本文由尚妆前端开发工程师欲休撰写
本文发表于尚妆博客
需求背景
目前node端的服务逐渐成熟,在不少公司内部也开始承担业务处理或者视图渲染工作。不同于个人开发的简单服务器,企业级的node服务要求更为苛刻:
高稳定性、高可靠性、鲁棒性以及直观的监控和报警
想象下一个存在安全隐患且没有监控预警系统的node服务在生产环境下运行的场景,当某个node实例挂掉的情况下,运维人员或者对应开发维护人员无法立即知晓,直到客户或者测试人员报告bugs才开始解决问题。在这段无人处理的时间内,损失的订单数和用户的忠诚度和信任度将是以后无法弥补的,因此对于node程序的业务开发者而言,这就要求代码严谨、异常处理完备;对于node框架的维护者而言,则需要提供完善的监控预警系统。
功能
当一个服务进程在后端运行时(daemon),作为开发者我们关注的信息主要有以下几点:
- 服务进程是否正在运行,isalive
- 服务进程的内存使用率,是否存在未回收(释放)的内存
- 服务进程的cpu使用率,在计算量大的情况下是否需要分片处理、延时处理
- 服务进程的实时响应时间和吞吐量
而作为一个运维人员,关注的不仅仅是node服务进程的相关信息,还包括物理主机的使用状况:
- 物理硬盘所剩存储空间
- 内存、cpu使用率
- 网络接入是否正常
可以看出,不管是针对主机还是进程进行监控,我们的关注点大多数是资源使用率和业务量处理能力,因此我们的监控预警系统也着重实现这些功能。
系统简易架构
目前生产环境下的node服务大多采用多进程或者cluster模式,而且为了响应突发流量往往采用多机部署,因此监控和预警的目标实体就是多物理(虚拟)机下的多个子进程。
比如,目前node服务在单机上往往采用1+n的进程模型:所谓1,即1个主进程;n,表示n个工作进程,而且这些工作进程是从主进程上fork出来,同时根据经验,n的值往往等同于主机的cpu核心数,充分利用其并行能力。那么,采用该种进程模型的node服务部署在线上4台物理机上,我们需要监控的则是4xn个进程,这涉及到了分布式数据同步的问题,需要寻找一种方法实现高效、准确和简易的数据存和读,并且尽可能的保证这些数据的可靠性。
在这里,笔者采用了分布式数据一致系统ZooKeeper(下文简写为ZK)实现数据的存和读。之所以没有采用传统的数据库是由于读写表的性能,如为了防止多个进程同时写表造成冲突必须进行锁表等操作,而且读写硬盘的性能相对内存读写较低;之所以没有采用IPC+事件机制实现多进程通信,主要是由于node提供的IPC通信机制仅限于父子进程,对于不同主机的进程无法进行通信或者实现复杂度较高,因此也并未采用该种方式。
采用ZK来实现多节点下的数据同步,可在保证集群可靠性的基础上达到数据的最终一致性,对于监控系统而言,不需要时刻都精确的数据,因此数据的最终一致性完全满足系统的需求。ZK服务集群通过paxos算法实现选举,并采用ZK独特的算法实现数据在各个集群节点的同步,最终抽象为一个数据层。这样ZK客户端就可以通过访问ZK集群的任意一个服务节点获取或读写相同的数据,用通俗的语言来形容,就是ZK客户端看到的所有ZK服务节点都有相同的数据。
另外,ZK提供了一种临时节点,即ephemeral。该节点与客户端的会话session相绑定,一旦会话超时或者连接断开,该节点就会消失,并触发对应事件,因此利用该种特性可以设置node服务的isalive(是否存活)功能。不过,目前node社区针对ZK的客户端还不是很完善(主要是文档),笔者采用node-zookeeper-client模块并且针对所有接口promise化,这样在进行多级znode开发时更可读。
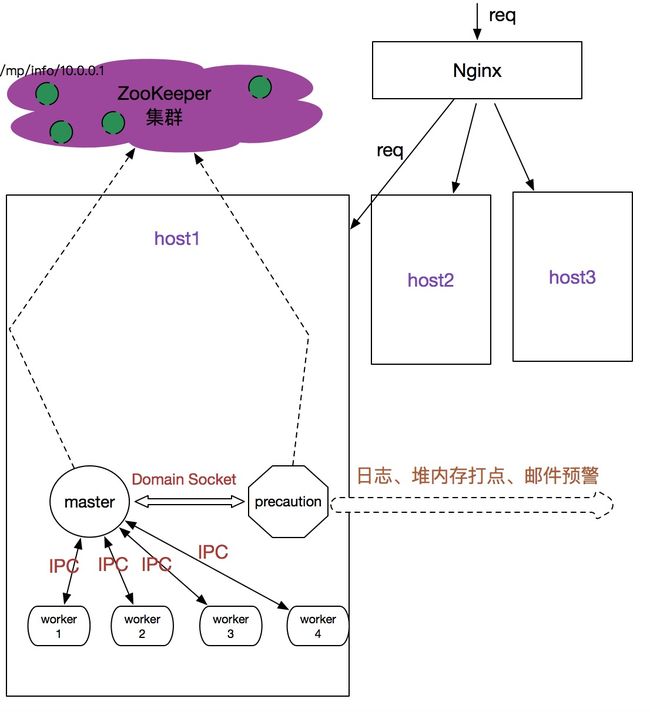
上图是笔者设计的监控预警系统的架构图,这里需要着重关注一下几点:
- ZooKeeper部署与znode节点使用
- 单机内部node进程的进程模型:1+n+1
- precaution进程的工作内容以及与master和worker的通信方式
下面着重详述以上几点。
ZooKeeper部署与编码细节
上节已提到,ZooKeeper抽象为一个数据一致层,它是由多个节点组成的存储集群,因此在具体的线上环境下,ZK集群是由多个线上主机搭建而成,所有的数据都是存储在内存中,每当对应工作进程的数据发生变化时则修改对应znode节点的数据,在具体实现中每个znode节点存储的是json数据,便于node端直接解析。
在具体的代码中,我们需要注意的是ZK客户端会话超时和网络断开重连的问题。默认,ZK客户端会帮助我们完成网络断开后重连过程的简历,而且在重新连接的过程中会携带上次断开连接的session id,这样在session未超时的前提下仍会绑定之前的数据;但是当session超时的情况下,对应session id的数据将会被清空,这就需要我们的自己处理这种情况,又称作现场恢复。其实,在监控系统中,由于需要实时查询对应节点数据,需要始终保持session,在设定session expire时间的情况下终究会出现ZK客户端会话超时的情况,因此需要我们实现现场恢复,需要注意。
进程模型
大多数开发者为了提高node程序的并行处理能力,往往采用一个主进程+多个工作进程的方式处理请求,这在不需要监控预警系统的前提下是可以满足要求的。但是,随着监控预警功能的加入,有很多人估计会把这些功能加入到主进程,这首先不说主进程工作职能的混乱,最主要的是额外增加了风险性(预警系统的职能之一就是打点堆快照,并提醒开发者。因此主进程内执行查询、打点系统资源、发送邮件等工作存在可能的风险)。因此为了主进程的功能单一性和可靠性,创建了一个precaution进程,该进程与主进程同级。
采用1+n+1模型并不会影响请求处理效率,工作进程的职能仍是处理请求,因此新的进程模型完全兼容之前的代码,需要做的就是在主进程和precaution进程执行的代码中添加业务部分代码。
通信方式
在监控预警系统中,需要实现precaution进程<-->master进程、master进程<-->worker进程、precaution进程<-->worker进程的双向通信,如打点内存,需要由precaution进程通知对应worker进程,worker进行打点完成后发送消息给precaution进程,precaution进行处理后发送邮件通知。
首先,worker与master的通信走的是node提供的IPC通道,需要注意的是IPC通道只能传输字符串和可结构化的对象。可结构化的对象可以用一个公式简易表述:
o = JSON.parse(JSON.stringify(o))
如RegExp的实例就不是可结构化对象。
其次,worker和precaution的通信是通过master作为桥梁实现的,因此其中的关节点就在于precaution与master的通信。
最后,precaution与master的通信采用domain socket机制实现,这两个进程是只是两个node实例而已,因此无法采用node提供的IPC机制,而进程间通信可以采用其他方法如:命名管道、共享内存、信号量和消息队列等,采用这些方法实现固然简单,但是缺点在于两个进程耦合度相对较高,如命名管道需要创建具体的管道文件并且对管道文件大小有限制。使用domain socket,最大的好处就是灵活制定通信协议,且易于扩展。
node的net模块提供了domain socket的通信方式,与网络服务器类似,采用domain通信的服务器侦听的不是端口而是sock文件,采用这种方式实现全双工通信。
业务量计算和数据打点
这里提到的业务量,指的是监控预警系统所关注的数据业务,如内存和cpu利用率、吞吐量(request per minute)和响应时间。其中,内存和cpu利用率可以通过linux下的相关命令如top来查询,响应时间和吞吐量则通过koa中间件实现粗略统计。不过为了方便开发者把精力集中到业务上去而非兼容底层操作系统,建议使用pidusage模块完成资源利用率的测量,而针对吞吐量笔者并未找到相关的工具进行测量,仅在中间件中粗略计算得出。
在precaution进程中,设置了两个阈值。一个是warning值,当使用内存大小超过了该值则进行日志打点,并开始周期性的node堆内存打点;另一个是danger值,超过该值则进行内存打点并发送邮件提醒,根据附件中的近三个快照分析内存。
总结
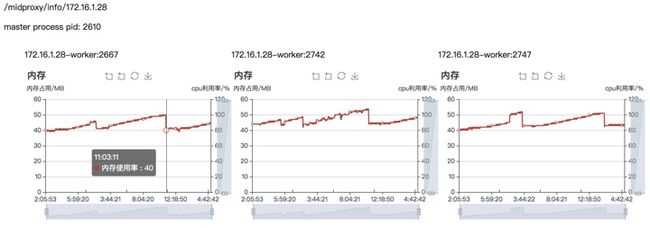
采用上述监控预警架构,可以有效的实现多节点下多进程的监控,在确保进程可靠性的基础上完成侵入性较小的、安全性较高的、可扩展性强的实现。以后不管是临时扩张主机节点还是更改子进程数量,都可以瞬时在UI界面上直观体现,如