有了上次爬虫的基础,本次教程主要把爬到的数据存入MongoDB数据库中。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
1.运行环境与安装
1.运行环境
操作系统:win7
数据库:MongoDB
python库:BeautifulSoup,requests,pymongo
IDE:jupyter notebook
2.运行环境安装
1.MongoDB安装
- 如果你用的是windows xp,那么MongoDB从2.2开始就已经不支持了,你可以试着安装MongoDB 2.2版本。
- 如果你用的是windows server 2008 R2 或 win7,需要先安装一个补丁:https://support.microsoft.com/zh-cn/help/2731284/-33-dos-error-code-when-memory-memory-mapped-files-are-cleaned-by-using-the-flushviewoffile-function-in-windows-7-or-in-windows-server-2008-r2
以上机型问题搞定后,下面是所有windows用户的安装教程。
- 下载与你的操作系统对应的安装包,打开安装包,按照引导一路下一步进行,默认安装到C盘。下载地址:https://www.mongodb.com/download-center#community
- 手动设置MongoDB环境
我们要设置一个目录来保存数据,推荐默认路径C:\data\db。在命令行输入如下指令:
md C:\data\db
表示在C盘创建了一个目录data\db,存入数据库中的数据都会保存在这里。
- 启动MongoDB
在命令行输入:
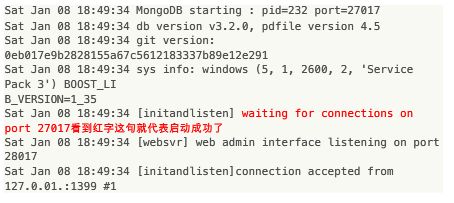
C:\Program Files\MongoDB\Server\3.4\bin\mongod.exe
你的路径也许和我的不同,以你自己的为准。看到图1中的红字表示启动成功。
- 连接MongoDB
不要关闭刚才的命令行窗口,打开一个新命令行窗口,输入如下指令:
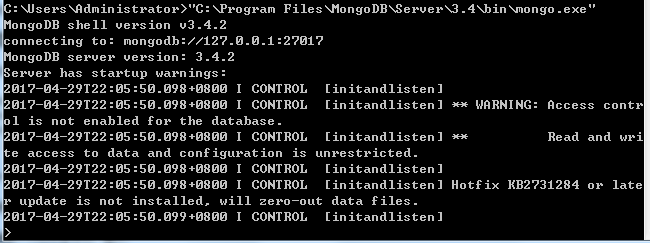
“C:\Program Files\MongoDB\Server\3.4\bin\mongo.exe”
因为目录中包含空格,所以需要加上双引号。看到图2左下角的“>”,表示连接成功(虽然有警告,但是不影响正常使用)。
- MongoDB基本操作
现在已经成功连接MongoDB,我们可以创建并查看里面的数据库。输入如下指令创建一个数据库:
use test
表示创建并使用了一个名为test的数据库,用下面的指令向test数据库中添加一个集合:
db.createCollection("mCollection")
创建了一个名为mCollection的集合。可用下面指令来查看MongoDB中的数据库:
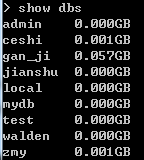
show dbs
显示如图3,其中test就是刚才我们创建的数据库,其他的都是我之前创建的。
用下面的指令来查看test数据库中的集合:
use test
show collections
图4显示了我们刚才创建的mCollection集合。
更多关于MongoDB的基本操作,请移步 http://www.yiibai.com/mongodb/mongodb_quick_guide.html
- 为windows系统配置MongoDB,让其随windows一起启动(可选)
如果不做这一步,每次启动windows时,像上面那样手动启动MongoDB即可。
刚才打开了两个命令行窗口,现在都可以关闭了。打开一个新命令行窗口,输入:
mkdir C:\data\log
关闭这个命令行,然后在硬盘的某个地方创建一个名为mongod.cfg的文件,在其中输入:
systemLog:
4个空格destination:1个空格file
4个空格path:1个空格c:\data\log\mongod.log
storage:
4个空格dbPath:1个空格c:\data\db
即
systemLog:
destination: file
path: c:\data\log\mongod.log
storage:
dbPath: c:\data\db
以管理员的权限重新打开一个命令行,输入如下命令:
"C:\Program Files\MongoDB\Server\3.4\bin\mongod.exe" --config "C:\mongodb\mongod.cfg" --install
等待结束;如果一直卡着不动,过一会儿关闭就是(路径以你自己的为准)。命令行中输入如下命令,启动MongoDB服务:
net start MongoDB
2.pymongo安装
pymongo是一个python库,用于操作MongoDB中的数据库。
打开一个命令行,输入如下命令:
D:\Anaconda3\Scripts\pip install pymongo

如图5所示,表示用Anaconda3自带的pip工具安装pymongo库。若显示如图6,说明安装成功。

2.把商品数据存入数据库
1.连接MongoDB
开始编程:
from bs4 import BeautifulSoup
import requests
import pymongo #引入pymongo库
#连接MongoDB
client = pymongo.MongoClient('localhost',27017)
#创建一个名为ganJi的数据库
ganJi = client['ganJi']
#在ganJi数据库中创建一个名为item_info的集合
item_info = ganJi ['item_info']
在上面的代码中,client['ganJi']中的ganJi是MongoDB中数据库的名字,ganJi = client['ganJi']中赋值号左边的ganJi是本python代码中要操作ganJi数据库的对象名字。尽量使赋值号左右两边取相同的名字,避免出错。
2.爬取商品信息并存入数据库
for each_link in link_list:
wb_data = requests.get(each_link)
soup = BeautifulSoup(wb_data.text,'lxml')
title = soup.select('h1.title-name')[0].get_text()
price = soup.select('i.f22.fc-orange.f-type')[0].get_text()
date = soup.select('i.pr-5')[0].get_text()
areas = soup.select('ul.det-infor > li > a')
area = ''
for i in areas:
area += i.get_text()+'-'
area = area[:-1]
data = {
'标题':title,
'日期':date.strip().split('\xa0')[0],
'价格':price,
'地点':area
}
print (data)
item_info.insert_one(data) #把一条data字典存入数据库
在上面的代码中,用到了上次教程中的link_list。对于每个链接对应的商品,爬取其信息,并通过insert_one方法存入ganJi数据库中的item_info集合中。
3.查看数据库中的数据
可通过find方法来查看item_info集合中的商品数据:
for i in item_info.find():
print(i)
结果显示为:
{'_id': ObjectId('5904b9e28e7b770dc44c2a0e'), '标题': '北京移动的卡,05年15元包月流量随便用,全国的,永久有效, - 2800元', '日期': '04-29 13:51', '价格': '2800', '地点': '近期价格走势- 北京-通州'}
{'_id': ObjectId('5904b9e28e7b770dc44c2a0f'), '标题': '官网抢购小米6忍痛转让 - 2799元', '日期': '04-29 14:19', '价格': '2799', '地点': ' 北京-海淀-中关村'}
{'_id': ObjectId('5904b9e38e7b770dc44c2a10'), '标题': '欧沃4s手机 - 400元', '日期': '04-29 12:46', '价格': '400', '地点': ' 北京-北京周边'}
{'_id': ObjectId('5904b9e38e7b770dc44c2a11'), '标题': '全新未拆封小米6 亮黑色 - 2999元', '日期': '04-28 22:49', '价格': '2999', '地点': ' 北京-丰台'}
{'_id': ObjectId('5904b9e38e7b770dc44c2a12'), '标题': 'iphone4s转让,非华为小米酷派天语中兴 - 240元', '日期': '04-27 17:44', '价格': '240', '地点': '近期价格走势- 北京-海淀-北太平庄'}
{'_id': ObjectId('5904b9e48e7b770dc44c2a13'), '标题': '电信无线座机 电信无线座机电话 - 350元', '日期': '04-27 17:03', '价格': '350', '地点': '近期价格走势- 北京-丰台-丽泽桥'}
注意到,除了我们想要的信息外,每条数据自动增加了一个叫做“_id”的字段,它用来编号集合中的数据,每条数据都有一个唯一的ID。
4.从数据库中导出数据
现在MongoDB中已经存储了爬取的商品信息,现在我们要把这些信息导出为csv文件和json文件。导出文件的一般格式为:
mongoexport -h 127.0.0.1 -d dataBaseName -c collectionName -o yourPath
- 若要导出为csv文件,在命令行中输入下面的指令:
mongoexport -h 127.0.0.1 -d ganJi -c item_info -o E:\testCsv.csv
- 若要导出为json文件,在命令行中输入下面的指令:
mongoexport -h 127.0.0.1 -d ganJi -c item_info -o E:\testJson.json
若显示图7所示内容,表示导出成功。
这样,csv文件就可用excel查看了,json文件就可用Notepad++查看了。
5.把数据导入到数据库
我们就把刚才导出的两个文件testCsv.csv和testJson.json再导入到数据库。导入文件的一般格式为:
mongoimport -h 127.0.0.1 -d database_name -c collection_name yourPath
- 若要导入csv文件,在命令行中输入下面的指令:
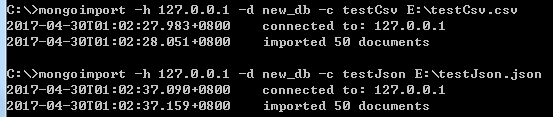
mongoimport -h 127.0.0.1 -d new_db -c testCsv E:\testCsv.csv
- 若要导入json文件,在命令行中输入下面的指令:
mongoimport -h 127.0.0.1 -d new_db -c testJson E:\testJson.json
若显示图8所示内容,表示导入成功。