一、数据合并、连接
首先导入模块,
import pandas as pd
1、concat:沿着一条轴,将多个对象堆叠到一起
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)
参数说明:
objs:需要连接的对象集合,Series | DataFrame objects;
axis:连接轴向,默认0,Y轴连接;
join:参数为‘outer’或‘inner’,默认是‘outer’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引, 默认None;
ignore_index=False:boolean, 默认False;重建索引:True。

code示例: 来源于pypandas
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
)
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
)
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
)
frames = [df1, df2, df3]
result = pd.concat(frames,ignore_index=True)
输出结果:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
8 A8 B8 C8 D8
9 A9 B9 C9 D9
10 A10 B10 C10 D10
11 A11 B11 C11 D11
2、merge:通过键拼接列
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
left和right:两个不同的DataFrame;
how:连接方式,‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。;
on:连接键,指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,
如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字如果和表合并的过程中遇到有一列两个表都同名,但是值不同,合并的时候又都想保留下来,就可以用suffixes给每个表的重复列名增加后缀。;
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况
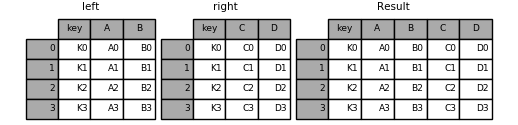
2.1 merge基本使用方法
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on='key')
print(result)
输出结果:
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
2.2 多连接键连接
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])

| Merge method | SQL Join Name | Description |
|---|---|---|
| left | LEFT OUTER JOIN | Use keys from left frame only |
| right | RIGHT OUTER JOIN | Use keys from right frame only |
| outer | FULL OUTER JOIN | Use union of keys from both frames |
| inner | INNER JOIN | Use intersection of keys from both frames |
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])

2.3 两个DataFrame的列同名,但是值不同,合并的时候又都想保留下来
result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])

2.4 indicator参数
merge接受参数指示符。
如果为True,则将名为_merge的Categorical类型列添加到具有值的输出对象:
指标参数也将接受字符串参数,在这种情况下,指标函数将使用传递的字符串的值作为指标列的名称。
| Observation Origin | _merge value |
|---|---|
| Merge key only in ‘left’ frame | left_only |
| Merge key only in ‘right’ frame | right_only |
| Merge key in | both frames |
df1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out:
col1 col_left col_right _merge
0 0.0 a NaN left_only
1 1.0 b 2.0 both
2 2.0 NaN 2.0 right_only
3 2.0 NaN 2.0 right_only
pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out:
col1 col_left col_right indicator_column
0 0.0 a NaN left_only
1 1.0 b 2.0 both
2 2.0 NaN 2.0 right_only
3 2.0 NaN 2.0 right_only