第八章:SQL Server2019数据库之分组统计(GROUP BY)
目录
- 一、分组统计
-
- 1、使用 GROUP BY 子句创建分组
- 2、使用 GROUP BY 子句创建多列分组
- 3、对表达式进行分组统计
- 4、在统计中使用 ROLLUP 关键字和 CUBE 关键字
- 5、GROUP BY 子句的 NULL 值处理
- 6、使用 HAVING 子句进行过滤分组
学前必备知识
- 第一章:SQL Server 数据库环境搭建与使用
- 第二章:SQL Server2019 数据库的基本使用之图形化界面操作
- 第三章:SQL Server2019数据库 之 开启 SQL 语言之旅
- 第四章:SQL Server2019数据库 之 综合案例练习、 使用SQL语句插入数据、更新和删除数据
- 第五章:SQL Server2019数据库之 综合案例练习、开启 SELECT 语句之旅
- 第六章:SQL Server2019数据库之 SELECT 语句的深入使用
- 第七章:SQL Server2019数据库之 单表查询综合练习 及SELECT 语句的进阶使用
一、分组统计
本小节介绍如何使用 GROUP BY 子句对数据进行分组统计,以便汇总数据表的内容。并且介绍使用 WHERE 子句或 HAVING 子句对分组结果进行过滤。
1、使用 GROUP BY 子句创建分组
在 第七章:SQL Server2019数据库之 单表查询综合练习 及SELECT 语句的进阶使用 一文中已经学习过使用聚合函数对指定数据表中的所有行进行计算,以便得到一个统计的值,但是如果需要获取其中一部分行的统计值则需要使用 GROUP BY 子句。GROUP BY 子句在查询结果集生成多个分类汇总。
【例1】在 goods 商品信息表中根据商品种类 id(cat_id) 分组统计每种分类下的商品数量,这样需要将 GROUP BY 子句与 COUNT() 函数联合使用来进行处理。SQL 语句如下:
SELECT cat_id AS '商品种类', COUNT(*) AS '数量'
FROM goods
GROUP BY cat_id;
查询结果如下图所示:
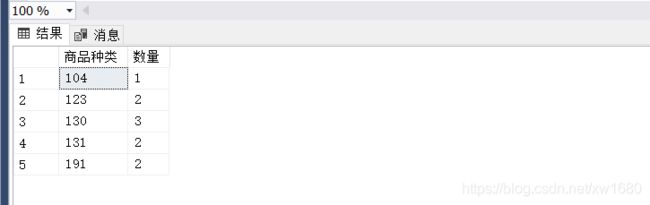
从上图所示的查询结果集中可以看到,使用 GROUP BY 子句实质上是根据数据表中的列进行分类操作,结合使用聚合函数统计此列每一类的数据。
【练习1】:把 student 表按照 性别 这个单列进行分组。
如果这时在 SELECT 子句中除了查询 cat_id 字段、COUNT(*) 之外,同时添加一些数据表中的其他字段,例如:
SELECT goods_name, cat_id AS 商品种类id, MIN(shop_price) 最低售价,
MAX(cost_price) 最高成本价, AVG(shop_price) 平均售价, COUNT(*) AS 数量
FROM goods
GROUP BY cat_id
ORDER BY MAX(cost_price) DESC;
运行上述代码将会出现下图所示的错误:

说明:从图中的错误信息可以看出,如果使用了 GROUP BY 子句进行分组查询,SELECT 查询的列必须包含在 GROUP BY 子句中或者包含在聚合函数中。
【例2】使用 GROUP BY 子句与聚合函数,统计 goods 商品信息表中,每种分类下的商品相关信息。SQL 语句如下:
SELECT cat_id AS 商品种类id, MIN(shop_price) 最低售价,
MAX(cost_price) 最高成本价, AVG(shop_price) 平均售价, COUNT(*) AS 数量
FROM goods
GROUP BY cat_id
ORDER BY MAX(cost_price) DESC;
查询结果如下图所示:
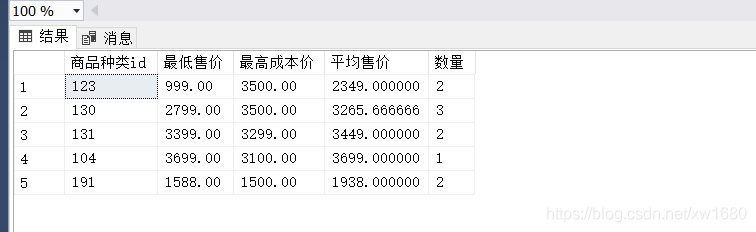
在上述代码中根据商品种类 id (cat_id) 进行分组,然后分别使用 MAX()、AVG() 和 COUNT() 函数对每种类型的商品相关信息进行统计。上述示例是一个典型的聚合函数与 GROUP BY 子句相结合的例子。下面分析执行含有 GROUP BY 子句的 SELECT 查询的步骤:
- 数据库系统首先执行 FROM 子句。
- 如果在 SELECT 查询中存在 WHERE 子句,那么根据其中的条件,从结果集中筛选出比较结果为 TRUE 的行。
- 根据 GROUP BY 子句指定的分组字段将结果集进行分组。
- 最后根据 SELECT 子句的值为每组生成查询结果中的一行。
2、使用 GROUP BY 子句创建多列分组
在上面的小节中已经介绍了如何使用 GROUP BY 子句对单一列分组,SELECT 语句中的 GROUP BY 子句只有一列,是组合查询中最简单的形式。实质上 GROUP BY 子句可以根据多列进行分组,并且 SELECT 语句中的 GROUP BY 子句中列出的列的数目没有上限,对这些列唯一的限制是组合列必须是查询数据表中的列。
【例3】在商品信息表 goods 中,根据商品的种类 id 和品牌 id 进行分组查询。SQL 语句如下:
SELECT cat_id AS 商品种类id, brand_id 品牌id, MIN(shop_price) 最低售价,
MAX(cost_price) 最高成本价, AVG(shop_price) 平均售价, COUNT(*) AS 数量
FROM goods
GROUP BY cat_id, brand_id
ORDER BY MAX(cost_price) DESC;
查询结果如下图所示:
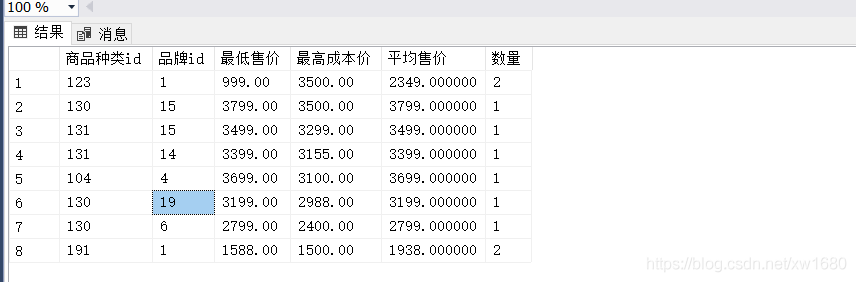
从图中可以看出,查询只是生成了商品种类和品牌的总汇,SQL 并不会在同一结果表中既给出根据商品种类的分类汇总又给出根据品牌的分类汇总。
【练习2】在 student 表中,按照 性别 和 年龄 列进行分组。
3、对表达式进行分组统计
使用表达式进行分组虽然不常见,但可以在 GROUP BY 子句中使用表达式,使用 SQL Server 的字符串连接符将数据表中的一些字段进行连接,然后根据这些表达式进行分组操作。
【例4】在 user_address 用户地址表中,将收货人(consignee)和收货地址(address)字段连接,并按照收货地址和联系方式进行分组。SQL 语句如下:
SELECT '收货人:' + consignee + '的地址为:' + address AS '收货地址',
'联系电话为:' + mobile AS 联系方式
FROM user_address
GROUP BY 收货地址, 联系方式;
执行上面的代码,结果如下图所示:

这是因为 GROUP BY 子句是在 FROM 和 WHERE 子句中寻找结果集中的列进行分组统计,收货地址 和 联系方式 字段在系统计算 FROM、GROUP BY 子句之前都不存在,所以 GROUP BY 子句在 FROM 子句中寻找不到 收货地址 和 联系方式 这两个字段。为了解决上述问题,可以在 FROM 子句中嵌入一个子查询来产生计算过的列。SQL 语句如下:
SELECT 收货地址, 联系方式
FROM (SELECT '收货人:' + consignee + '的地址为:' + address AS '收货地址',
'联系电话为:' + mobile AS 联系方式 FROM user_address) a
GROUP BY 收货地址, 联系方式;
查询结果如下图所示:
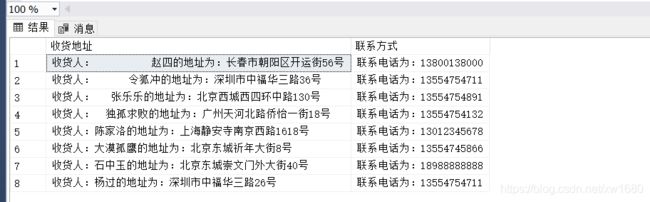
由于 FROM 子句产生的输出结果将包含 收货地址 和 联系方式 字段,所以在 GROUP BY 子句中就可以对 收货地址 和 联系方式 这两个字段进行分组。由此示例可以看出,在 GROUP BY 子句中使用表达式比使用单个列要复杂得多,所以这种 SQL 语句要尽量避免。
4、在统计中使用 ROLLUP 关键字和 CUBE 关键字
SQL 中可以使用 GROUP BY 子句根据一个列或多个列总计表中的数据,同时可以在 GROUP BY 子句中使用 ROLLUP 关键字对字段的几种可能性进行分组。
【例5】在 SQL Server 数据库中,使用 ROLLUP 关键字统计 emp 员工表中每个部门的工资总和。SQL 语句如下:
SELECT e.deptno, d.DNAME, SUM(e.sal) AS 工资总和
FROM emp e, dept d
WHERE e.deptno = d.DEPTNO
GROUP BY e.deptno, d.DNAME WITH ROLLUP;
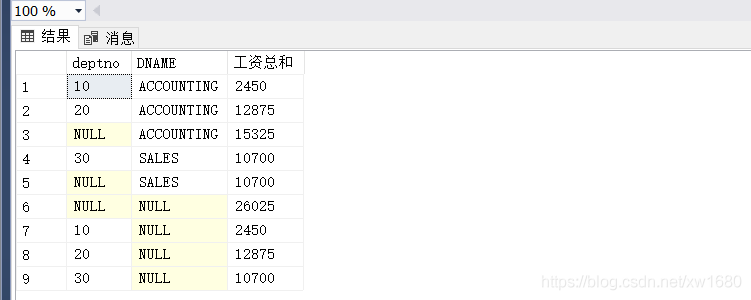
查询结果如下图所示:

从运行结果中可以看出,使用 ROLLUP 关键字实质上就是通知数据库系统生成 GROUP BY 子句中的列的分类汇总和总的汇总,即生成本部门的工资总和与各个部门的工资总和。运行结果中的每个 NULL 值都是 ROLLUP 关键字生成的分类汇总,列中的 NULL 值表示对该列的所有值。例如,在上图中的第 2 行 DNAME 列的 NULL 值代表的是 10号部门 所有员工的工资的总数。最后一行的两个NULL 值代表 工资总和 列包括所有部门的工资总和。
【例6】统计 dept 部门表中,各部门的工资总和。SQL 语句如下:
SELECT e.deptno, d.DNAME, SUM(e.sal) AS 工资总和
FROM emp e, dept d
WHERE e.deptno = d.DEPTNO
GROUP BY e.deptno, d.DNAME WITH CUBE;
查询结果如下图所示:
5、GROUP BY 子句的 NULL 值处理
如果在 GROUP BY 子句修饰的列值中带有 NULL 值,那么系统将带有 NULL 值的每一行都自成一组。因为在 SQL 中规定 NULL<>NULL,因此如果一行中已经带有 NULL 值的组合列,则不能放在另一个带有 NULL 值的组合列中。如果两行在相同的组合列中有 NULL 值,而在其余的非 NULL 的组合列中的值需要匹配,数据库系统将这些列组合在一起。尽管在 SQL 中规定 NULL<>NULL,但在 GROUP BY 子句中却将同一列上所有的 NULL 值都分为一组。
【例7】在 users 用户信息表中的第三方付款方式(oauth) 字段存在 NULL 值,然后按照第三方付款方式进行分组,统计数据表中付款方式的数量。SQL 语句如下:
SELECT oauth AS 第三方付款方式, COUNT(*) AS 数量
FROM users
GROUP BY oauth;
查询结果如下图所示:

6、使用 HAVING 子句进行过滤分组
在 SQL 中使用 WHERE 子句可以限制那些不需要的行,同时也可以使用 HAVING 子句删除那些总计或单独列不能满足 HAVING 子句中搜索条件的一组数据。在 SQL 语句中 WHERE 子句不能用于限制聚合函数,而 HAVING 子句可以用来限制聚合函数。
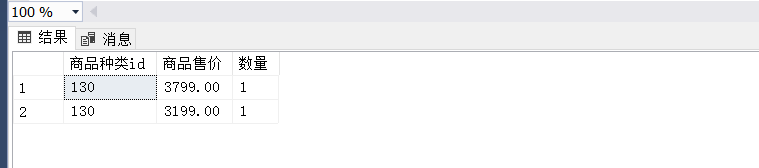
【例8】在 goods 商品信息表中,分组统计所有库存(store_count) 小于1000 并且售价 (shop_price)大于所有商品平均售价的不同种类(cat_id) 的商品数量。SQL 语句如下:
SELECT cat_id 商品种类id, shop_price 商品售价, COUNT(cat_id) 数量
FROM goods
WHERE store_count < 1000
GROUP BY cat_id,shop_price
HAVING (shop_price > (SELECT AVG(shop_price) FROM goods))
ORDER BY shop_price DESC;
查询结果如下图所示:
在上面的代码中,使用子查询的形式作为 HAVING 的判断条件,满足商品价格大于平均商品价格的条件。这段代码在数据库系统中的执行流程如下:
- 每次首先检查中间表并清除那些库存量不小于 1000 的数据行。
- 数据库系统根据商品种类组合这些数据行。
- 数据库系统使用 HAVING 子句中的搜索条件来检查每组中的行。在本示例中,统计所有大于平均售价的数据行,并放在以商品种类分类的组中。
- 统计每个行组中 cat_id 字段的数量,并在每组中清除那些小于平均售价的行。
- 最后对查询结果集根据 shop_price 字段进行降序排列,然后将最终结果集返回给用户。在 SQL 中可以使用 WHERE 子句从查询结果集排除行。对于数据库系统来说,WHERE 子句中的表达式必须对单独行进行计算,而在 HAVING 子句的搜索条件中的表达式通常是对一组行进行计算,所以 WHERE 子句中的搜索条件由使用列引用与实际值的表达式组成,而 HAVING 子句的搜索条件通常由一个或多个聚合函数组成。
通常带有HAVING子句的语句在数据库系统的查询步骤如下:
- 根据 FROM 子句中的数据表创建中间表,如果 FROM 子句中只有一张表,那么中间表就是源数据表的副本。
- 如果 SELECT 查询语句中含有WHERE子句,则根据搜索条件将不满足条件的行过滤掉。
- 将中间表中的行根据 GROUP BY 子句指定的列排列成组。
- 将 HAVING 子句中每个搜索条件应用于查询中的每个组,如果其中某个组不满足一个或多个搜索条件,则从中间表中删除该组。
- 统计 SELECT 语句中的每一项并为每一项生成单一的行。
- 如果查询包括关键字 DISTINCT,则从结果集中清除任何重复的行。
- 如果在查询语句中存在 ORDER BY 子句,则根据列在 ORDER BY 子句中的列值对结果表排序。
HAVING 子句类似于 WHERE 子句,在子句中求表达式值的结果有3种类型,分别为NULL、TRUE和 FALSE。如果 HAVING 子句对数据表中一组数据求值的结果为 TRUE 或 NULL,数据库系统使用组中的行生成结果集的行;如果 HAVING 子句对数据表一组数据求值的结果为 FALSE,则数据库系统在结果集中不添加该组。
说明:WHERE 子句与 HAVING 子句主要区别如下:
- WHERE 不能放在 GROUP BY 后面,而 HAVING 子句可以。
- HAVING 是与 GROUP BY 连在一起使用的,放在 GROUP BY 后面,此时的作用相当于 WHERE 子句。
- WHERE 后面的条件中不能有聚合函数,比如SUM()、AVG()等,而HAVING子句可以。总的来说,WHERE 子句在数据分组前进行过滤,而 HAVING 子句在数据分组后进行过滤。
【练习3】在 student 表中,先按 性别 分组求出平均年龄,然后筛选出平均年龄大于20岁的学生信息。
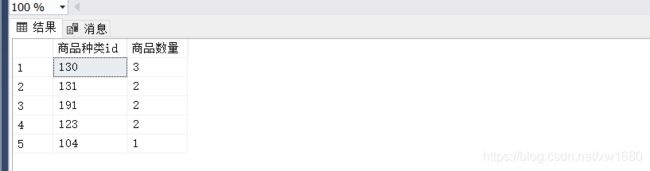
【例9】在 goods 商品信息表中,根据每种商品分类分组统计每种分类的商品数量并进行降序排列。SQL 语句如下:
SELECT cat_id 商品种类id, COUNT(cat_id) 商品数量
FROM goods
GROUP BY cat_id
ORDER BY 商品数量 DESC;
查询结果如下图所示:
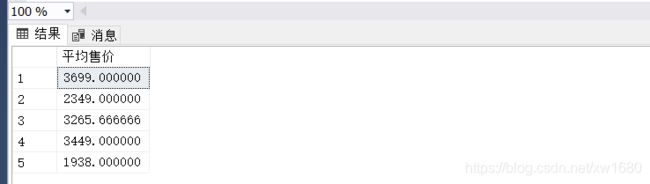
【例10】在 goods 商品信息表中,查询每种商品分类下商品的平均售价。SQL 语句如下:
SELECT AVG(shop_price) AS 平均售价
FROM goods
GROUP BY cat_id;
查询结果如下图所示:
总结:本篇博文介绍了分组统计,可以使用 GROUP BY 子句对多组数据进行汇总统计,返回每个组的结果。并且介绍了如何使用 HAVING 子句过滤特定的分组。