一文搞定(三) —— 高斯过程回归 Gaussian Process Regression
2021.03.07 更新: 优化了 section 1 的内容,删去文章原先结构中的 2、3 两个 section(这两部分涉及高斯过程的权重空间视角,因并不实用且易产生混淆而得到删除,但其完整内容仍然可以在作者的个人博客中查看:链接 )
2021.03.27 更新: 丰富了 section 2 的内容,添加了更多图像化的、从而易于理解的表述。
【参考资料】
1.B站:机器学习-白板推导系列(二十)-高斯过程GP(Gaussian Process)
2.CSDN:一文搞定(二)—— 贝叶斯线性回归
3.知乎:Gaussian process regression的导出——权重空间视角下的贝叶斯的方法
4.知乎:高斯过程 Gaussian Processes 原理、可视化及代码实现
【文章结构】
1 Introduction: 从高斯分布到高斯过程
2 高斯过程回归 Gaussian Process Regression
3 代码示例 (包含对于一个简单 GPR 示例的 python 和 matlab 两种语言的代码)
1 Introduction: 从高斯分布到高斯过程
1.1 多元高斯分布
p ( x ) = ∏ i = 1 n p ( x i ) = 1 ( 2 π ) n 2 σ 1 . . . σ n exp ( − 1 2 [ ( x 1 − μ 1 ) 2 σ 1 2 . . . ( x n − μ n ) 2 σ 2 2 ] ) (1) \tag{1} p(\bm{x})=\prod_{i=1}^n p(x_i)=\frac{1}{(2\pi)^{\frac{n}{2}}\sigma_1...\sigma_n}\exp(-\frac{1}{2}[\frac{(x_1-\mu_1)^2}{\sigma_1^2}...\frac{(x_n-\mu_n)^2}{\sigma_2^2}]) p(x)=i=1∏np(xi)=(2π)2nσ1...σn1exp(−21[σ12(x1−μ1)2...σ22(xn−μn)2])(1)
进一步的,令
- x − μ = [ x 1 − μ 1 , . . . , x n − μ n ] T \bm{x-\mu}=[x_1-\mu_1,...,x_n-\mu_n]^T x−μ=[x1−μ1,...,xn−μn]T
- Σ = [ σ 1 2 0 . . . 0 0 σ 2 2 . . . 0 . . . . . . . . . . . . . 0 . . . 0 σ n 2 ] \bm\Sigma=\begin{bmatrix} \sigma_1^2 & 0 & ... & 0 \\ 0 & \sigma_2^2 & ... & 0 \\ ... & ... & ... & .... \\ 0 & ... & 0 & \sigma_n^2 \end{bmatrix} Σ=⎣⎢⎢⎡σ120...00σ22...............000....σn2⎦⎥⎥⎤
从而可得多元高斯分布的向量化表示:
p ( x ) = ( 2 π ) − n 2 ∣ Σ ∣ − 1 2 exp ( − 1 2 ( x − μ ) T ∣ Σ ∣ − 1 ( x − μ ) ) (2) \tag{2} p(\bm{x})=(2\pi)^{-\frac{n}{2}}|\bm\Sigma|^{-\frac{1}{2}}\exp(-\frac{1}{2}(\bm{x}-\bm{\mu})^T|\bm\Sigma|^{-1}(\bm{x}-\bm{\mu}) ) p(x)=(2π)−2n∣Σ∣−21exp(−21(x−μ)T∣Σ∣−1(x−μ))(2)
(留意上式中的 ( x − μ ) T ∣ Σ ∣ − 1 ( x − μ ) (\bm{x}-\bm{\mu})^T|\bm\Sigma|^{-1}(\bm{x}-\bm{\mu}) (x−μ)T∣Σ∣−1(x−μ),它与下文将要介绍的 kernel function 有着类似的形式)
1.2 高斯过程 Gaussain Process
高斯过程是定义在连续域上的无限多个高维随机变量所组成的随机过程,可以看做是一个无限维的高斯分布。在作者的理解中,通过高斯过程,我们能够将离散的点分布转化为函数的分布。
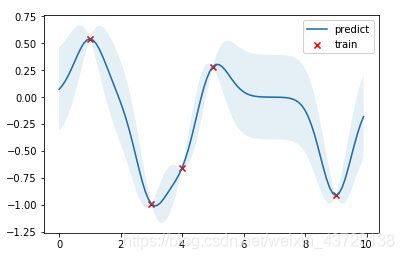
借用参考资料 4 中的插图,高斯过程在下图中的体现就是将红色的离散点变成蓝色的函数曲线(该曲线不仅能够储存原离散数据集的部分特征,还能用于预测):
GP 的数学定义
对于随机变量 { ζ t } t ∈ T \{\zeta_t\}_{t\in T} { ζt}t∈T ( T T T 可以是连续的时间或空间),如果对于任意 n ∈ N + , t 1 , . . . , t n → ζ 1 , . . . , ζ n n\in \N^+,\;\;t_1,...,t_n\to \zeta_1,...,\zeta_n n∈N+,t1,...,tn→ζ1,...,ζn, 都有 ζ = ( ζ 1 , . . . , ζ n ) T ∼ N ( μ , Σ ) \bm{\zeta}=(\zeta_1,...,\zeta_n)^T \sim N(\bm{\mu},\bm{\Sigma}) ζ=(ζ1,...,ζn)T∼N(μ,Σ), 那么 { ζ t } t ∈ T \{\zeta_t\}_{t\in T} { ζt}t∈T 就是一个高斯过程,记做
ζ t ∼ G P ( m ( t ) , κ ( s , t ) ) (3) \tag{3}\zeta_t\sim GP(m(t),\kappa(s,t)) ζt∼GP(m(t),κ(s,t))(3)
- m ( t ) = E [ ζ t ] m(t)=E[\zeta_t] m(t)=E[ζt], mean function
- κ ( t , s ) = E [ ( ζ s − m ( s ) ) ( ζ t − m ( t ) ) T ] \kappa(t,s)=E[(\zeta_s-m(s))(\zeta_t-m(t))^T] κ(t,s)=E[(ζs−m(s))(ζt−m(t))T], covariance function
2 高斯过程回归 Gaussian Process Regression
假设样本集 { f ( x ) } \{f(x)\} { f(x)} 满足:
{ f ( x ) } x ∈ R p ∼ G P ( m ( x ) , κ ( x , x ′ ) ) \{f(x)\}_{x\in \R^p}\sim GP(m(x),\kappa(x,x')) { f(x)}x∈Rp∼GP(m(x),κ(x,x′))
- m ( x ) = E [ f ( x ) ] m(x)=E[f(x)] m(x)=E[f(x)]
- κ ( x , x ′ ) = E [ ( f ( x ) − m ( x ) ) ( f ( x ′ ) − m ( x ′ ) ) T ] \kappa(x,x')=E[(f(x)-m(x))(f(x')-m(x'))^T] κ(x,x′)=E[(f(x)−m(x))(f(x′)−m(x′))T]
2.1 回归 Regression
给定数据集,
D = { ( x i , y i ) } i = 1 N , y = f ( x ) + ε D=\{(x_i,y_i)\}_{i=1}^N,\;y=f(x)+\varepsilon D={ (xi,yi)}i=1N,y=f(x)+ε
where, ε ∼ N ( 0 , σ ) \varepsilon\sim N(0, \sigma) ε∼N(0,σ)
定义 X = [ ( x 1 , . . . , x N ) T ] N × p , Y = [ ( y 1 , . . . , y N ) T ] N × 1 X=[(x_1,...,x_N)^T]_{N\times p},\; Y=[(y_1,...,y_N)^T]_{N\times 1} X=[(x1,...,xN)T]N×p,Y=[(y1,...,yN)T]N×1,再结合先前的假设可得:
f ( X ) ∼ N ( μ ( X ) , κ ( X , X ) ) Y = f ( X ) + ε ∼ N ( μ ( X ) , κ ( X , X ) + σ 2 I ) f(X)\sim N(\mu(X),\kappa(X,X))\\[8pt] Y=f(X)+\varepsilon \sim N(\mu(X),\kappa(X,X)+\sigma ^2I) f(X)∼N(μ(X),κ(X,X))Y=f(X)+ε∼N(μ(X),κ(X,X)+σ2I)
至此我们完成了 GPR 的回归部分。以下图为例(同 section 1.2 中的图):回归 在这张图里的体现就是提取了数据点(红叉叉)所包含的已知数据集的特征信息,并将其转换为了一个高斯模型。(注:上文中的特征信息主要包含两个方面,一个是自变量信息,例如下图中的 x 轴数值,当然可以是多维的;另一个是因变量信息,例如下图中的 y 轴数值)
2.2 预测 Prediction
给定需要预测的数据 X ∗ = ( x 1 ∗ , . . . , x M ∗ ) T X^*=(x_1^*,...,x_M^*)^T X∗=(x1∗,...,xM∗)T,求 Y ∗ Y^* Y∗
( Y f ( X ∗ ) ) ∼ N ( ( μ ( X ) μ ( X ∗ ) ) , ( κ ( X , X ) + σ 2 I κ ( X , X ∗ ) κ ( X ∗ , X ) κ ( X ∗ , X ∗ ) ) ) \begin{pmatrix} Y \\ f(X^*) \end{pmatrix} \sim N\begin{pmatrix} \begin{pmatrix} \mu(X) \\ \mu(X^*) \end{pmatrix}, \begin{pmatrix} \kappa(X,X)+\sigma^2I & \kappa(X,X^*) \\ \kappa(X^*,X) & \kappa(X^*,X^*) \end{pmatrix} \end{pmatrix} (Yf(X∗))∼N((μ(X)μ(X∗)),(κ(X,X)+σ2Iκ(X∗,X)κ(X,X∗)κ(X∗,X∗)))
已知公式,对于 X ∼ N ( μ , Σ ) X\sim N(\mu,\Sigma) X∼N(μ,Σ)
If X = ( X a X b ) , μ = ( μ a μ b ) , Σ = ( Σ a a Σ a b Σ b a Σ b b ) then X b ∣ X a ∼ N ( μ b ∣ a , Σ b ∣ a ) \text{If}\;X=\begin{pmatrix} X_a \\ X_b \end{pmatrix}, \mu=\begin{pmatrix} \mu_a \\ \mu_b \end{pmatrix}, \Sigma=\begin{pmatrix} \Sigma_{aa} & \Sigma_{ab} \\ \Sigma_{ba} & \Sigma_{bb} \end{pmatrix} \\[8pt] \text{then }X_b|X_a\sim N(\mu_{b|a},\Sigma_{b|a}) IfX=(XaXb),μ=(μaμb),Σ=(ΣaaΣbaΣabΣbb)then Xb∣Xa∼N(μb∣a,Σb∣a)
where,
- μ b ∣ a = Σ b a Σ a a − 1 ( X a − μ a ) + μ b \mu_{b|a}=\Sigma_{ba}\Sigma_{aa}^{-1}(X_a-\mu_a)+\mu_b μb∣a=ΣbaΣaa−1(Xa−μa)+μb
- Σ b ∣ a = Σ b b − Σ b a Σ a a − 1 Σ a b \Sigma_{b|a}=\Sigma_{bb}-\Sigma_{ba}\Sigma_{aa}^{-1}\Sigma_{ab} Σb∣a=Σbb−ΣbaΣaa−1Σab
根据该公式可得
P ( f ( X ∗ ) ∣ Y , X , X ∗ ) = P ( f ( X ∗ ) ∣ Y ) ∼ N ( μ ∗ , Σ ∗ ) P(f(X^*)|Y,X,X^*)=P(f(X^*)|Y)\sim N(\mu^*,\Sigma^*) P(f(X∗)∣Y,X,X∗)=P(f(X∗)∣Y)∼N(μ∗,Σ∗)
where,
- μ ∗ = κ ( X ∗ , X ) ( κ ( X , X ) + σ 2 I ) − 1 ( Y − μ ( X ) ) + μ ( X ∗ ) \mu^*=\kappa(X^*,X)(\kappa(X,X)+\sigma^2I)^{-1}(Y-\mu(X))+\mu(X^*) μ∗=κ(X∗,X)(κ(X,X)+σ2I)−1(Y−μ(X))+μ(X∗)
- Σ ∗ = κ ( X ∗ , X ∗ ) − κ ( X ∗ , X ) ( κ ( X , X ) + σ 2 I ) − 1 κ ( X , X ∗ ) \Sigma^*=\kappa(X^*,X^*)-\kappa(X^*,X)(\kappa(X,X)+\sigma^2I)^{-1}\kappa(X,X^*) Σ∗=κ(X∗,X∗)−κ(X∗,X)(κ(X,X)+σ2I)−1κ(X,X∗)
最终可得,
P ( y ∗ ∣ Y , X , X ∗ ) ∼ N ( μ ∗ , Σ ∗ + σ 2 I ) P(y^*|Y,X,X^*)\sim N(\mu^*,\Sigma^*+\sigma^2I) P(y∗∣Y,X,X∗)∼N(μ∗,Σ∗+σ2I)
至此我们完成了 GPR 的预测部分。依旧以同样的一幅图为例:预测 在这张图里的体现就是根据 回归 得到的信息,预测其他点位的函数值及其标准差(蓝色线条以及浅蓝色区域)。
3 代码示例
简单高斯过程回归实现
(斜体部分内容来自参考资料 4)
考虑代码实现一个高斯过程回归,API 接口风格采用 sciki-learn fit-predict 风格。由于高斯过程回归是一种非参数化 (non-parametric) 的模型,每次的 inference 都需要利用所有的训练数据进行计算得到结果,因此并没有一个显式的训练模型参数的过程,所以 fit 方法只需要将训练数据保存下来,实际的 inference 在 predict 方法中进行。
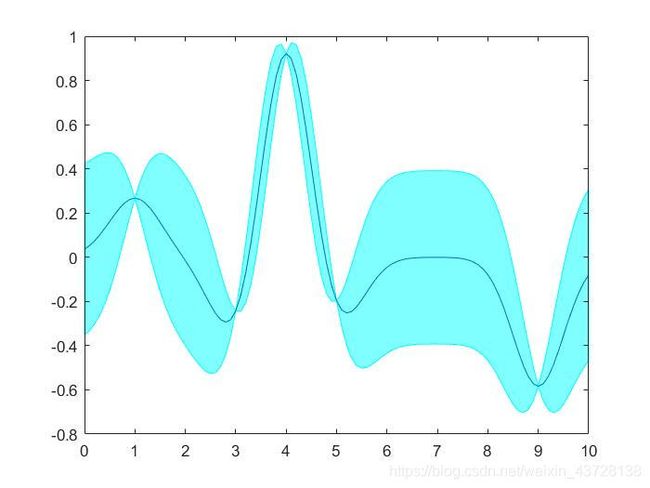
结果如下图,红点是训练数据,蓝线是预测值,浅蓝色区域是 95% 置信区间。真实的函数是一个 cosine 函数,可以看到在训练数据点较为密集的地方,模型预测的不确定性较低,而在训练数据点比较稀疏的区域,模型预测不确定性较高。
python 实现
详见 参考资料 4
matlab 实现
定义类
classdef GPR
properties
is_fit = 0;
train_X = nan;
train_y = nan;
params = struct('l', 0.5, 'sigma_f', 0.2);
end
methods
function obj = GPR()
end
function obj = fit(obj, X, y)
obj.train_X = X;
obj.train_y = y;
obj.is_fit = 1;
end
function [mu, cov] = predict(obj, X)
if obj.is_fit == 0
disp('model not fit yet')
end
Kff = obj.kernel(obj.train_X, obj.train_X);
Kyy = obj.kernel(X, X);
Kfy = obj.kernel(obj.train_X, X);
Kff_inv = inv(Kff + 1e-8 * eye(length(obj.train_X)));
mu = Kfy' * Kff_inv * obj.train_y;
cov = Kyy - Kfy' * Kff_inv * Kfy;
end
function result = kernel(obj, x1, x2)
distance = x1.^2 + (x2.^2)' - 2 * x1 * x2';
sigma_f = obj.params.('sigma_f');
l = obj.params.('l');
result = sigma_f^2 * exp(-distance/(2*l^2));
end
end
end
训练 + 预测
train_X = [3, 1, 4, 5, 9]';
train_y = cos(train_X);
test_X = 0:0.1:10;
test_X = test_X';
gpr = GPR();
gpr = gpr.fit(train_X, train_y);
[mu, cov] = gpr.predict(test_X);
uncertainty = 1.96 * sqrt(diag(cov));
figure;
xfill = [test_X', fliplr(test_X')];
yfill = [(mu - uncertainty)', fliplr((mu + uncertainty)')];
fill(xfill, yfill, 'c', 'FaceAlpha', 0.5, 'EdgeAlpha', 1, 'EdgeColor', 'c');
hold on;
plot(test_X, mu);
结果示意图