用jTessBoxEditor训练tesseract模型
导语:
上文我们讲到了怎么使用tesseract,本文讲一下怎么对手写的数字进行训练,看完之后可以举一反三对
其他语言比如中文或者其他文字甚至是符号进行自己的训练,方式方法都是通用的。
前提条件:
1.安装java环境(因为jTessBoxEditor使用java的写一个图形化的工具,所以需要java的运行环境,不会的请自行谷歌啦)
2.安装好tesseract(sourceforge下载地址)
3.识别不准的图片(这里我先手写了一张12345的图片,识别出来的是1365,默认使用的eng语言库)
如下:
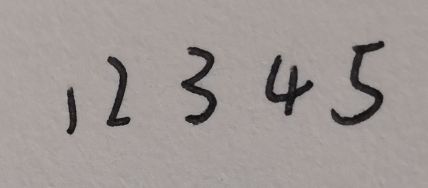
结果:
tesseract 12345.png stdout
1365
训练步骤:
1.打开jTessBoxEditor
在命令行输入
java -jar jTessBoxEditor
就会弹出一个交互式的窗口
2.选择Tools->Merge TIFF
3.然后选择一张图片,这里我创建了一个train的目录用来放图片和接下来的各种文件
文件名命名格式是:[lang].[fontname].exp[num].tif
lang-语言
fontname-字体
num-自定义的数字
这里因为是识别的数字,所以我取的是num.test.exp0.tif。
后面的步骤会反复用到这个名字。
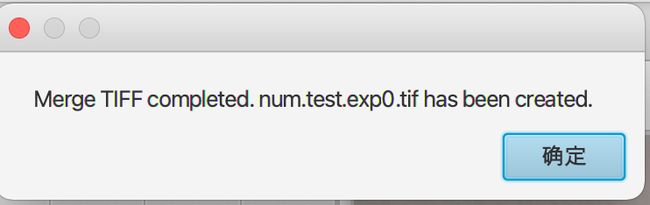
完成后jTessBoxEditor工具会出现下面的弹框,并且在当前train目录会生成num.test.exp0.tif的文件。
4.生成box文件,box就是把每个识别出来的文字框起来
输入命令:
tesseract num.test.exp0.tif num.test.exp0 --psm 3 batch.nochop makebox
运行成功会生成一个num.test.exp0.box的文件
5.接下来训练刚才的图片(其实就是手动把错误的识别结果改成正确的)
打开jTessBoxEdtor->Box Editor->Open,打开之前的num.test.exp0.tif,这里会使用到同目录下的num.test.exp0.box,所以要都放在同一个目录下。
把没有识别出来的2,在Char栏目填上,把识别错误的4改为6。修改完成后记得按回车然后Save保存起来。
6.生成font_properties文件
可以手创建一个空文件然后填上test 0 0 0 0 0
说明:
test 0 0 0 0 0
【语法】:
【语法】:fontname为字体名称,italic为斜体,bold为黑体字,
fixed为默认字体,serif为衬线字体,fraktur德文黑字体,
1和0代表有和无,精细区分时可使用
也可以使用命令:
echo test 0 0 0 0 0 > font_properties
记住字体名称必须和之前的num.test.exp0中的test保持一致。
7.生成训练文件
tesseract num.test.exp0.tif num.test.exp0 nobatch box.train
8.生成字符集
unicharset_extractor zwp.test.exp0.box
执行成功会生成unicharset的文件
这里有一点要注意,如果你安装的tesseract是没有带训练工具的话,你会被提示
zsh: command not found: unicharset_extractor
可以参考另一篇blog:zsh: command not found: unicharset_extractor
9.生成聚字符特征文件
输入命令:
mftraining -F font_properties -U unicharset -O num.unicharset num.test.exp0.tr
执行成功后会生成inttemp、pffmtable、shapetable和num.unicharset四个文件
10.生成字符正常化特征文件
cntraining num.test.exp0.tr
执行成功后会生成normproto的文件
11.重命名文件
mv normproto num.normproto
mv inttemp num.inttemp
mv pffmtable num.pffmtable
mv shapetable num.shapetable
12.合并训练文件
combine_tessdata num.
会生成一个num.traineddata的文件,看到这里是不是笑开了花?没错这个就是最终的训练集了,把这个放到tesseract的tessdata目录之下。
可能是/usr/local/Cellar/tesseract/4.1.1/share/tessdata也可能是/usr/local/share/tessdata
13.最终结果:

总结:
1.要想完成这个流程要使用安装了训练工具的tesseract,tesseract现在好像不支持带训练工具的安装参数了,安装会报下面的错误(本人使用的是tesseract4.1.1版本) Error: invalid option: --with-training-tools
,所以安装训练工具需要自己编译安装,可以参考博客
2.其实整个步骤中绝大部分命令可以使用脚本帮忙完成掉,只有jTessBoxEditor标注矫正结果需要使用到界面,如果可以把jTessBoxEditor标注结果做成一个工具,矫正完剩下的命令都自动执行就可以批量的训练了。