HTTPRUNNER快速入门
安装httprunner见文章 安装httprunner
目录
创建HTTPRUNNER项目
使用pyacharm打开项目
获取har文件,并转换未yaml文件
执行yaml文件
查看结果:
查看测试报告
结合locust进行页面性能测试
安装locus
检验安装是否成功
执行命令
点击Start swarming,开始压测
生成图表
附件一 安装allure
附件二 高价(参数化)
使用CSV文本进行参数化
使用自定义函数进行参数化
创建HTTPRUNNER项目
# 使用
httprunner startproject demohttp
# 只有有hrun方式的,我失败了,按理hrun是缩写可以
# 还有hrun --startproject demohttp 这个查询了我使用的是3.X版本的貌似不需要--生成的目录文件为:

使用pyacharm打开项目

如果发现导入httprunner异常,检查安装httprunner安装情况以及到pyacharm的setting查看一下

获取har文件,并转换未yaml文件
见文章 通过Fiddler抓包获取har文件
这里建议将har放到har目录

转化之后为:

将生成的yaml文件复制到testcases目录下

执行yaml文件
在pycharm的terminal窗口执行,会自动生成一个.py文件,这个文件也可单独执行
hrun testcases/login.yml --log-level debug
# --log-level debug 日志级别
# --log-level info
查看结果:

查看测试报告
#方式一:HTML 测试报告
#httprunner 安装之后自带 pytest-html 插件,当你想生成 HTML测试报告时,可以添加命令参数--html
hrun testcases/login.yml --html=reports\report.html
# 或者hrun testcases/login.py --html=reports\report.html
# 方式二:allure report 主要看下文附件一安装allure
hrun testcases/ --alluredir=reports/ --clean-alluredir
# 建议使用pytest运行,因为在3.14版本中使用hrun命令存在bug不能在报告中查看日志
pytest testcases/ --alluredir=reports/ --clean-alluredir
allure serve reports
# 这里会自动弹出浏览器,360浏览器注意使用极速模式allure报告效果图

结合locust进行页面性能测试
安装locus
# pip install locustio 这个基本歇菜 安装不了
# 解决方案是:就是安装最新(发布前)的locust
pip install -U setuptools
pip install -U --pre locustio检验安装是否成功
locust -V
执行命令
locusts -f testcases/login.yml
# 运行命令:locusts -f 文件路径 --processes
# (在 Locust 中需使用多核处理器的能力,--processes 参数,可以一次性启动 1 个 master 和多个salve。若在 --processes 参数后没有指定具体的数值,则启动的 slave 个数与机器的 CPU 核数相同。在浏览器当中访问 http://localhost:8089/

Number of users to simulate:并发用户数
Hatch rate (users spawned/second):每秒产生用户数
Host : 主机地址
点击Start swarming,开始压测

参数说明

生成图表

附件一 安装allure
pip3 install allure-pytest
pip3 install "httprunner[allure]"一旦allure-pytest 准备好,以下参数就可以与 hrun/pytest命令一起使用:
| 命令 | 功能描述 |
|---|---|
| --alluredir=DIR | 生成 allure 报告到指定目录 |
| --clean-alluredir | 如果指定目录已存在则清理该文件夹 |
| --allure-no-capture | 不要将 pytest 捕获的日志记录(logging)、标准输出(stdout)、标准错误(stderr)附加到报告中 |
要使 allure 侦听器能够在测试执行期间收集结果,只需添加--alluredir选项,并提供指向存储结果的文件夹路径。
附件二 高价(参数化)
转自 网络 3.X有部分修改,见下图红色注意部分
无论在日常接口测试,还是性能测试,都对数据有要求,特别是性能测试,需要大量数据,这个时候就需要对传递的参数进行参数化了。
httprunner中支持的参数化方法有:csv文本、自定义函数
使用CSV文本进行参数化
在脚本同级目录下新建csv文件,打开存入需要的数据,保存

引用: 增加一个parameters参数,通过调用${P(***.csv)}方法来读取csv文本中的数据,也是使用$+变量名引用参数。
值得注意的是,通常来说,一个CSV文件中会放多列数值,那么这个时候,各列参数通过“-”连接来读取参数,如:要传postid1、name两列参数,这样写就可以postid1-name: ${P(postid.csv)}
下图新版3.X不支持在用例step当中配置,一般配置在config,下图当中的参数要修正下图格式,因为是截图,就不修正了(这是自己实际操作当中发现的坑)
config: # 3.X csv要在这里
name: test kuaidi100 api
parameters:
postid1: ${P(postid.csv)} # 一个参数没有 -yml格式用例既可以使用相对路径,也可以用绝对路径 pytest建议用绝对路径,相对路径可能会报错
(注意参数配置方式,见上面的修正)

运行提示:
“Ran 4 tests in 2.076s”,good。因为csv中有4个参数,用例也运行了4遍,查看log,4个参数都是csv里面的,而且是顺序的。
使用自定义函数进行参数化
还是在脚本下,新建debugtalk.py文件,注意,这个文件名字就不能随便取啦,固定的

代码:
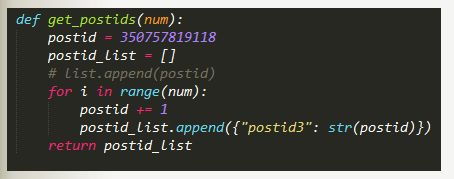

与csv引用类似,脚本中使用${get_postids(5)}来引用函数,5表示想要获取的参数个数
请参考官方中文教程网站:http://cn.httprunner.org/ 源码挪步:https://github.com/httprunner/httprunner