爬取饿了么平台上的门店信息
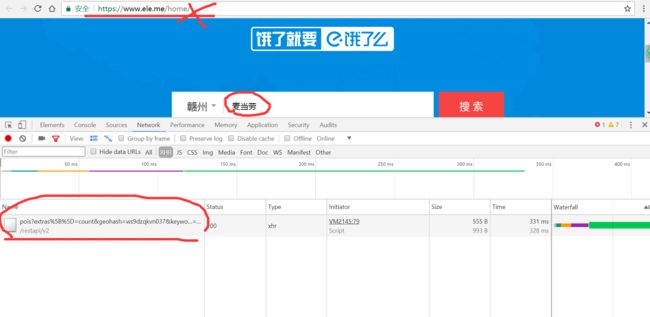
image.png
大的网站往往都喜欢使用动态网页,我们在网址栏看到的是
https://www.ele.me/home/
但实际上,真正的url是这个东西
https://www.ele.me/restapi/v2/pois?extras%5B%5D=count&geohash=ws9dzqkvn037&keyword=%E9%BA%A6%E5%BD%93%E5%8A%B3&limit=20&type=nearby
学过后台的就知道这是怎么一回事,通过路由的重定向。
采用json格式。json类似于字典,只要有知道key,就能获得key的value,不用搞什么网页解析,不用搞太多beautifulsoup和re的各种操作。数据很干净,不用我们解析,稍微使用点手段就能用。
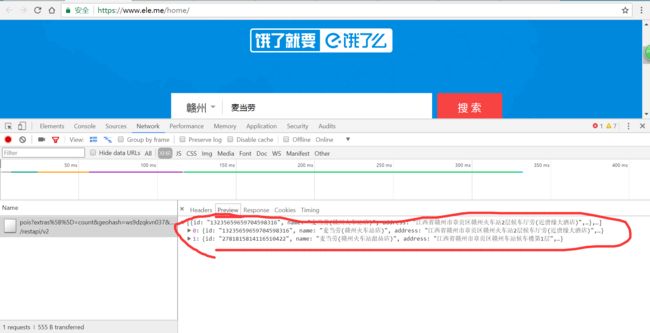
image.png
分析url
进行多次抓包比较,url中的关键词构造

image.png
keyword应该是麦当劳
limit不用变,
默认 type不用变,
默认 geohash看英文是地理geo的哈希值,
值是将城市的经纬度经过geohash转化为一个hash值。
那么我们先安装上geohash库。这里有一个小问题,就是我们安装了geohash这个库之后,我们导入这个库,会报错,告诉我们,还是找不到geohash这个库
解决办法:在python35/Lib/site-packages/目录下,把Geohash文件夹重命名为geohash,然后修改该目录下的init.py文件,把from geohash改为from .geohash
tip:经纬度可以使用百度地图api
代码生成geohash
#生成geohash值
def generate_geohash(lati,longi):
"""
longi: 经度
lati: 维度
"""
import geohash
geo_hash = geohash.encode(longi,lati)
return geo_hash
#江西省 赣州 北纬28.52 东经114.56
generate_geohash(28.52,114.56)
print(generate_geohash(longi=28.52,lati=114.56))
构造url
#构造url成功
def generate_url(keyword,geo_hash):
from urllib.parse import quote
keyword = quote(keyword) #将关键词转化为这种%E9%BA%A6%E5%BD%93%E5%8A%B3数据
url = 'https://mainsite-restapi.ele.me/v2/pois'
data = {'extras[]':'count',
'geohash': geo_hash,
'keyword':keyword,
'limit':'20',
'type':'nearby'
}
resp = requests.get(url,params=data)
print(resp.url)
获取门店信息
def get_infos(keyword, geo_hash):
url = 'https://mainsite-restapi.ele.me/v2/pois'
data = {'extras[]': 'count',
'geohash': geo_hash,
'keyword': keyword,
'limit': '20',
'type': 'nearby'}
resp = requests.get(url, params=data)
data = resp.json()
for d in data:
name = d.get('name')
print(name)
get_infos(keyword='麦当劳',geo_hash='ws9dzqkvn037')
当然,你不仅仅可以查询“麦当劳”,其他的也可以的。
扩展
读取各个城市的经纬度的txt文件
def read_citys():
container = [] # 收集城市坐标信息
import os, re, chardet
path = os.getcwd() + '\\citys.txt'
# 识别文件编码格式
with open(path, 'rb') as f:
result = chardet.detect(f.read())
Encoding = result['encoding']
# 读取citys.txt的数据
rawdata = open(path, 'r', encoding=Encoding).readlines()
for rw in rawdata:
lati_longi = re.compile(r'北纬(.*?) 东经(.*?)\n').findall(rw)
if lati_longi:
container.append(lati_longi[0])
return container
数据保存
def data_save(keyword):
import os
import csv
path = os.getcwd()+'/{name}.csv'.format(name=keyword)
csvfile = open(path,'w',encoding='utf-8',newline='')
writer = csv.writer(csvfile)
writer.writerow(('id','name','address','city'))
return writer
批量爬取
def Get_All(keyword):
citys = read_citys()
for city in citys:
city_hash = generate_geohash(lati=city[0],longi=city[1])