mysql通过kafka实现数据实时同步(四)——zookeeper集群和kafka集群配置以及kafka connector之debezium的使用
zookeeper集群和kafka集群配置以及kafka connector的使用
zooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、命名服务、分布式同步、组服务等。官网:http://zookeeper.apache.org/
kafka是一种高吞吐量的分布式发布订阅消息系统,kafka的运行依赖zooKeeper。官网:http://kafka.apache.org/
kafkaconnect 是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具,可自己编写。
debezium是JBOSS主导开发的一款分布式的支持数据库CDC捕获行级别的数据变更的工具,采用java编写,支持kafka使用。官网:https://debezium.io/
1、zookeeper集群配置
(1)解压
![]()
(2)进入conf目录下,复制zoo-sample.cfg文件重命名为zoo.cfg
![]()
(3)修改zoo.cfg配置
tickTime=2000
initLimit=10
syncLimit=5#zookeeper数据存路径,需要修改
dataDir=/home/data/zookeeper
clientPort=2181#集群机器配置,多台就配置多个server
server.1=172.17.126.32:2888:3888
server.2=172.17.126.33:2888:3888
server.3=172.17.126.34:2888:3888说明:2888原子广播端口,3888选举端口
(4)在 dataDir目录下新建myid文件,文件内容只有一个数字表示当前服务器编号
vim myid
1
(5)远程copy文件夹到另外两台服务器,只需要修改myid文件里面的内容,命令可参考步骤二。
(6)zookeeper启动,进入bin目录下
![]()
(7)查看状态
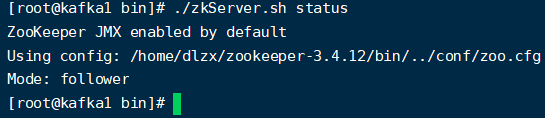
至此zookeeper集群搭建成功
2、kafka集群配置
(1)解压
![]()
(2)修改配置,config/server.properties
#节点值,每台服务器都必须保证不一样
broker.id=0
#监听ip,填写服务器ip
listeners=PLAINTEXT://172.17.126.32:9092#对外ip,内外网访问时用到的
advertised.listeners=PLAINTEXT://172.17.126.32:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600#kafka日志数据目录
log.dirs=/home/data/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1#消息过期时间,hours可更改为minutes、等
log.retention.hours=24
log.segment.bytes=1073741824#zookeeper连接地址,多个以逗号隔开
zookeeper.connect=172.17.126.32:2181,172.17.126.33:2181,172.17.126.34:2181
zookeeper.connection.timeout.ms=60000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
log.retention.ms=1000#消息绝对删除
log.cleanup.policy=delete
(3)远程copy到另外两台服务器,修改参数
(4)分别启动各台服务器的kafka,-daemon(守护线程)
./kafka_2.13-2.6.0/bin/kafka-server-start.sh -daemon ./kafka_2.13-2.6.0/config/server.properties
(5)一些常见命令如下
查看topic list:./kafka-topics.sh --bootstrap-server 172.17.126.32:9092,172.17.126.33:9092,172.17.126.34:9092 --list
创建topic:./kafka-topics.sh --create --zookeeper 172.17.126.32:2181 --replication-factor 3 --partitions 3 --topic test
删除topic:./kafka-topics --delete --zookeeper 172.17.126.32:2181 --topic test
生产消息:./kafka-console-producer.sh --broker-list 172.17.126.32:9092 --topic test
消费消息:./kafka-console-consumer.sh --bootstrap-server 172.17.126.32:9092 --topic test --from-beginning
至此kafka集群搭建成功
3、connector
(1)将debezium压缩包上传到/usr/local/share/java目录并解压
(2)修改kafka里面,config/connect-distributed.properties配置,需要修改的就两处地方
#kafka集群地址
bootstrap.servers=172.17.126.32:9092,172.17.126.33:9092,172.17.126.34:9092
#最后一行注释掉#号,配置为debezium压缩包的地址
plugin.path=/usr/local/share/java
(3)启动connector
./bin/connect-distributed.sh -daemon ./config/connect-distributed.properties
(4)操作connector
GET /connectors – 返回所有正在运行的connector名。
POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
GET /connectors/{name} – 获取指定connetor的信息。
GET /connectors/{name}/config – 获取指定connector的配置信息。
PUT /connectors/{name}/config – 更新指定connector的配置信息。
GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
GET /connectors/{name}/tasks – 获取指定connector正在运行的task。
GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息。 PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。
PUT /connectors/{name}/resume – 恢复一个被暂停的connector。
POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用
POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。
DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。
(5)添加示例
下图状态代表connector连接正常,如果有问题,tasks里面会给出错误提示的
![]()
(6)针对步骤五中的配置参数解释
{
"name": "connector",//当前connector连接的名称,唯一
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",//固定写死
"database.hostname": "",//数据库连接地址
"database.user": "",//数据库用户名
"database.password": "",//数据库密码
"database.port": "3306",//数据库端
"database.server.id": "1001",//数据库服务id,此id作为从机加入到mysql集群中,每台机器唯一
"tasks.max": "3",//最大任务数
"database.history.kafka.bootstrap.servers": "172.20.24.99:9092,172.20.24.66:9092",//kafka集群地址
"database.history.kafka.topic": "dbhistory.connector",//kafka topic的全名,连接器将把数据库的schema历史信息存入这个topic中
"database.server.name": "connector",//debezium监控的mysql服务器/集群的逻辑名,在集群中应该唯一
"database.serverTimezone": "UTC",//mysql8以上需要的时区配置
"decimal.handling.mode": "double",//针对decimal类型的参数转下数据类型
"snapshot.mode": "schema_only",
"inconsistent.schema.handling.mode": "warn"
}
}
MySQL连接器每次获取快照的时候会执行以下的步骤:
1. 获取一个全局读锁,从而阻塞住其他数据库客户端的写操作。
2. 开启一个可重复读语义的事务,来保证后续的在同一个事务内读操作都是在一个一致性快照中完成的。
3. 读取binlog的当前位置。
4. 读取连接器中配置的数据库和表的模式(schema)信息。
5. 释放全局读锁,允许其他的数据库客户端对数据库进行写操作。
6. (可选)把DDL改变事件写入模式改变topic(schema change topic),包括所有的必要的DROP和CREATE DDL语句。
7. 扫描所有数据库的表,并且为每一个表产生一个和特定表相关的kafka topic创建事件(即为每一个表创建一个kafka topic)。
8. 提交事务。
9. 记录连接器成功完成快照任务时的连接器偏移量。
重要配置说明:
snapshot.mode:
默认initial,它会默认执行一次数据库初始的一致性快照任务。
when_needed,允许连接器在有必要的任何时候执行快照任务。
never,保证了连接器从不执行快照任务,当一个新的连接器配置成这种模式的时候,它会从binlog的起始位置开始读。
schema_only,允许连接器启动后从它当前所在MySQL binlog位置开始读,建议启用此配置。
schema_only_recovery,允许一个存在的连接器去恢复中断的或者丢失的数据库历史topic。
inconsistent.schema.handling.mode:指定连接器对与内部模式表示形式中不存在的表相关的binlog事件应如何反应。
默认为fail,异常时连接器会停止。
warn,跳过异常,有问题的事件及其binlog偏移会被记录,建议启用此配置。
ignore,跳过异常。
4、java消费kafka消息,进行相应的逻辑操作并写入到es里面。
5、重点说明:
服务器肯定会出现重启的情况,而为了保证数据的不重复,snapshot.mode是绝对不能设置为never的。
大多数时候mysql的binlog日志并不是全量的,因此为了保证数据从当前位置读取,也不能采用initial配置,建议配置成schema_only。
欢迎各位加qq群技术交流:1039603877