把「我的世界」马赛克变成逼真大片,英伟达又出黑科技
子豪 发自 凹非寺
量子位 报道 | 公众号 QbitAI
先来看一张海岛大片:
这可不是哪个摄影师的杰作,而是出自GANcraft之手。
原图是「我的世界」中一个马赛克画质的场景:

这下「我的世界」真的变成了,我的世界!
GANcraft由英伟达和康奈尔大学合作完成,它是一个无监督3D神经渲染框架,可以将大型3D块状世界生成为逼真图像。

空前的真实感
究竟有多逼真?和与其他模型对比来看。
以下是在两个场景中,分别使用MUNIT、GauGAN用到的SPADE、wc-vid2vid,以及NSVF-W(NSVF+NeRF-W)生成的效果。
再感受下GANcraft的效果:(画质和色彩有所压缩)
通过对比可以看到:
诸如MUNIT和SPADE这类im2im(图像到图像转换)方法,无法保持视角的一致性,这是因为模型不了解3D几何形状,而且每个帧是独立生成的。
wc-vid2vid产生了视图一致的视频,但是由于块状几何图形和训练测试域的误差累积,图像质量随着时间迅速下降。
NSVF-W也可以产生与视图一致的输出,但是看起来色彩暗淡,且缺少细节。
而GANcraft生成的图像,既保持了视图一致性,同时具有高质量。
这是怎么做到的?
原理概述
GANcraft中神经渲染的使用保证了视图的一致性,而创新的模型架构和训练方案实现了空前的真实感。
具体而言,研究人员结合了3D体积渲染器和2D图像空间渲染器,使用Hybird体素条件神经渲染方法。

首先,定义一个以体素(即体积元素)为边界的神经辐射场,并且为块的每个角,分配一个可学习的特征向量;
再使用三线性插值法,在体素内的任意位置定义位置代码,把世界表示为一个连续的体积函数;并且每个块都被分配了一个语义标签,如泥土、草地或水。
然后,使用MLP隐式定义辐射场,将位置代码、语义标签和共享的样式代码作为输入,并生成点特征(类似于辐射)及其体积密度。
最后给定相机参数,通过渲染辐射场获得2D特征图,再利用CNN转换为图像。
虽然能够建立体素条件神经渲染模型,但是没有图像能用作ground truth,为此,研究人员采用了对抗训练方式。
但是「我的世界」不同于真实世界,其街区通常具有完全不同的标签分布,比如:场景完全被雪或水覆盖,或是多个生物群落出现在一个区域。
在随机采样时,使用互联网照片进行对抗训练,会生成脱离实际的结果:

因此研究人员生成Pseudo-ground truth,用来进行训练。
使用预训练的SPADE模型,通过2D语义分割蒙版,获得具有相同语义的Pseudo-ground truth图像。
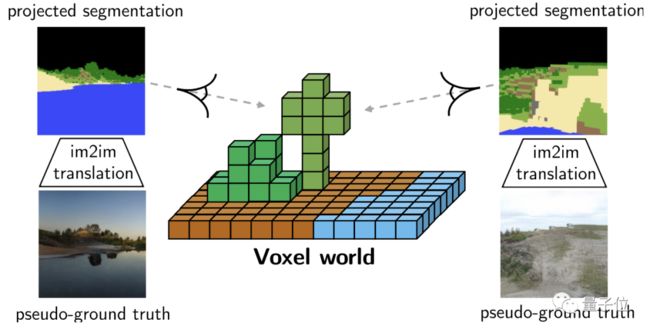
这不仅减少了标签和图像分配的不匹配,而且还能用更强的损失,来进行更快、更稳定的训练。生成效果得到了显著改善:

此外,GANcraft还允许用户控制场景语义和输出风格:
其介绍页中提到:它将每个Minecraft玩家变成了3D艺术家!
并且,简化了复杂风景场景的3D建模过程,无需多年的专业知识。
GANcraft即将开源,感兴趣的读者可戳链接了解详情~
参考链接:
[1]https://nvlabs.github.io/GANcraft/
[2]https://arxiv.org/abs/2104.07659
[3]https://news.ycombinator.com/item?id=26833972
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
加入AI社群,拓展你的AI行业人脉
量子位「AI社群」招募中!欢迎AI从业者、关注AI行业的小伙伴们扫码加入,与50000+名好友共同关注人工智能行业发展&技术进展:
