利用xpath爬取链家租房房源数据并利用pandas保存到Excel文件中
我们的需求是利用xpath爬取链家租房房源数据,并将数据通过pandas保存到Excel文件当中
下面我们看一下链家官网的房源信息(以北京为例)
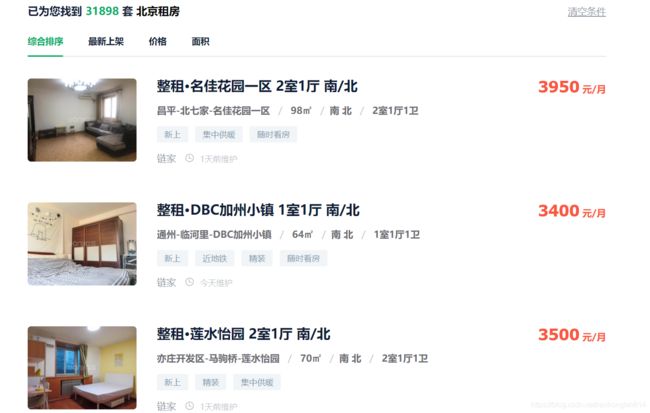
如图所示,我们通过筛选得到北京租房信息
那么我们需要将房屋所在地区、小区名、户型、面积、朝向、价格等信息通过爬虫提取出来。
思路步骤:
1.通过翻阅我们查看到总共页数一共是100页,那么我们需要通过format方法获取到这100个url地址列表url_list;
2.遍历url列表,分别发送请求,获得响应html_str;
3.利用xpath得到element对象,对element对象采用xpath方法得到每个房屋element组成的列表det_dicts;
4.遍历det_dicts,将房屋所在地区、小区名、面积、户型、朝向、价格等信息保存到空字典info_dicts中;
5.注意,这里我们事先创建一个columns=[‘地区’,‘小区名’,‘面积’,‘户型’,‘朝向’,‘价格(元/月)’]的空DataFrame对象data,再创建另外一个DataFrame对象df,将字典info_dicts传入到df中,通过append方法将df添加到data中;
6.通过主程序运行后,就可以将DataFrame保存到Excel文件中
得到的结果部分如下:

详细代码如下:
```python
import requests
import pandas as pd
from lxml import etree
class LianjiaSpider():
def __init__(self):
self.url = 'https://bj.lianjia.com/zufang/pg{}/'
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36'}
def get_url_list(self):
'''获取url列表'''
url_list = [self.url.format(i) for i in range(1,101)]
return url_list
def get_response(self,url):
'''发送请求,获取响应'''
response = requests.get(url,headers=self.headers)
html_str = response.content.decode()
return html_str
def get_data(self,html_str):
'''获取所需要的数据'''
element = etree.HTML(html_str)
det_dicts = element.xpath('//div[@class="content__list"]/div')
data = pd.DataFrame(columns=['地区','小区名','面积','户型','朝向','价格(元/月)'])
for room in det_dicts:
info_dicts = {}
info_dicts['地区'] = room.xpath('.//p[@class="content__list--item--des"]/a/text()')[0]
info_dicts['小区名'] = room.xpath('.//p[@class="content__list--item--des"]/a/text()')[2]
info_dicts['面积'] = room.xpath('.//p[@class="content__list--item--des"]/text()')[4].strip()
info_dicts['户型'] = room.xpath('.//p[@class="content__list--item--des"]/text()')[6].strip()
info_dicts['朝向'] = room.xpath('.//p[@class="content__list--item--des"]/text()')[5].strip()
info_dicts['价格(元/月)'] = room.xpath('.//span[@class="content__list--item-price"]/em/text()')
df = pd.DataFrame(info_dicts,index=[0])
data = data.append(df)
return data
def run(self):
'''主运行程序'''
# 1.获取url列表
need_data = pd.DataFrame(columns=['地区','小区名','面积','户型','朝向','价格(元/月)'])
url_list = self.get_url_list()
for url in url_list:
# 2.发送请求,获取响应
html_str = self.get_response(url)
# 3.获取所需要的数据
data = self.get_data(html_str)
# 4.保存数据
need_data = need_data.append(data)
need_data.to_excel('./链家北京租房房源数据.xls',index=False)
if __name__ == '__main__':
lianjia = LianjiaSpider()
lianjia.run()