sql sum排序_最全SQL窗口函数指南—数据分析面试必备

在笔者比较早期的面试经历中,面试官经常会出一些 SQL 题,而其中最常见的就是那些需要用 窗口函数 来解题的。
后来在笔者作为面试官面试候选人时,也是常常把窗口函数作为考察点。所以掌握好 SQL 窗口函数还是很必要的。

接下来我们按照顺序来介绍各种窗口函数。
一、组内排序函数:Rank/Dense_Rank/Row_Number
组内排序,我们常常用于取分组内排序前N/后N的记录,或先分组排序然后根据序号关联组内前一条或后一条记录。
Row_Number() over(partition by col1 order by col2):数字相同序号不重复,序号最大值等于总记录数;
Rank() over(partition by col1 order by col2):数字相同序号会重复,重复值后会跳过某些序号,序号最大值仍等于总记录数;
Dense_Rank() over(partition by col1 order by col2):数字相同序号会重复,重复值后不跳过某些序号,序号最大值会小于记录数。
示例,假定有如下一张表 test,执行下述 SQL 输出结果:
| ID | Name | Sal |
|---|---|---|
| 1 | a | 10 |
| 2 | a | 12 |
| 3 | b | 13 |
| 4 | b | 12 |
| 5 | a | 14 |
| 6 | a | 15 |
| 7 | a | 13 |
| 8 | b | 11 |
| 9 | a | 16 |
| 10 | b | 17 |
| 11 | a | 14 |
Select
name, sal,
row_number() over(partition by name orderby sal desc) rnk1,
rank() over(partition by name order by sal desc) rnk2,
dense_rank() over(partition by name order by sal desc) rnk3
From test| Name | Sal | rnk1 | rnk2 | rnk3 |
| b | 17 | 1 | 1 | 1 |
| b | 13 | 2 | 2 | 2 |
| b | 12 | 3 | 3 | 3 |
| b | 11 | 4 | 4 | 4 |
| a | 16 | 1 | 1 | 1 |
| a | 15 | 2 | 2 | 2 |
| a | 14 | 3 | 3 | 3 |
| a | 14 | 4 | 3 | 3 |
| a | 13 | 5 | 5 | 4 |
| a | 12 | 6 | 6 | 5 |
| a | 10 | 7 | 7 | 6 |
二、累计计数、求和函数:SUM/AVG/MIN/MAX
这类函数应用非常广泛。包括不使用 group by 即可分组聚合、分组内滚动聚合从第一行到当前行或分组内滚动聚合前N行到后N行。
以 sum 为例,它的函数公式为:sum() over(partition by col1 order by col2 rows between xxx and yyy)。
下面我们来看看这个例子,假设有如下日志表 log:
cookie1 2015-04-10 1
cookie1 2015-04-11 5
cookie1 2015-04-12 7
cookie1 2015-04-13 3
cookie1 2015-04-14 2
cookie1 2015-04-15 4
cookie1 2015-04-16 4
以下述代码来介绍各种使用场景:
select
cookieid, pv,
-- 从起点到当前行
sum(pv) over(partition by cookieid order by created) as pv1,
-- 从起点到当前行,结果同pv1
sum(pv) over(partition by cookieid order by created rows between unbounded preceding and current row) as pv2,
-- 分组内所有行
sum(pv) over(partition by cookieid) pv3,
-- 当前行往前3行 -> 当前行
sum(pv) over(partition by cookieid order by created rows between 3 preceding and current row) pv4,
-- 当前行往前3行 -> 当前行往后1行
sum(pv) over(partition by cookieid order by created rows between 3 preceding and 1 following) pv5,
-- 当前行往后所有行
sum(pv) over(partition by cookieid order by created rows between current row and unbounded following) as pv6
from log运行结果如下:
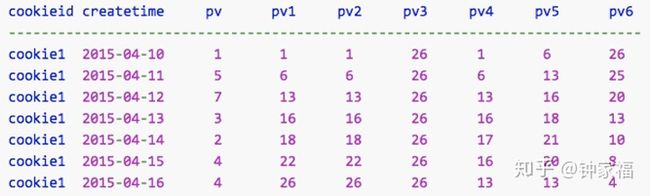
使用说明:
- 如果不指定rows between,默认为从起点到当前行;
- 如果不指定order by,那么将分组内所有值累加;
- row between 子句,也叫window子句:
preceding 往前;
following 往后;
current row 当前行;
unbounded 起点/终点:UNBOUNDED PRECEDING:表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点。
4. Avg、Count、Max、Min 等函数与 Sum 用法一样。
三、分桶函数:Ntile
分桶可用于便捷选择前/后N分之几的数据。
将有序的数据集平均分配到指定数量的桶内,并将桶号分配给每一条记录。如果不能平均分配,则优先分配给较小编号的桶,并且各个桶中能放的行数最多差1。
如,取上述示例 test 表 Sal 排名前50%的订单记录:
Select *
From(
Select Id, Name, sal,
Ntile(2) over(partition by name order by sal desc) nt
From test
)t where t.nt=1四、前后平移函数:Lag/Lead
前后平移可快捷计算同比、环比值;
Lag(col, n, DEFAULT) 用于统计窗口内往上第n行值;
Lead(col, n, DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反。
小 tips: default省略,则默认为NULL; 不需显式进行手动分组排序,在使用函数 LAG/LEAD 时最终呈现记录为自动排序。
示例:
如某张有 doctorid, patientid, add_time 3个字段的表,下列 2段 SQL 运行结果分别如下:
select
doctorid, patientid, add_time,
Lag(patientid, 1) over(partition by doctorid order by add_time) patient_bf
from stats.bi.nestle_patient 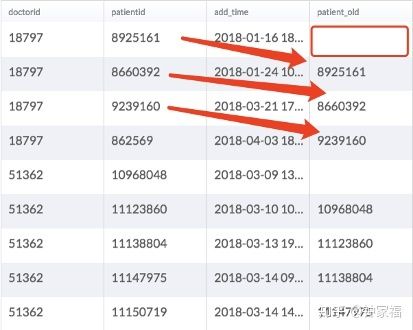
select
doctorid, patientid, add_time,
Lead(patientid, 1, 5188786) over(partition by doctorid order by add_time) patient_af
from stats.bi.nestle_patient 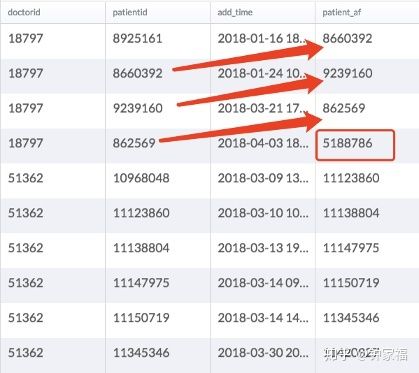
五、分组取最早、最迟函数:First_Value/Last_Value
分组取最早、最迟函数可用于取用户的首次行为时间、最后一次行为时间,计算生命周期。
First_Value():分组内排序后,获得组内当前行往前的首个值;
Last_Value():分组内排序后,获得组内当前行往前的最后一个值。
如某张有 doctorid, patientid, add_time 3个字段的表,下列 2段 SQL 运行结果分别如下:
select
doctorid, patientid, add_time,
First_Value(patientId) over(partition by doctorId order by add_time) first_patient,
Last_Value(patientId) over(partition by doctorId order by add_time) last_patient,
First_Value(patientId) over(partition by doctorId order by add_time desc) first_patient_desc
from stats.bi.nestle_patient
六、序列分析函数:CUME_DIST/ PERCENT_RANK
Cume_Dist:小于等于当前值的行数/分组内总行数。应用场景统计,用于收入订单前多少的排名,或者订单数 pk 百分比。注意:没有 partition ,所有数据分到同一组。
Percent_Rank:分组内当前行的RANK值-1/分组内总行数-1。暂时没有想到应用场景。
SELECT
year,
doctorId,
orders,
CUME_DIST() OVER(ORDER BY orders) AS rn1,
CUME_DIST() OVER(PARTITION BY year ORDER BY orders desc) AS rn2
FROM(
select date_trunc('year', payTime) year, doctorId, count(distinct id) orders
from subscriptionorder
where paystatus=2
group by doctorId, date_trunc('year', payTime)
)参考链接:http://www.cnblogs.com/wujin/p/6051768.html
参考资料:https://www.cnblogs.com/skyEva/p/5730531.html
以上为,SQL窗口函数。下一篇:SQL 索引及索引引发的查询优化。敬请期待。
希望对各位分析师老铁有帮助,欢迎评论区讨论。最后还请各位看官收藏不忘点赞。