agg 方法将一个函数使用在一个数列上,然后返回一个标量的值。也就是说agg每次传入的是一列数据,对其聚合后返回标量。
对一列使用三个函数:
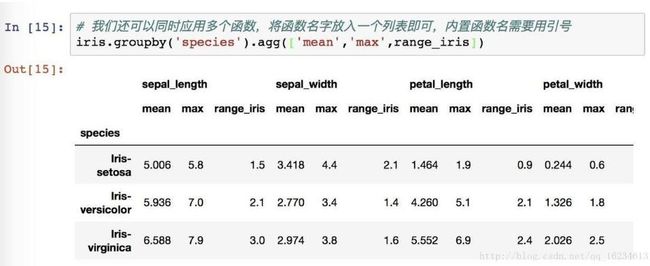
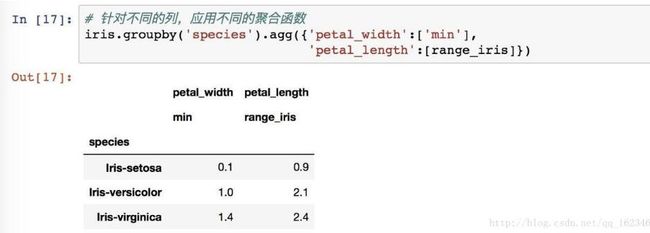
对不同列使用不同函数
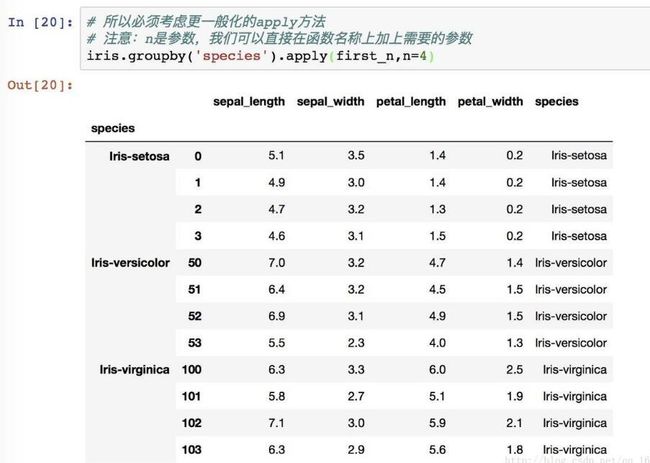
apply 是一个更一般化的方法:将一个数据分拆-应用-汇总。而apply会将当前分组后的数据一起传入,可以返回多维数据。
实例:
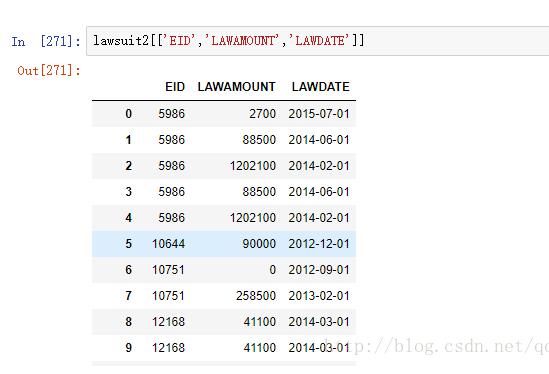
1、数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']]
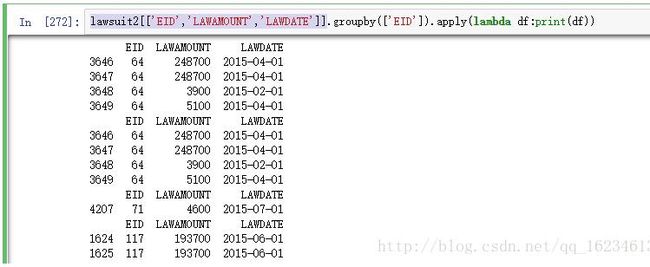
2、groupby后应用apply传入函数数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(lambda df:print(df))
3、如果使用agg,对于两列可以处理,但对于上面的三列,打印数据如下:
lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).agg(lambda df:print(df))
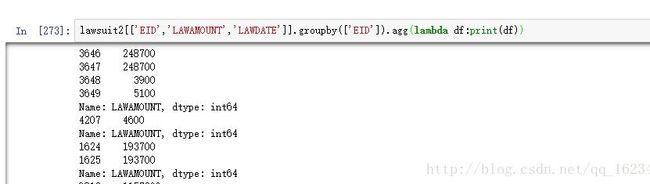
可以看到agg传入的只有一列数据,如果我们使用df加列下表强行取值也能取到,但是有时会出现各种keyError问题。
4、完整代码:
判断最近一次日期的花费是否是所有的花费中最大花费。
def handle(df):
# print(df)
# 找最大日期
maxdate = df['LAWDATE'].max()
# 找最大费用
left = df[ df['LAWDATE']==maxdate ]['LAWAMOUNT'].max()
# 取ID
EID = df['EID'].values[0]
# print(EID)
# 从已存在的表中根据EID找到最大费用
right = LAW_AMOUNT_MAX.loc[EID,'LAW_AMOUNT_MAX']
# 判断费用是否相等
if left==right:
return 1
else:
return 0
LAW_AMOUNT_MAX_IS_LAST = lawsuit2[['EID','LAWAMOUNT','LAWDATE']].groupby(['EID']).apply(handle)
其他注意点:
在groupby后使用apply,如果直接返回,会出现有多余的groupby索引问题,可以使用group_keys解决:
orgin = reviews_df.sort_values(["reviewerID","unixReviewTime"]).groupby("reviewerID",group_keys=False)
train = orgin.apply(lambda df: df[:-2])
train.head()
补充:pandas分组聚合运算groupby之agg,apply,transform
groupby函数是pandas中用以分组的函数,可以通过指定列来进行分组,并返回一个GroupBy对象。对于GroupBy对象的聚合运算,其有经过优化的较为常用的sum,mean等函数,但是如果我们需要用自定义的函数进行聚合运算,那么就需要通过agg,apply,transform来实现。
agg,apply和transform三者之间的区别在于:1、agg和transform之间的区别为:前者经过聚合后,只会在该组单列中返回一个标量值,而transform则会将该标量值在该组单列内进行广播,保持原DataFrame的索引不变;2、agg和transform中的函数参数是以分组后的单列(Series)为操作对象的,即传入agg和transform的函数的参数是列,而apply中的函数参数是分组后整个的DataFrame。下面分别对这两点进行说明。
一、agg和transform
如下代码所示,构造一个df,agg和transform中lambda函数的input都为单列,但是agg返回的索引是分组的key的唯一值,而transform返回的索引和原df一样,但是相比于agg返回的结果,发现transform只是在d行处的值进行了重复的广播,这个目的就是维持原df的索引不变,且被拿来分组的列会被剔除。
df
Out[1]:
index a b c
0 d 0 1 2
1 d 3 4 5
2 e 6 7 8
df.groupby(by='index').agg(lambda x:x.shape)
Out[2]:
a b c
index
d (2,) (2,) (2,)
e (1,) (1,) (1,)
df.groupby(by='index').transform(lambda x:x.shape)
Out[3]:
a b c
0 (2,) (2,) (2,)
1 (2,) (2,) (2,)
2 (1,) (1,) (1,)
二、agg和apply
下面的是apply的结果,相比于上面agg的结果,可以发现,实际上lambda函数的input不再是一个Series,而是分组后的整个DataFrame。
dd.groupby(by='index').apply(lambda x:x.shape) Out[4]: index d (2, 4) e (1, 4)
三、其他注意点
对于agg函数,其不仅可以传入一个函数对每列执行相同的操作,还可以传入一个字典{'col_name':func},来对不同的列做不同的操作,也可以将func替换为由多个不同的函数组成的list,实现对同一列做多个不同的操作,这是agg函数最为灵活的地方。
这三个函数,参数形式都为(func, *args,**kwargs),所以可以通过位置参数和关键字参数给func传递额外的参数。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。