机器学习之决策树(手推公式版)
文章目录
-
- 前言
- 1. 分类树
- 2. 划分标准
-
- 2.1 信息增益
- 2.2 增益率
- 2.3 基尼系数
- 3. 剪枝策略
-
- 3.1 预剪枝
- 3.2 后剪枝
- 4. 模型实现
- 结束语
前言
决策树 ( D e c i s i o n (Decision (Decision T r e e ) Tree) Tree)是一类常用的机器学习算法,也是处理分类问题的最基本的算法之一,属于监督学习。在分类问题中,决策树算法通过样本中某一特征的值,将样本划分到不同的类别中。
1. 分类树
决策树是基于树形结构来进行决策的,叶结点就是分类的结果,而其余结点是一个特征,多说无益,来看个例子:
| 编号 | 是否用腮呼吸 | 有无鱼鳍 | 是否为鱼 | |
|---|---|---|---|---|
| 鲨鱼 | 1 | 是 | 有 | 是 |
| 鲫鱼 | 2 | 是 | 有 | 是 |
| 河蚌 | 3 | 是 | 无 | 否 |
| 鲸鱼 | 4 | 否 | 有 | 否 |
| 海豚 | 5 | 否 | 有 | 否 |
这个数据集有五个样本,两个特征,可以这样构造一棵决策树:
(1)先选择是否用腮呼吸这个特征:

(2)在上次的决策结果基础之上,再选择有无鱼鳍这个特征:
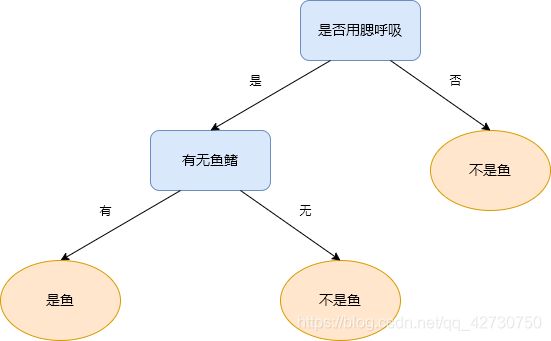
(3)对于新样本鲸鲨:{用腮呼吸,有鱼鳍},可以知道,鲸鲨是鱼。
2. 划分标准
想必有一个疑问已经产生了:能不能先选择有无鱼鳍这个特征呢?答案当然是可以的啦!构成的决策树如下:
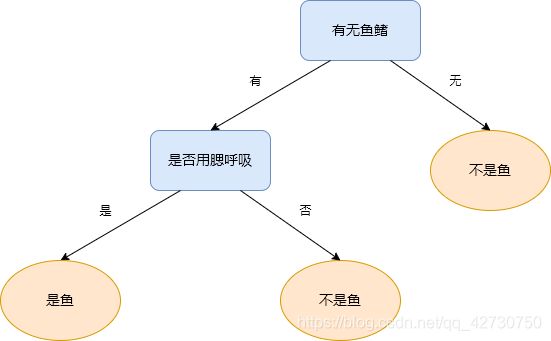
可以看到,构造的决策树略有不同,但对于样本鲸鲨:{用腮呼吸,有鱼鳍}的分类结果是相同的,也是正确的。那如果特征再增多一些,决策树的模型会受特征选择的影响呈现多样化,分类效果也有所不同,那如何选择特征来训练得到一棵最优的决策树呢?我们希望结点所包含的样本尽可能地属于同一个类别,即希望结点的纯度(purity)较高。
划分的终止条件:
(1)结点中样本数小于给定阈值;
(2)样本集中的基尼系数小于给定阈值(样本基本属于同一类别了);
(3)没有更多的特征了。
信息熵 ( I n f o r m a t i o n (Information (Information E n t r o p y ) Entropy) Entropy)是度量样本集合纯度最常用的一种指标。假设当前样本集合 D D D中第 k k k类样本所占比例为 p k ( k = 1 , 2 , … , m ) p_k(k=1,2,\dots,m) pk(k=1,2,…,m),则 D D D的信息熵定义为 E n t r o p y ( D ) = − ∑ k = 1 m p k log 2 p k Entropy(D)=-\sum _{k=1}^mp_k\log _2p_k Entropy(D)=−k=1∑mpklog2pk 其中, E n t r o p y ( D ) Entropy(D) Entropy(D)越小, D D D的纯度越高。(也可以理解为,信息熵反映的是数据集中的不纯度)
计算信息熵时约定: p = 0 p=0 p=0,则 p log 2 p = 0 p\log_2p=0 plog2p=0, E n t r o p y ( D ) Entropy(D) Entropy(D)的最小值为0,最大值为 l o g 2 m log_2m log2m(等概率时)。
对于上表中的数据,该数据集中有两个类别,即是鱼和不是鱼,所以 k = 2 k=2 k=2,由此可以计算该数据集的信息熵: E n t r o p y ( D ) = − ∑ k = 1 2 p k log 2 p k = − ( 2 5 log 2 2 5 + 3 5 log 2 3 5 ) = 0.9710 Entropy(D)=-\sum _{k=1}^2p_k\log _2p_k=-\bigg(\frac {2} {5}\log_2 \frac {2} {5}+\frac {3} {5}\log_2 \frac {3} {5}\bigg)=0.9710 Entropy(D)=−k=1∑2pklog2pk=−(52log252+53log253)=0.9710
2.1 信息增益
信息增益 ( I n f o r m a t i o n (Information (Information G a i n ) Gain) Gain),即信息熵的减少量。
假设特征 a a a有 N N N个可能的取值 { a 1 , a 2 , … , a N } \{a_1,a_2,\dots,a_N\} { a1,a2,…,aN},若使用特征 a a a来对样本集 D D D进行数据划分,则会产生 N N N个分支结点,其中第 n n n个分支结点包含了样本集 D D D中所有在特征 a a a上取值为 a n a_n an的样本,记为 D n D_n Dn。此时,样本集 D D D的信息熵就是以特征 a a a划分后的 N N N个样本信息熵的加权和。
n e w E n t r o p y ( D ) = ∑ n = 1 N ∣ D n ∣ ∣ D ∣ E n t r o p y ( D n ) newEntropy(D)=\sum _{n=1}^N\frac {|D_n|} {|D|} Entropy(D_n) newEntropy(D)=n=1∑N∣D∣∣Dn∣Entropy(Dn) 那么以特征 a a a对样本集 D D D进行划分所获得的信息增益为 G a i n ( D , a ) = E n t r o p y ( D ) − n e w E n t r o p y ( D ) = E n t r o p y ( D ) − ∑ n = 1 N ∣ D n ∣ ∣ D ∣ E n t r o p y ( D n ) Gain(D,a)=Entropy(D)-newEntropy(D)=Entropy(D)-\sum _{n=1}^N\frac {|D_n|} {|D|} Entropy(D_n) Gain(D,a)=Entropy(D)−newEntropy(D)=Entropy(D)−n=1∑N∣D∣∣Dn∣Entropy(Dn) 一般而言,信息增益越大,即以某特征划分样本后信息熵减少了,也就是说不纯度降低了,说白了就是纯度提升了。
I D 3 ID3 ID3决策树学习算法就是以信息增益为准则来选择划分特征的。
OK,我们使用信息增益来计算一下上述两种特征划分后的结果:

2.2 增益率
倘若我们把“编号”也作为一个划分的特征,则根据公式可以计算出它的信息增益为0.971,这远大于其他特征划分的结果。这很容易理解,“编号”这一特征将产生5个分支,每个分支结点仅包含一个样本,每个分支结点的纯度已达到最大。然而,这样的决策树并不具有泛化能力,无法对新样本进行有效预测。
所谓
泛化能力,就是处理未见数据的能力。

实际上,信息增益这一策略对取值数目较多的特征有所偏好,比如上述的特征“编号”,有5个取值,所以它的信息增益很大,为减少这种偏好可能带来的不利影响,引入了增益率(Gain Ratio)这一策略,其定义如下: G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) ∑ n = 1 N ∣ D n ∣ ∣ D ∣ log 2 ∣ D n ∣ ∣ D ∣ Gain\_ratio(D,a)=\frac {Gain(D,a)} {\sum _{n=1}^N \frac {|D_n|} {|D|} \log_2\frac {|D_n|} {|D|}} Gain_ratio(D,a)=∑n=1N∣D∣∣Dn∣log2∣D∣∣Dn∣Gain(D,a) 分母称为特征 a a a的固有值,特征 a a a的取值数目越多,即 N N N越大,则分母的值也就会越大。但由此又会出现另一个状况,即增益率对取值数目较少的特征会有所偏好。
C 4.5 C4.5 C4.5决策树学习算法就是以增益率为准则来选择划分特征的。但不是直接选择增益率最大的候选划分特征,而是使用了一个另一种策略:先从候选划分特征中找出信息增益高于平均水平的特征,再从中选择增益率最高的那个。
2.3 基尼系数
基尼系数 ( G i n i (Gini (Gini I n d e x ) Index) Index)也可以度量数据集的纯度,其定义如下: G i n i ( D ) = ∑ k = 1 m ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 m p k 2 Gini(D)=\sum_{k=1}^m\sum_{k^{'}\neq k} p_kp^{\prime}_k=1-\sum_{k=1}^mp^2_k Gini(D)=k=1∑mk′=k∑pkpk′=1−k=1∑mpk2 可以知道,基尼系数反映的是从数据集中随机抽取两个样本,其类别不一致的概率。因此,基尼系数越小,其数据集的纯度越高。
特征 a a a的基尼系数定义如下: G i n i _ i n d e x ( D , a ) = ∑ n = 1 N ∣ D n ∣ ∣ D ∣ G i n i ( D n ) Gini\_index(D,a)=\sum_{n=1}^N \frac {|D_n|} {|D|} Gini(D_n) Gini_index(D,a)=n=1∑N∣D∣∣Dn∣Gini(Dn)
C A R T ( C l a s s i f i c a t i o n CART(Classification CART(Classification a n d and and R e g r e s s i o n Regression Regression T r e e ) Tree) Tree)决策树就是以基尼系数为准则来选择划分特征的。
3. 剪枝策略
剪枝 ( P r u n i n g ) (Pruning) (Pruning)是一种控制模型复杂度的非常有效和必要的手段,用来解决决策树中出现的过拟合问题。决策树剪枝的基本策略有预剪枝 ( p r e − p r u n i n g ) (pre-pruning) (pre−pruning)和后剪枝 ( p o s t − p r u n i n g ) (post-pruning) (post−pruning)两种。
过拟合:即模型的学习能力过于强大,以至于把训练样本中所包含的不太一般的特性(甚至是噪声)都学到了,导致在训练集上正确率很高,在测试集上正确率很低。常用解决过拟合问题的措施有:增加数据量、正则化等等。
欠拟合:即模型的学习能力很差,训练样本中的一般特征都没有学习到,结果就是在训练集上正确率很低,在测试集上正确率也很低。常用解决过拟合问题的措施有:增加训练次数、增加神经网络层数等等。
3.1 预剪枝
预剪枝是指在当前决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能的提升,则停止划分,并将当前结点标记为叶结点。
由此可以看出,预剪枝使得决策树的很多分支都没有展开,因此可以有效降低过拟合的风险,而且还可以减少决策树的训练时间。但也不得不说,有些分支虽然在当前划分不能提升泛化性能,甚至导致泛化性能下降,但在其基础之上进行的后续划分却有可能使模型的泛化性能显著提高,而且许多分支并未展开,也存在欠拟合的风险。
3.2 后剪枝
后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点后,能给决策树的泛化性能带来提升,则将该子树替换为叶结点。
后剪枝策略相对来说欠拟合的风险很小,泛化性能往往优于预剪枝的决策树,但由于后剪枝是在生成决策树之后进行的,而且要自底向上对树中所有非叶结点进行逐一考察,所以其训练时间开销比预剪枝和未剪枝决策树都要大得多。
对于
“替换后的叶结点正确率与替换前的正确率相同”这种情况要不要剪枝呢?答案是要滴,根据奥卡姆剃刀准则,剪枝后的模型更为简洁,即剪枝后的模型会更好,所以出现这种情况也是要剪枝的。
奥卡姆剃刀 ( O c c a m ′ s (Occam's (Occam′s R a z o r ) Razor) Razor)是一种常用的、自然科学研究中最基本的原则,即“若有多个假设与观察一致,则选择最简单的那个”
说白了就是优先选择最简单的那个呗!

4. 模型实现
这里使用sklearn.tree里的DecisionTreeClassifier进行决策树建模来解决分类问题,数据集为sklearn自带的酒数据集winedata,数据集详情大致如下:
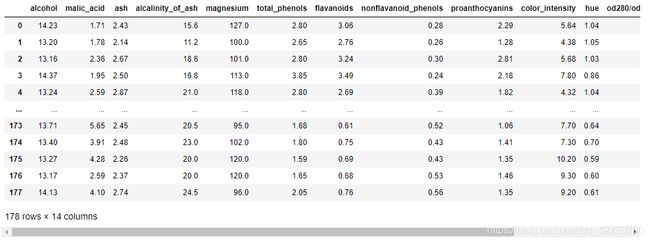

该数据集有13个特征,3个类别,详情可打印
winedata.DESCR
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import pandas as pd
import graphviz
winedata = load_wine()
x_train, x_test, y_train, y_test = train_test_split(winedata.data, winedata.target,
test_size=0.3, random_state=1024)
# criterion: 可选择划分策略: entropy(信息增益)和gini(基尼系数), 默认为gini
# random_state 每次分割时, 特征总是随机排列的, 即使splitter设为best, 如果对几个分割的标准是相同的, 必须随机选择一个特征分割
# splitter: 用于在每个节点上选择拆分的策略 支持的策略是"best"选择最佳拆分, "random"选择最佳随机拆分, 默认是best
# max_depth: 树的最大深度 如果为None, 则将节点展开, 直到所有叶子都是纯净的; 或者直到所有叶子都包含少于min_samples_split个样本, 一般从3开始尝试
# min_samples_split: 当前结点的最少样本数量, 否则不再进行拆分, 默认为2
# min_samples_leaf: 拆分后的结点至少含有的样本数量, 否则当前结点不再进行拆分, 默认为1
model = DecisionTreeClassifier(criterion='gini', random_state=1024, splitter='best',
max_depth=3, min_samples_split=2, min_samples_leaf=5)
model.fit(x_train, y_train)
# 精确度accuracy
score = model.score(x_test, y_test)
# 决策树不设置random_state
# 多次测试可获得0.9074的正确率
print('score: ', score)
# # 交叉验证
# model = DecisionTreeClassifier(criterion='gini', random_state=1024, splitter='best',
# max_depth=3, min_samples_split=2, min_samples_leaf=5)
# cvs_score = cross_val_score(model, winedata.data, winedata.target, cv=10)
# # cvs_score_max: 1.0, cvs_score_mean: 0.8718954248366014
# print('cvs_score_max: {0}, cvs_score_mean: {1}'.format(max(cvs_score), cvs_score.mean()))
# 导出决策树
export_graph = tree.export_graphviz(decision_tree=model, feature_names=winedata.feature_names,
class_names=winedata.target_names, filled=True, rounded=True)
graph = graphviz.Source(export_graph)
# graph.view()
graph.render(filename='graph', format='png')

# 简单参数调试
# 以max_depth为例, 可以看到max_depth为3时模型最优
score_list = []
for i in range(10):
model = DecisionTreeClassifier(criterion='gini', max_depth=i + 1, random_state=1024)
model.fit(x_train, y_train)
# 精确度accuracy
score = model.score(x_test, y_test)
score_list.append(score)
plt.plot(range(1, 11), score_list, color='red', label='max_depth')
plt.xticks(range(1, 11))
plt.legend()
plt.show()

决策树的参数选择稍微有些多,需要根据不同的数据集进行选择相应的划分策略以及剪枝策略,有关
DecisionTreeClassifier的详细参数说明可参考官方手册。
交叉验证法 ( C r o s s (Cross (Cross V a l i d a t i o n ) Validation) Validation)就是先将数据集 D D D划分为 k k k个大小相似的互斥子集,即 D = D 1 ∪ D 2 ∪ ⋯ ∪ D k , D i ∩ D j = ∅ D=D_1 \cup D_2 \cup \dots \cup D_k,D_i \cap D_j = \varnothing D=D1∪D2∪⋯∪Dk,Di∩Dj=∅,每个子集 D i D_i Di都尽可能保持数据分布的一致性,即从 D D D中通过分层采样得到。然后,每次用 k − 1 k-1 k−1个子集作为训练集来训练模型,余下那个用作为测试集,这样就可以进行 k k k次训练和测试,最终返回这 k k k次测试结果的均值。
交叉验证又称为 k k k折交叉验证 ( k − f o l d (k-fold (k−fold c r o s s cross cross v a l i d a t i o n ) validation) validation), k k k通常取值是10。
结束语
持续充电中,博客内容也在不断更新补充中,如有错误,欢迎来私戳小编哦!共同进步,感谢Thanks♪(・ω・)ノ
