Pandas中的数据拆分成组—groupby()方法
在Pandas中,可以通过groupby()方法将数据集按照某些标准划分成若干个组,该方法的语法格式如下:
groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=False,observed=False,kwargs)
上述参数的含义如下:
- by:用于确定进行分组的依据。 //也可以指定多个列名,区别是单个列名分组的主键或索引是单个主键;多个列名是元组的形式
- axis:表示分组轴的方向,可以为0(表示按行)或(表示按列),默认为0。
- level:如果某个轴是一个MultiIndex对象,则会按特定级别或多个级别分组。
- as_index:表示聚合后的数据是否以组标签作为索引的DataFrame对象输出,,接受布尔值,默认为True。
- sort:表示是否对分组标签进行排序,接受布尔值,默认为True。
通过groupby()方法执行分组操作,会返回一个GroupBy对象,该对象实际上并没有进行任何计算,只是包含一些关于分组键的中间数据而已。一般,使用Series调用groupby()方法返回的是SeriesGroupBy对象,而使用DataFrame调用groupby()方法返回的是DataFrameBy对象。
在进行分组时,可以通过groupby()方法的by参数来指定按什么标准分组,by参数可以接收的数据有多种形式,类型也不必相同,常用的分组方式主要有以下4种:
- 列表或数组,其长度必须与待分组的轴一样。
- DataFrame对象中某列的名称。
- 字典或Series对象,给出待分组轴上的值与分组名称之间的对应关系。
- 函数,用于处理轴索引或索引中的各个标签。
接下来通过代码来演示:
例子1通过列名进行分组:
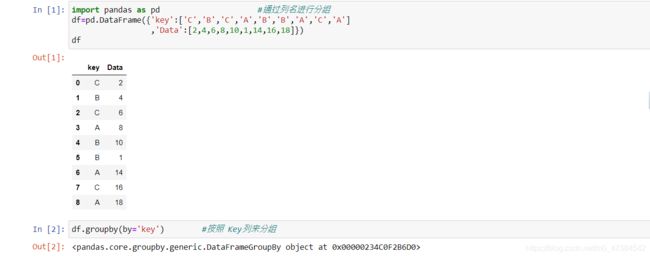
import pandas as pd #通过列名进行分组
df=pd.DataFrame({'key':['C','B','C','A','B','B','A','C','A']
,'Data':[2,4,6,8,10,1,14,16,18]})
df
df.groupby(by='key') #按照 Key列来分组
#要查看每个分组的具体内容,要用for遍历DataFrameGroupBy对象
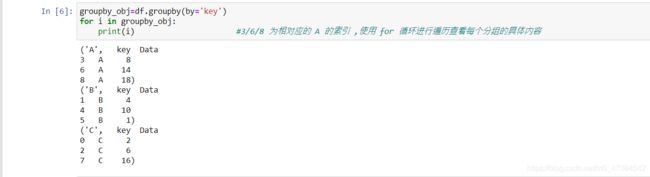
groupby_obj=df.groupby(by='key')
for i in groupby_obj:
print(i) #3/6/8 为相对应的 A 的索引 ,使用 for 循环进行遍历查看每个分组的具体内容
例子2通过Series对象进行分组:
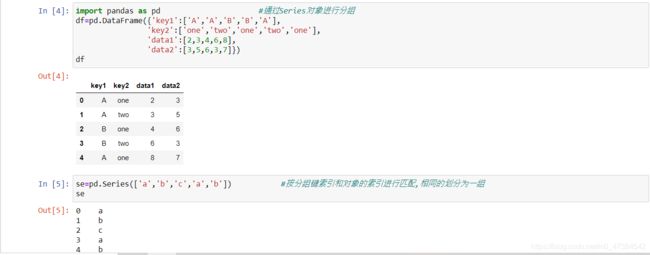
import pandas as pd #通过Series对象进行分组
df=pd.DataFrame({'key1':['A','A','B','B','A'],
'key2':['one','two','one','two','one'],
'data1':[2,3,4,6,8],
'data2':[3,5,6,3,7]})
df
se=pd.Series(['a','b','c','a','b']) #按分组键索引和对象的索引进行匹配,相同的划分为一组
se

group_obj=df.groupby(by=se)
for i in group_obj:
print(i)
如果Series对象的长度与原数据的行索引长度不相等时:
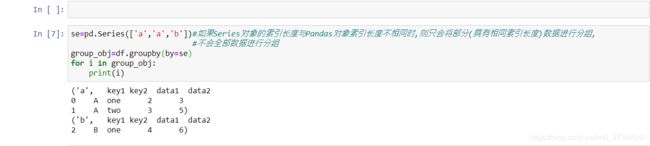
se=pd.Series(['a','a','b'])#如果Series对象的索引长度与Pandas对象索引长度不相同时,则只会将部分(具有相同索引长度)数据进行分组,
#不会全部数据进行分组
group_obj=df.groupby(by=se)
for i in group_obj:
print(i)
例子3通过字典进行分组:
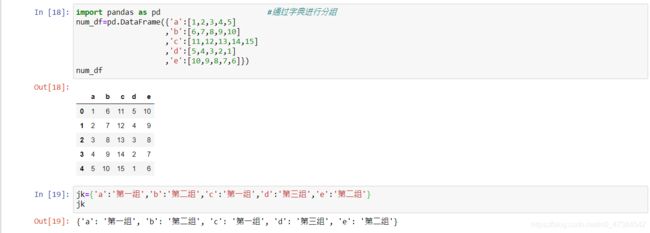
import pandas as pd #通过字典进行分组
num_df=pd.DataFrame({'a':[1,2,3,4,5]
,'b':[6,7,8,9,10]
,'c':[11,12,13,14,15]
,'d':[5,4,3,2,1]
,'e':[10,9,8,7,6]})
num_df
jk={'a':'第一组','b':'第二组','c':'第一组','d':'第三组','e':'第二组'}
jk
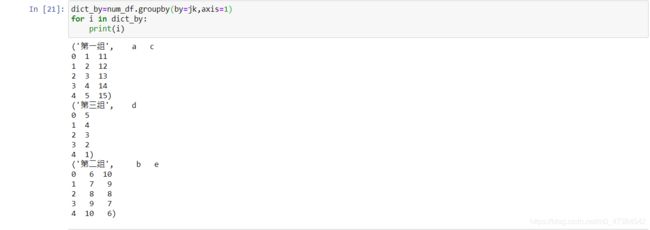
dict_by=num_df.groupby(by=jk,axis=1)
for i in dict_by:
print(i)
例子4通过函数进行分组:

import pandas as pd #通过函数进行分组
df=pd.DataFrame({'a':[1,2,3,4,5]
,'b':[6,7,8,9,10]
,'c':[5,4,3,2,1]},index=['Sun','Jack','Alice','Helen','Job'])
df
group_obj=df.groupby(by=len) #调用了内置函数 len方法
for i in group_obj:
print(i)
例子5 as_index参数的用法:
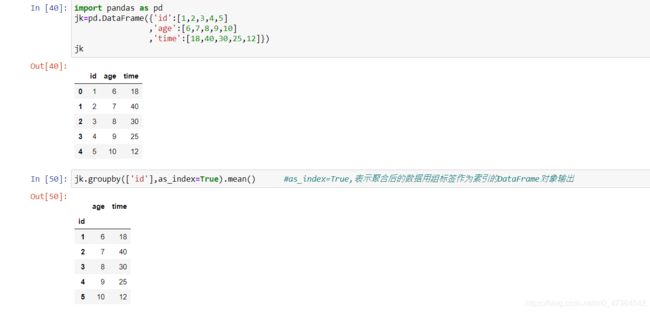
import pandas as pd
jk=pd.DataFrame({'id':[1,2,3,4,5]
,'age':[6,7,8,9,10]
,'time':[18,40,30,25,12]})
jk
jk.groupby(['id'],as_index=True).mean() #as_index=True,表示聚合后的数据用组标签作为索引的DataFrame对象输出
#as_index=True
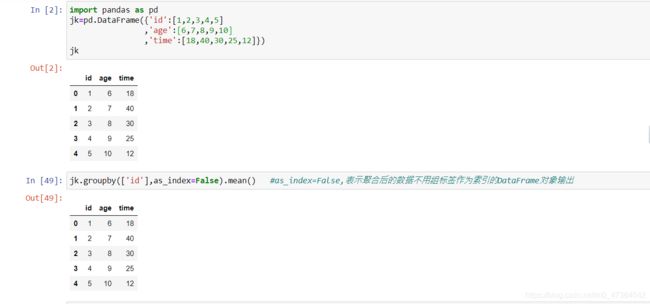
import pandas as pd
jk=pd.DataFrame({'id':[1,2,3,4,5]
,'age':[6,7,8,9,10]
,'time':[18,40,30,25,12]})
jk
jk.groupby(['id'],as_index=False).mean() #as_index=False,表示聚合后的数据不用组标签作为索引的DataFrame对象输出
#as_index=False
作者:KJ.JK
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。
文章对你有所帮助的话,欢迎给个赞或者 star 呀,你的支持是对作者最大的鼓励,不足之处可以在评论区多多指正,交流学习呀