Python 正则表达式 贪婪匹配和惰性匹配 简单爬虫
我们先梳理下正则表达式知识点
正则表达式:
re模块
import re
re.match()
re.search()
re.findall()
re.sub(pattern,‘新的内容’,str)替换
基础:
. 任意字符
[]范围
| 或者
()一组
量词:
=0
+>=1
? 0,1
{m} =m
{m,}>=m
{m,n} >=m <=n
预定义:
\s space
\S not space
\d digit
\D not digit
\w word [0-9a-zA-Z]
\W not word [^0-9a-zA-Z]
分组
:
() —>group(1)
number : (\w+)(\d*) ------->group(1) group(2)
引用:( (\w+)(\d*) ) \1 \2 表示引用前面的内容
name
(?P\w+)(?P=name)
贪婪匹配和惰性匹配
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试尽可能稍的字符。
在“*”“?”“+”“{m,n}”后面机上?,是贪婪变成非贪婪。
举例:程序1(贪婪匹配)
import re
#默认是贪婪的
msg = 'abc123abc'
result = re.match(r'abc(\d+)',msg)
print(result)
结果1
<re.Match object; span=(0, 6), match='abc123'>
分析程序1:结果是abc123,这就是贪婪匹配,其实取到1也是成立的。
程序2
(非贪婪匹配:总是尝试匹配最少的字符。操作:在“*”“?”“+”“{m,n}”后面机上?,是贪婪变成非贪婪。)
# 但是我想取到abc1
#操作:在“*”“?”“+”“{m,n}”后面机上?,是贪婪变成非贪婪。
msg = 'abc123abc'
result = re.match(r'abc(\d+?)',msg)
print(result)
结果2
<re.Match object; span=(0, 4), match='abc1'>
接下来我们做一个小练习,试图从贴吧上获取一个图片的路径。
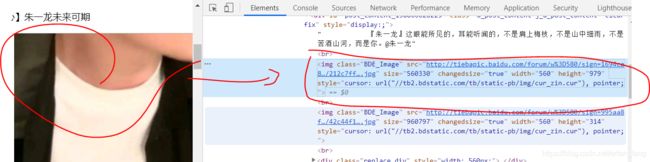
程序1
试着练习匹配到图片的路径
import re
path1 = ' '
result1 = re.match(r'
'
result1 = re.match(r') ,path1)
print(result1.group(1))
,path1)
print(result1.group(1))
结果1
http://tiebapic.baidu.com/forum/w%3D580/sign=1694ca82eb039245a1b5e107b795a4a8/212c7ff082025aaf71554284ecedab64024f1add.jpg" size="560330" changedsize="true" width="560" height="979" style="cursor: url("//tb2.bdstatic.com/tb/static-pb/img/cur_zin.cur"), pointer;
分析结果:我们不仅取到了src ,还取到了其他的信息。
程序2
path2 = ''
result2 = re.match(r') ,path2)
print(result2.group(1))
image_path = (result2.group(1))
,path2)
print(result2.group(1))
image_path = (result2.group(1))
结果2
http://tiebapic.baidu.com/forum/w%3D580/sign=1694ca82eb039245a1b5e107b795a4a8/212c7ff082025aaf71554284ecedab64024f1add.jpg
分析结果2:我们取到了这个路径
接下来我们获取到这个图片,到当前路径下
程序3
import re
path2 = ''
result2 = re.match(r',path2)
print(result2.group(1))
image_path = (result2.group(1))
import requests
response = requests.get(image_path)
with open('aa.jpg','wb') as wstream:
wstream.write(response.content)
结果3:
http://tiebapic.baidu.com/forum/w%3D580/sign=1694ca82eb039245a1b5e107b795a4a8/212c7ff082025aaf71554284ecedab64024f1add.jpg


日后爬虫也就是这个思路的,可通过正则,封装好的一些方式进行爬虫。