学习指南:SQL窗口函数
【干货满满】
最近由于面试需要,回顾了SQL当中的窗口函数,并整理了面试以及实际工作中常用的几种窗口函数,话不多说,直接上干货!!!
文章目录
- 前言
- 一、聚合函数作为窗口函数sum()、avg()、max()、min()、count()
-
- 1、应用场景
- 2、语法结构
- 3、案例说明
- 二、分区排序窗口函数row_number()、rank()、dense_rank()
-
- 1、应用场景
- 2、语法结构
- 3、案例说明
- 三、分组排序窗口函数ntile()
-
- 1、应用场景
- 2、语法结构
- 3、案例说明
- 四、偏移分析窗口函数lag()、lead()
-
- 1、应用场景
- 2、语法结构
- 3、案例说明
- 五、结语
前言
回想当初我在学习SQL窗口函数时,基本概念心中已大致有了了解,但是具体窗口函数类型以及相同类型不同窗口函数的用法区别一直混淆,我相信大家在学习窗口函数相关知识时也会有同样的困惑。
因此我决定在本篇文章中窗口函数的基本概念就不做过多介绍了,直接讲解几种常用窗口函数的具体用法,以案例练习题加图表说明的方式大家理解起来会更加容易。但是,如果大家有需要可以评论或者私信我再出一版SQL窗口函数的基本概念以及与普通group by的区别,同时也会附带大量SQL练习题讲解哦。
一、聚合函数作为窗口函数sum()、avg()、max()、min()、count()
1、应用场景
1、截止到某月累计数值问题
2、计算移动平均等问题
3、连续多个月中,单月最大支付金额问题
2、语法结构
以sum聚合函数为例:
sum(字段名A) over(partition by 字段名B order by 字段名C rows between D1 and D2)
其中:
① partition by:按照某一字段将数据进行分组;
② order by:按照某一字段将数据进行排序,默认升序ASC,可设置为降序DESC;
③ 字段名A:被聚合操作的字段;
④ 字段名B:通过该字段进行分组;
⑤ 字段名C:通过该字段进行排序;
⑥ D1:行数的起始范围;
⑦ D2:行数的结束范围;
rows between D1 and D2用法如下:
rows between unbounded preceding and current row——包括本行和之前所有的行
rows between current row and unbounded following——包括本行和之前所有的行
rows between 2 preceding and current row——包括本行和前2行
rows between 2 preceding and 1 following——包括前2行、本行和下一行
3、案例说明
现有一张2020年某店铺各个月份商品的销售数量情况统计表,表名为sale:

下面我们来试一试,当同时执行不同的窗口函数时,会出现什么样的效果。
select *,
sum(销售数量) over(order by 月份) as sum_value,
avg(销售数量) over(order by 月份) as avg_value,
max(销售数量) over(order by 月份) as max_value,
min(销售数量) over(order by 月份) as min_value,
count(销售数量) over(order by 月份) as count_value
from sale;
得到如下结果:
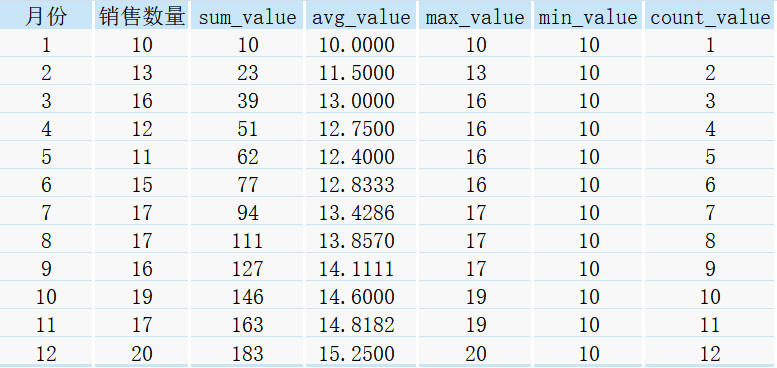
下面分别介绍每种结果的计算过程:
①sum作为窗口函数:
sum作为窗口函数,其计算的值 = 自身对应的数据 + 自身之上所有的数据
直接上图,大家理解起来可能更加容易!!!
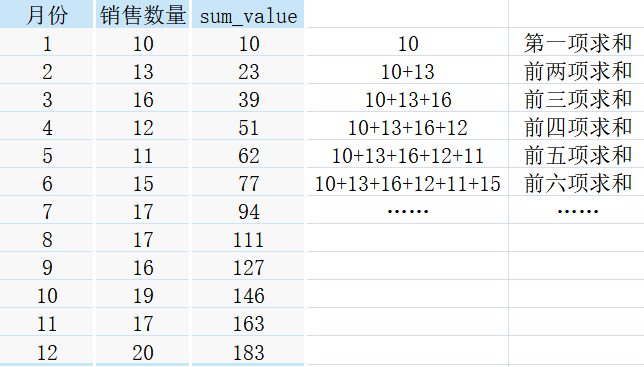
根据上图的计算过程,想必大家已经直观的体会到sum作为窗口函数是怎么使用的了吧。
②avg作为窗口函数:
avg作为窗口函数,其计算的值 = (自身对应的数据 + 自身之上所有的数据)/ 数据个数
简单粗暴,直接上图!!!

唉,我去?avg不就是根据sum计算的结果得来的吗。没错,不过当你回过头去看看count计算的结果之后,你会发现,avg计算的值其实就是sum计算的值 / count计算的值。
③max作为窗口函数:
max作为窗口函数,其实就和拍卖商品一个道理,比比谁大就完事了
图来!!!

看到这里,相信有着聪明小脑瓜的你已经明白聚合函数作为窗口函数是怎么使用的了,其它两个聚合函数的使用方法就不做过多介绍了, 在这里引用一位梗王的口头禅:
Don’t say so much(无需多言) ———这街3.霹雳小鸡
二、分区排序窗口函数row_number()、rank()、dense_rank()
1、应用场景
1、top N问题,即解决每一个分组中最大或最小的N条记录
2、分组排名问题
2、语法结构
1、row_number() over(partition by 字段名A order by 字段名B )
2、rank() over(partition by 字段名A order by 字段名B )
3、dense_rank() over(partition by 字段名A order by 字段名B )
3、案例说明
现有一张班级各科成绩表score,如下所示:
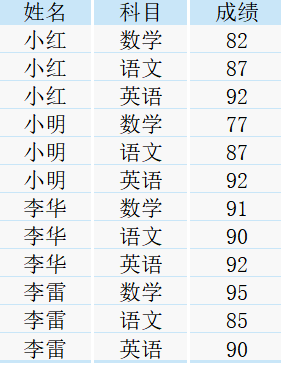
下面我们来试一试,当同时执行不同的窗口函数时,会出现什么样的效果。
select *,
row_number() over(partition by 科目 order by 成绩 desc) as row_number_val,
rank() over(partition by 科目 order by 成绩 desc) as rank_val,
dense_rank() over(partition by 科目 order by 成绩 desc) as dense_rank_val
from score;
执行上述SQL后,得到如下结果:
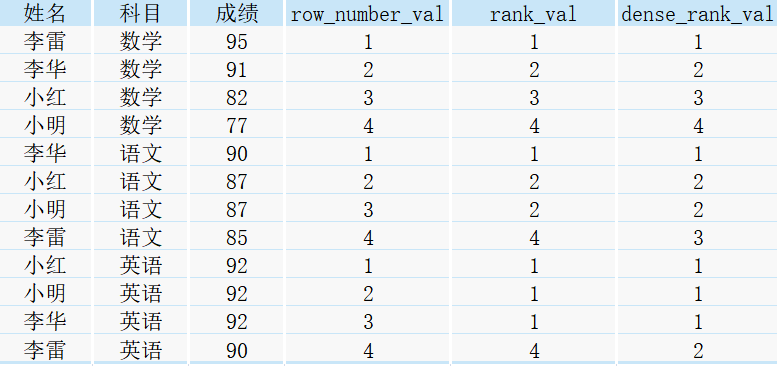
由于我们设置了partition by 科目 order by 成绩 desc,所以上述结果首先按照科目进行分组,再按照成绩由高到低进行排序。
我们单拿出英语科目的结果来比较row_number()、rank()、dense_rank()三者的不同

① row_number():会为每一行记录都生成一个序号,依次进行排序且不会重复,形如1、2、3、4
② rank():会将记录相同的行排成相同的序号,且进行跳跃式的排序,如有三行序号为1时,接下来的行序号就为4,即第二行和第三行中的序号1各占了一个位置,形如1、1、1、4
③ dense_rank():会将记录相同的行排成相同的序号,且进行连续排序,如有三行序号为1时,接下来的行序号就为2,形如1、1、1、2
三、分组排序窗口函数ntile()
1、应用场景
1、将数据按照某一字段进行分组
2、分组排名,取前N%,注意区分和取top N不同
2、语法结构
ntile(n) over(partition by 字段名A order by 字段名B )
其中,n为分的组数。
3、案例说明
现有一张表student,里面包含了学号、科目以及对应的考试成绩
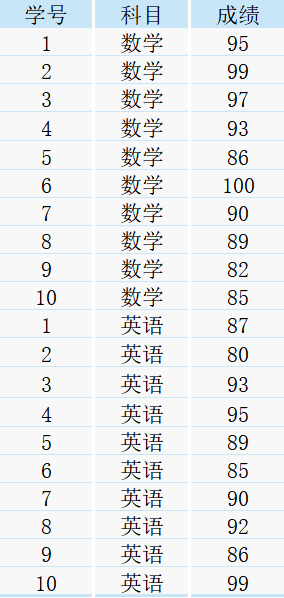
需求1:将各科目按照成绩高低分成五组
select *,
ntile(5) over(partition by 科目 order by 成绩 desc) as level
from student;
得到如下结果:
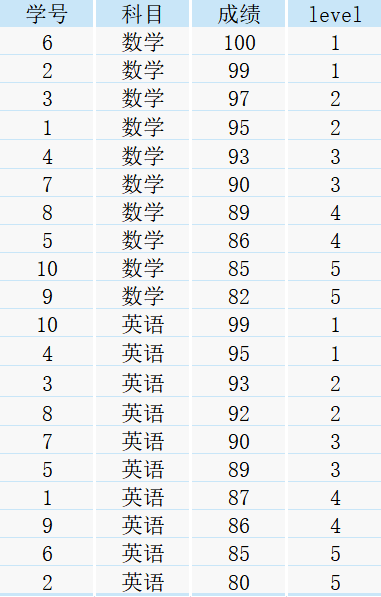
分析:由于我们的需求是将各科目按照成绩高低进行分组,所以设置了partition by 科目 order by 成绩 desc,分的组数为5组,所以,ntile(n)里的参数n直接设置为5。
需求2:将各科目按照成绩高低排序,取出前20%的数据
select a.*
from
(select *,
ntile(5) over(partition by 科目 order by 成绩 desc) as level
from student) a
where a.level = 1;
得到如下结果:
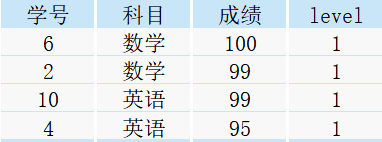
分析:由于每个科目都各有10条记录,我们取前20%的数据,这里引用小学(不知道是几年级)的计算公式可得:20% × 10 = 2,所以我们按照成绩高低进行排序后,取每个科目的前两条记录即可。因此该需求依旧是需要对数据进行分组,然后取序号为1的记录。
总结:
1、ntile(n) 用于将数据按照某一顺序进行分组,并返回组号;
2、若分组后每组中的数据个数不均匀,会把最后面组中多出来的数据分到第一组中;
3、n为一个正整数。
四、偏移分析窗口函数lag()、lead()
1、应用场景
1、取时间间隔为N天的记录
2、求本次记录与上一次记录的差值
3、取某一字段的前N行数据或后N行数据
2、语法结构
lag(字段A,偏移量,默认值) over(partition by 字段B order by 字段C)
lead(字段A,偏移量,默认值) over(partition by 字段B order by 字段C)
其中:
① 字段A:操作字段名称;
② 偏移量:假设当前记录所在的行是第6行,当使用lag()窗口函数时,若将偏移量设置为2,则表示要找的记录所在的行是(6-2)= 4。可不写此参数,默认偏移量为1;
③ 默认值:当向上或者向下取值超过表的范围时,两个函数会将默认值参数对应的值作为函数的返回值。可不写此参数,当超过表范围时,默认返回NULL;
3、案例说明
现有一张客户A的消费记录明细表customer,里面包含了客户A每次消费的时间。

当分别执行偏移分析窗口函数时:
select *,
lag(dt,1,dt) over(order by dt),
lag(dt) over(order by dt),
lead(dt,1,dt) over(order by dt),
lead(dt) over(order by dt)
from customer;
得到如下结果:

用法分析: lag()为向上偏移、lead为向下偏移。
其对应关系如下表所示:

若求当前记录与上1次记录或者下1次记录的差值时,利用lag()或lead()窗口函数即可实现
select *,
lag(dt,1,dt) over(order by dt) as lag_dt,
datediff(dt,lag_dt) as dt_diff_lag
lead(dt,1,dt) over(order by dt) as lead_dt,
datediff(lead_dt,dt) as dt_diff_lead
from customer;
得到如下结果:

五、结语
最后祝大家SQL学习之路越来越顺利,博主也会定期更新数据分析、数据挖掘、机器学习算法、深度学习算法的学习笔记哦,我也经历了这个过程,懂得大家的需求点,保证都是总结出来的干货,欢迎关注,一起进步!!!
