python学习 字符串与正则表达式详解1
python学习 字符串与正则表达式
- 背景知识
字符:数字、字母、字、符号等等都是字符,如8、H、h、国、&等
字符串:2是一个字符,s、c、h、o、o、l都是字符,现在我将这些字符连接起来,123pythonschool就是一个由15个字符组成的字符串 - 字符串常用操作
2.1拼接字符串
“+”,可以完成多个字符串的拼接
entext = 'I am busy coding.'
cntext = '正在码代码。'
print(entext + '---' + cntext)
I am busy coding.---正在码代码。
#字符串不允许直接和其他类型的数据拼接
str1 = '我今天一共走了'
num = 12345
str2 = '步'
print(str1 + str(num) + str2)
我今天一共走了12345步
2.2计算字符串的长度
首先需要了解各字符所占的字节数
①ASCII码中,一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间。一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制。最小值0,最大值255。
②UTF-8编码中,一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。
③Unicode编码中,一个英文等于两个字节,一个中文(含繁体)等于两个字节。
符号:英文标点占一个字节,中文标点占两个字节。举例:英文句号“.”占1个字节的大小,中文句号“。”占2个字节的大小。
④UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。
⑤UTF-32编码中,世界上任何字符的存储都需要4个字节。
- len()函数计算字符的长度
len(string)
str = '人生苦短,我用python!'
length = len(str)
print(length)
14
通过len()计算字符串的长度时,不区分英文中文数字,所有字符都认为是一个。
在实际开发时,有时需要获取字符串实际所占的字节数,即如果采用UTF-8编码,汉字占3个字节,
采用GBK或者GB2312时,汉字占2个字节.这时需要用encode()方法进行编码后再进行获取。
str = '人生苦短,我用python!'
length1 = len(str.encode('gbk'))
length2 = len(str.encode('UTF-8'))
print(length1,length2)
21 28
2.3截取字符串
字符串属于序列,截取字符串可采用切片的方法:
string[start : end : step]
参数说明:
start:表示要截取的第一个字符的索引(包括该字符),如果不指定,则默认为0
end:表示要截取的最后一个字符的索引(不包括该字符),如果不指定,则默认为该字符串的长度
step:表示切片的步长,如果省略,则默认为1

str = '人生苦短,我用python!'
substr1 = str[1] #截取第2个字符串
substr2 = str[5:] #从第六个字符截取
substr3 = str[:5] #从左边开始截取5个字符
substr4 = str[2:5] #截取第三个到第五个字符
print("原字符串:",str)
print(substr1 +'\n'+ substr2 +'\n'+ substr3 +'\n' + substr4 )
原字符串: 人生苦短,我用python!
生
我用python!
人生苦短,
苦短,
注意:解决字符串不存在(string index out of range)时的报错方法
用try……except捕获异常
str = '人生苦短,我用python!'
try:
substr5 = str[16]
except IndexError:
print("指定的索引不存在")
指定的索引不存在
2.4分割字符串
分割字符串是把字符串分割为列表
方法split();具体使用:str.split(sep,maxsplit)
参数说明
sep:用于指定分割符,可以包含多个字符,默认为None,即所有空字符、换行符、制表符等
maxsplit:可选参数,用于指定分割符的次数
返回值:分割后的字符串列表
注意:如果不指定sep参数,那么也不能指定maxsplit参数
str1 = '人 生 苦 短 , 我 用 python!'
print('原字符串:',str1)
list1 = str1.split() #采用默认分割符进行分割
list2 = str1.split('>>>') #采用多个字符进行分割
list3 = str1.split('.') #采用“。”进行分割
list4 = str1.split(' ',4) #采用空格进行分割,且只分割4个
list5 = str1.split('>') #采用“>”进行分割
print(str(list1) + '\n' + str(list2) + '\n' +str(list3) + '\n' + str(list4) + '\n' + str(list5))
原字符串: 人 生 苦 短 , 我 用 python!
['人', '生', '苦', '短', ',', '我', '用', 'python!']
['人 生 苦 短 , 我 用 python!']
['人 生 苦 短 , 我 用 python!']
['人', '生', '苦', '短', ', 我 用 python!']
['人 生 苦 短 , 我 用 python!']
2.5检索字符串
1⃣️count():用于指定字符串在另一个字符串中出现的次数,如果检索不存在,则返回0,否则返回出现的次数
str.count(sub[, start[, end]])
sub:表示要检索的子字符串
start:表示检索范围的初始位置的索引,如果不指定,则从头开始检索
end:表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾
str2 = '@asffd @sdfhi @feuhs @mdfhy'
a = str2.count('@')
print("字符串",str2,"中包括",a,"个@符号")
字符串 @asffd @sdfhi @feuhs @mdfhy 中包括 4 个@符号
2⃣️find():用于指定字符串是否子字符串,如果检索不存在,则返回-1,否则返回该字符串的索引
str.find(sub[, start[, end]])
rfind():类似于find()只是从右边开始查找
str2 = '@asffd @sdfhi @feuhs @mdfhy'
b = str2.find('@')
print("字符串",str2,"中@符号首次出现的位置索引为",b)
字符串 @asffd @sdfhi @feuhs @mdfhy 中@符号首次出现的位置索引为 0
3⃣️index()或rindex():用于指定字符串是否子字符串,类似于find(),但是当指定的字符串不存在时会抛出异常
str.index(sub[, start[, end]])
str2 = 'asffd @sdfhi @feuhs @mdfhy'
c = str2.index('@')
print("字符串",str2,"中@符号首次出现的位置索引为",c)
字符串 asffd @sdfhi @feuhs @mdfhy 中@符号首次出现的位置索引为 6
str2 = 'asffd @sdfhi @feuhs @mdfhy'
c = str2.index('#')
print("字符串",str2,"中@符号首次出现的位置索引为",c)
Traceback (most recent call last):
File "" , line 2, in <module>
c = str2.index('#')
ValueError: substring not found
4⃣️startwith():用于检索字符串是否以指定子字符串开头,如果是则返回true,否则为false
str.startwith(sub[, start[, end]])
str2 = '@asffd @sdfhi @feuhs @mdfhy'
print("判断字符串",str2,"中是否以@符号为开头",str2.startswith('@'))
判断字符串 @asffd @sdfhi @feuhs @mdfhy 中是否以@符号为开头 True
str2 = 'asffd @sdfhi @feuhs @mdfhy'
print("判断字符串",str2,"中是否以@符号为开头",str2.startswith('@'))
判断字符串 asffd @sdfhi @feuhs @mdfhy 中是否以@符号为开头 False
5⃣️endwith():用于检索字符串是否以指定子字符串结尾,如果是则返回true,否则为false
str.endwith(sub[, start[, end]])
str2 = 'http://www.baidu.com'
print("判断字符串",str2,"中是否以.com符号为结尾",str2.endswith('.com'))
判断字符串 http://www.baidu.com 中是否以.com符号为开头 True
str2 = 'asffd @sdfhi @feuhs @mdfhy'
print("判断字符串",str2,"中是否以@符号为结尾",str2.endswith('.com'))
判断字符串 asffd @sdfhi @feuhs @mdfhy 中是否以@符号为开头 False
2.6字母的大小写转换
str.lower():转成小写
str.upper():转成大写
str2 = 'HTTP://www.baidu.COM'
print('原字符串:',str2)
print('小写的新字符串:',str2.lower())
print('大写的新字符串:',str2.upper())
原字符串: HTTP://www.baidu.COM
小写的新字符串: http://www.baidu.com
大写的新字符串: HTTP://WWW.BAIDU.COM
2.7去除字符串中的空格和特殊字符
strip():去除字符串左右抗辩的空格和特殊字符
str2 = ' HTTP://www.baidu.COM \n\r'
print(str2.strip())
HTTP://www.baidu.COM
str2 = '@HTTP://www.baidu.COM.@.'
print(str2.strip('@.'))
HTTP://www.baidu.COM
lstrip():去除字符串左边的空格和特殊字符
rstrip():去除字符串右边的空格和特殊字符
*特殊字符是指:制表符“\t”,回车符“\r”,换行符“\n”
str2 = '@HTTP://www.baidu.COM.@.'
print(str2.lstrip('@.'))
HTTP://www.baidu.COM.@.
str2 = '@HTTP://www.baidu.COM.@.'
print(str2.rstrip('@.'))
@HTTP://www.baidu.COM
2.8格式化字符串
格式化字符串是指先制定一个模板,在这个模板中预留几个空位,然后再根据需要天上相应的内容。这些空位需要通过指定的符号标记(也称占位符),而这些符号还不会显示出来。
1⃣️使用“%”操作符
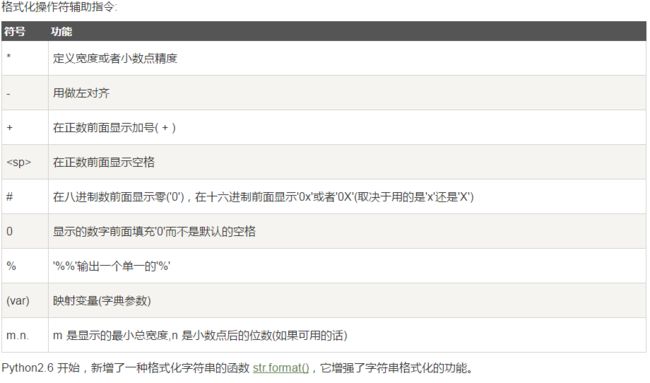
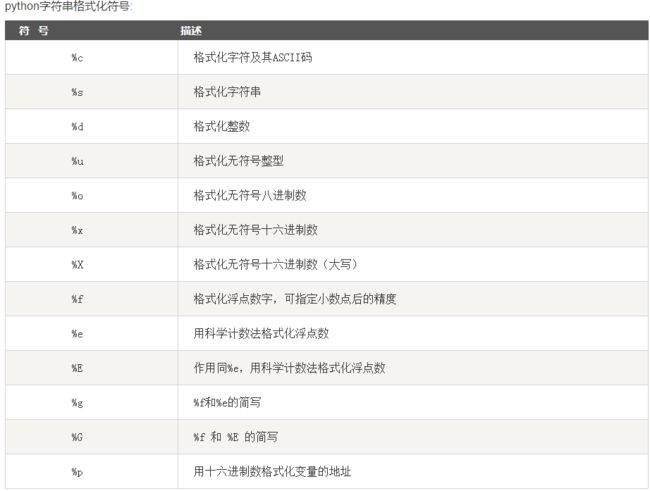
binary = "binary"
do_not = "don't"
x = "There are %d types of people." %10
y = "Those who know %s and those who %s." %(binary,do_not)
print("I said : %r." %x)
print("I also said: '%s'." %y)
I said : 'There are 10 types of people.'.
I also said: 'Those who know binary and those who don't.'.
因此,这种格式化方式的主要问题是过于繁琐,容易出错,不能正确格式化元组与字典。
2⃣️使用format()
str.format(args)
str:模板
args:用于指定要转换的项,如果有多项则用逗号分隔
在创建模板时,需要用{} 和 : 指定占位符
通过大括号,我们可以在字符串中嵌入变量:
"Hello, {}. You are {}.".format(name, age)
'Hello, Eric. You are 74.'
或者直接使用变量名称:
person = {
'name': 'Eric', 'age': 74}
"Hello, {name}. You are {age}.".format(name=person['name'], age=person['age'])
'Hello, Eric. You are 74.'
在引用字典时,可以用**操作符进行字典拆包:
person = {
'name': 'Eric', 'age': 74}
"Hello, {name}. You are {age}.".format(**person)
'Hello, Eric. You are 74.'
和 % 方式相比,使用str.format() 的代码可读性要好很多。但如果在较长的字符串中嵌入多个变量,依然会显得繁琐。
3⃣️f-Strings:一种改进版格式化方式
f-strings 的句法类似于str.format(),但要更简洁,你可以感受一下它的可读性:
name = "Eric"
age = 74
f"Hello, {name}. You are {age}."
'Hello, Eric. You are 74.'
前缀f也可以使用大写的F。支持任意表达式,由于 f-strings 是在运行时计算具体值的,我们得以在字符串中嵌入任意有效的 Python 表达式,从而写出更优雅的代码。
三种方式速度比较
import timeit
def add():
status = 200
body = 'hello world'
return 'Status: ' + str(status) + 'rn' + body + 'rn'
def old_style():
status = 200
body = 'hello world'
return 'Status: %srn%srn' % (status, body)
def formatter1():
status = 200
body = 'hello world'
return 'Status: {}rn{}rn'.format(status, body)
def formatter2():
status = 200
body = 'hello world'
return 'Status: {status}rn{body}rn'.format(status=status, body=body)
def f_string():
status = 200
body = 'hello world'
return f'Status: {status}rn{body}rn'
perf_dict = {
'add': min(timeit.repeat(lambda: add())),
'old_style': min(timeit.repeat(lambda: old_style())),
'formatter1': min(timeit.repeat(lambda: formatter1())),
'formatter2': min(timeit.repeat(lambda: formatter2())),
'f_string': min(timeit.repeat(lambda: f_string())),
}
print(perf_dict)
{
'add': 0.5501344169988442,
'old_style': 0.3909595069999341,
'formatter1': 0.5025860030000331,
'formatter2': 0.8049639130003925,
'f_string': 0.33797403199969267}
为何 f-string 速度如此快
从指令来看,f'Status: {status}rn{body}rn' 翻译成:
8 LOAD_CONST 3 ('Status: ')
10 LOAD_FAST 0 (status)
12 FORMAT_VALUE 0
14 LOAD_CONST 4 ('rn')
16 LOAD_FAST 1 (body)
18 FORMAT_VALUE 0
20 LOAD_CONST 4 ('rn')
22 BUILD_STRING 5
正如指令中所示的,f-string 是运行时渲染的,底层中转成了类似 "Status: " + status+ "rn" + body + "rn" 的形式
我们仍然可以使用以前的方式进行格式化,但在此推荐 f-string 方式,因为它使用更简洁,更易读且更方便,性能又更好,完全没理由拒绝啊。
从今天开始使用 f-string!