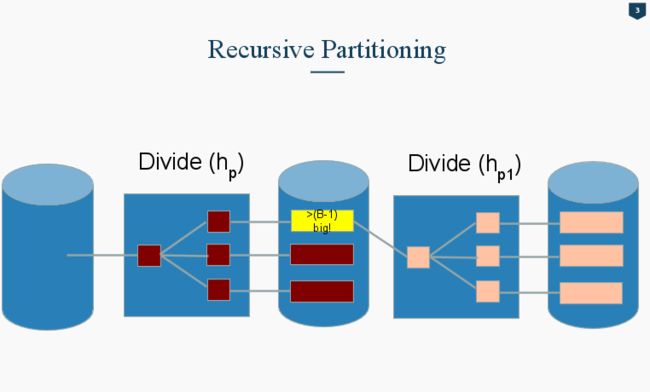
Join Optimization:
在没学过database之前,我一直觉得join 就是把两个page的data全部丢在一起。虽然确实是这样,但是操作顺序上的不同会引起极大的效率上的不一样。这里最主要是涉及到了内存这个东西。 因为每次join,都要把page里的数据load 进内存,在内存里真正join.
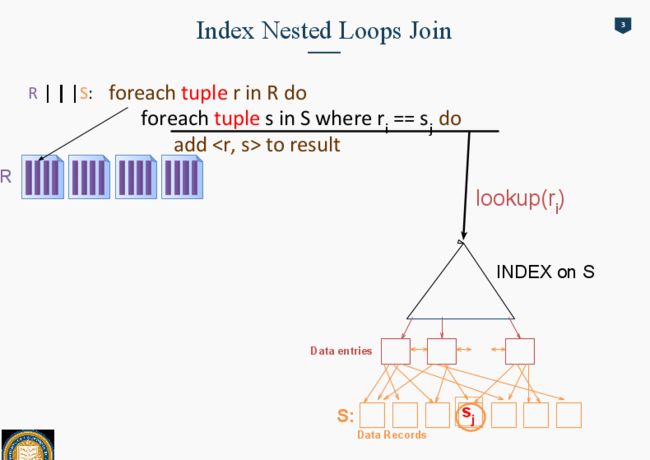
如果按下图的方法来join, R是一个数据库Table,S是一个数据库Table。 对于每个record in R, 他都会和所有的record in S依次join一遍。 这样并没有make use of 内存。因为每一个record都要load进内存在比较的话实在是太慢了。【正确姿势应该是page 全部load进内存,然后record就自动在内存里了】

如果是Page-Oriented Nested Loop Join
先从R取出一整张的data Page, 然后从S里的每一个Page依次拿出一张一张page。 每次把R的Page 和S的Page Load进内存里,然后每个record 之间join起来。这样算一下,操作量就减少了很多。
之所以Page-Oriented 快,因为我们do comparison in a page-to-page level. 假设内存RAM的容量是2 Pages。 一开始我们要load 1 page of R 和1 page of S 进内存。 cost 2 IOS. 假设这两张page一张叫r1, 一张叫s1. 现在我们要compare each record in r1 with each record in s1. 但是呢,因为他们已经在memory了,所以我们不用花任何的IOs. 比较完毕之后,把s1换成s2, 重复compare的操作。
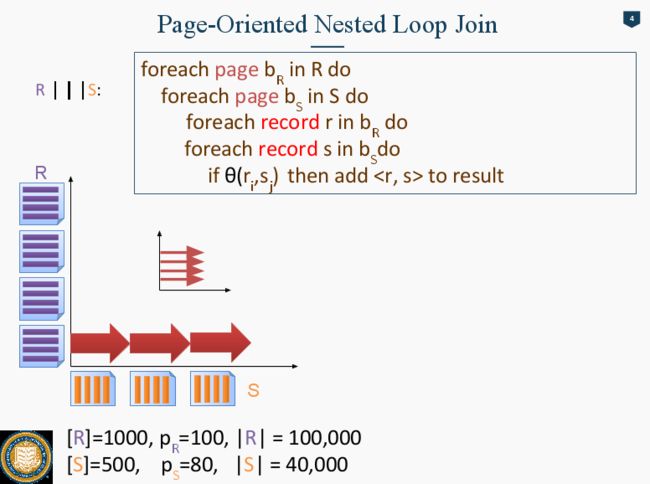

Block Nested Loop Join的话就不止是一次性只Load 一个page From R, 一个Page From S了。他是根据Memory的大小,尽量把memory能放下的pages全load进去。



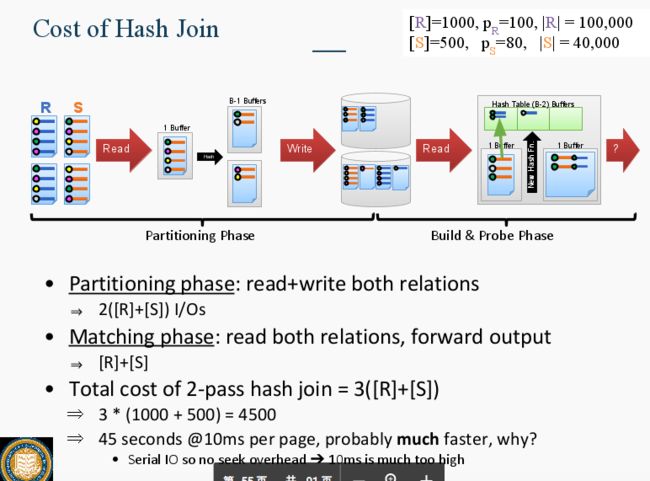
Query Optimization
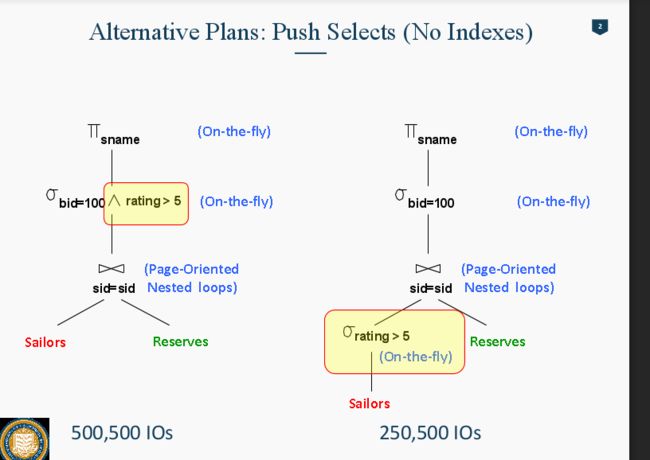
当要查找某个数据的时候,大家一般都用SQL的语言来查找,给定一些condition来过滤掉不要的来找想要的数据。 但是SQL的写法顺序其实也是对速度有很大的影响。 比如下面的例子:

上述例子是先把两个Table Join起来然后再过滤寻找。但是这时候Table Join好以后变得特别大,要过滤的数据也多了很多。
好一点的方法是,把operation push到下方。在Table join前,先把没用的赛选掉,这样工作量就小很多


------上面的都是database里比较基本的东西, 下面才是主菜---------------
一个好的数据库真正要解决的问题是当同时有许多人在用你的数据库,更新数据的时候不会发生混乱。还有,当transaction 取消/故障的时候,有办法恢复数据库。
Consistency: 表示每个人看到的同一个数据的值要一样。Durability是,如果transaction执行成功,并且commits了,就算之后数据库爆炸了,你也得给他恢复到原样,这个成功保存的资料不能丢失。Isolation: 某个数据我在用的时候,其他transaction不能来动他。

隔离别的transaction的基本做法: 按时间顺序来执行,先来的先做事,你后来就等着。 Serial Execution的坏处就是会很慢很慢。


T1想要转100刀从A账户给B账户
T2 想给A账户和B账户加10%的利息。

底下这个行程表,虽然看起来不是按serial[一个完整执行完,再执行第二个]。但是其实可以转化为Serial Schedule. 因为T2 干的事情对T1其实顺序上没什么影响。

Conflicting Operation概念:
Two operations are conflict if they are by different transactions, 并且是on the same Objects. 并且两个operation中至少有一个是Write. 这个东西理解起来不是很难其实。 假设transaction是人。 小明和小黄两个人,都想操作same object data x. 小明想要write, 小黄想要read。 这里会形成一个conflict 因为小黄read出来数据以后加以修改, 然后以后再write进A。假设小黄先read到x=10现在。 然后小黄10天后再去更新x的数据,x=x*0.8,想要改成11. 但是呢 小红在小黄read完以后马上修改了x的数据。这样小黄read到的数据就被改写了,之后的update也就不对了。





2PL 保证conflict Serialiablity. 2PL 就是两个阶段的锁。

2PL 的意思是分成两个阶段。 第一阶段 只能acquire Locks. 第二阶段只能release Locks 不能acquire Lock after lock release


Cascading Aborts的意思就是如果一个Transaction abort了,会有其他Transaction也要abort,因为依赖在这个Transaction上。形象一点就是我先往卡里存了1000块钱。你拿我卡去买东西。你刚买我告诉你我存钱失败了,你那笔交易也买不了了
2PL 的话就是我第一个Phase 大家都是Acquire Locks。
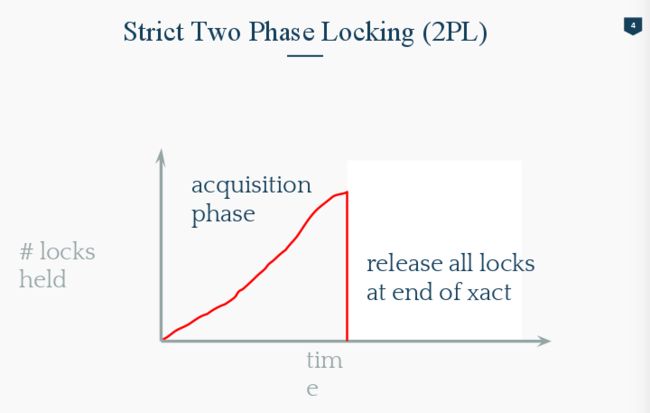
Strict 2PL就是为了解决cascading Aborts问题。确认了我这个Transaction已经完事了,你才可以拿到access这个资源的lock。
Strict 2PL 释放锁只有当Transaction 确定执行完毕的时候。如下图,T1 先拿到了锁,读取A数据,写入A数据,然后释放锁。这时候T2才可以拿到锁,读取A数据,写入A数据。


Lock有几种,1. S 可以read 这种锁可以被好几个人拿。就是大家不修改数据,只是看看。 2. X ,要修改数据的比如write。那他拿了以后别人就不能再拿S或者X锁了,因为这个人在改数据,别人现在不能read/write.
Deadlock就是一种死循环的情况。

解决办法:给每个Transaction Priority based on Time 1. wait die. 如果Ti 有更高的优先权,Ti waits for Tj, 否则的话, Ti 这个transaction就取消。
2.wound-wait; 如果Ti 有更高的优先权,Tj transaction直接爆炸,如果Ti没有更高的优先权,就等着直到Tj release。
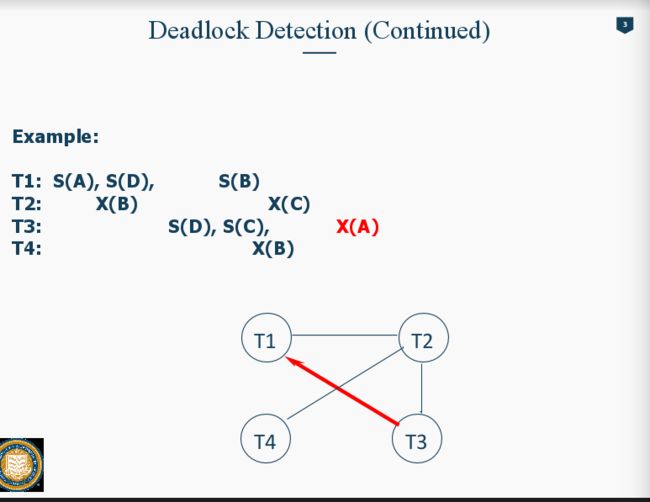
DeadLock Detection: 建造一个wait-for graph, 周期性的检查有没有cycle在graph里。 每次添加新的Transaction,都判断一次会不会有deadlock。

----数据还原---------
关键词: checkpoint, log.
大概流程就是 用checkpoint记录一下我们之前干过啥事情,周期性更新一次checkpoint。如果在某一步数据库爆炸了,我们把上次checkpoint到爆炸期间所有的操作重新做一遍, 把abort的Transaction的事情全部undo。 【这些操作都记录在log上】
要注意的是: 我们并不是一更新,写入东西。那些更新就直接真的写入数据库了,我们只是把他们写在log上,当前要干嘛干嘛的。然后等到一定周期,把这些全部写入数据库【也可以是后台他慢慢往数据库写,程序不管他们继续update】
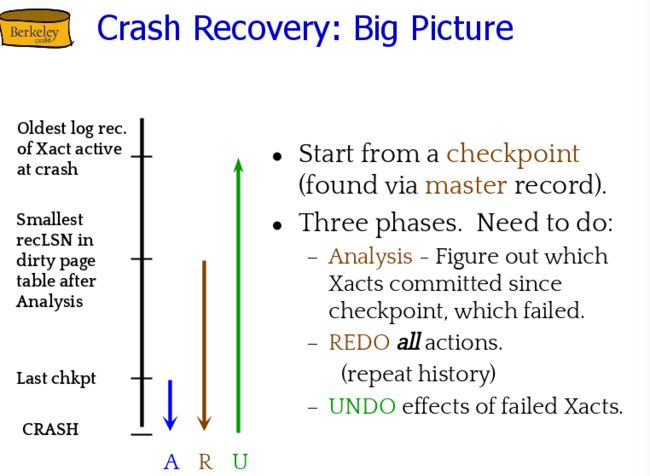
undo:从Transaction Table里找Max-LSN, 从那个Transaction往上undo.(往prevLSN) [commit了的Transaction是不会出现在Transaction Table的]。当crash发生的时候,这些已经执行的transaction要撤销掉,从每个Transaction干过的最后一件事情往前undo。 undo完它干过的所有事情。
Redo也是用来解决程序crash的问题的。 从当前Dirty Page Table里min RSN开始Redo。 在Dirty Table的东西就是,数据还没写入Disk,所以要重新把它们写入Disk。

