使用爬虫爬取超星学习通的作业时间并且通过邮件提醒
简介
因为本人十分爱忘记做作业,因此,想通过爬虫,爬取超星的学习通作业时间,并且进行定时提醒。
环境
- 阿里云轻量级服务器
- Centos7
- Anaconda3
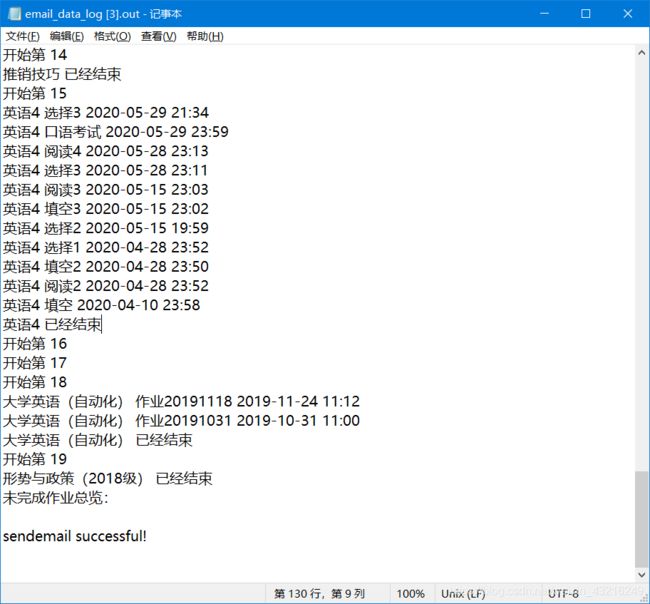
先看效果展示
爬取过程
发送邮件

过程
需要了解的知识
- http的访问机制
- cookies,session是用来干嘛的
- 验证码登录的流程
- 页面的机制
- python几个包的使用
- requetst(网页请求包)
- lxml,etree(网页界面处理包)
- email,smtplib(邮件处理包)
- muggle-ocr(验证码识别)
- datetime和time(时间包)
- Centos下的anaconda的使用
- stmp邮件协议讲解
- Centos如何进行定时任务
- Centos关于邮件发送的端口
开始
(对于部分模块,有些博客写的非常好,我就不进行详述,但是会提供链接)
1.http的访问机制
一文搞懂HTTP协议(带图文)
2.cookies,session是用来干嘛的
cookie和session的区别
session和cookies的区别
3. 验证码登录的流程
验证码的原理及作用
简单来说(以超星学习为例子):
- 每此进入登录页面,它会先请求一个验证码的网址(不用管它code?***是什么。,它只是一个通过js的datetime函数的到的一个时间戳(不明白的同学可以去搜一搜)。不要太在意这部分,一开始,我就走入歧途,想通过这个来获取验证码,其实思路就错了,应以为戒)
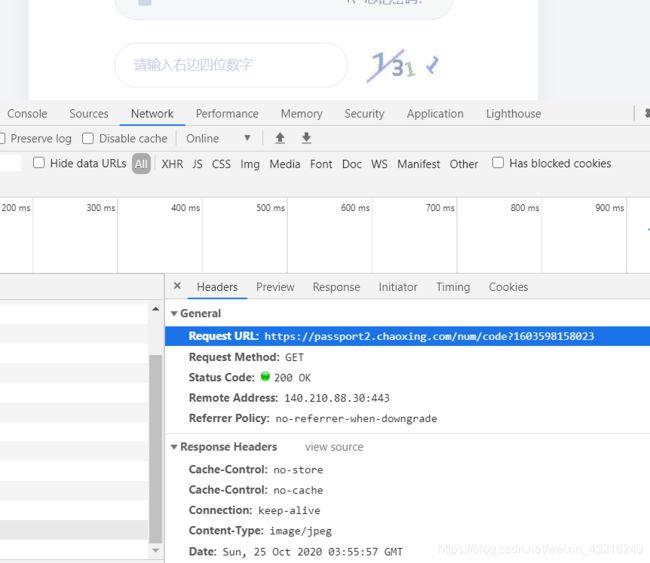
进入该链接之后,得到一张图片

此时,表面上得到的是一张图片,实际上,在服务器端,它还生成了与之匹配的cookies信息,并且返回给了登录页面。而之后我们客户端就必须携带这个cookies以及账号密码信息进行访问。
4. 页面的机制
使用的chrome浏览器,打开F12就可以了解整个页面的转换过程。主要分为:
- html静态网页(容易获取)
- js后台操作函数(通过相关函数来进行动态加载显示页)
就比如这里的验证码图片,并不是静态加载的,因此直接获取到的html中并没有该图片的链接,反而是通过一个函数进行动态加载。


打开F12后主要页面如下:
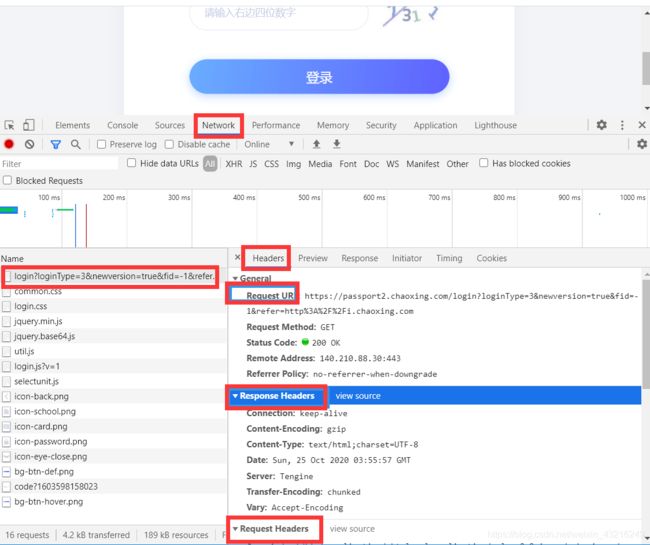
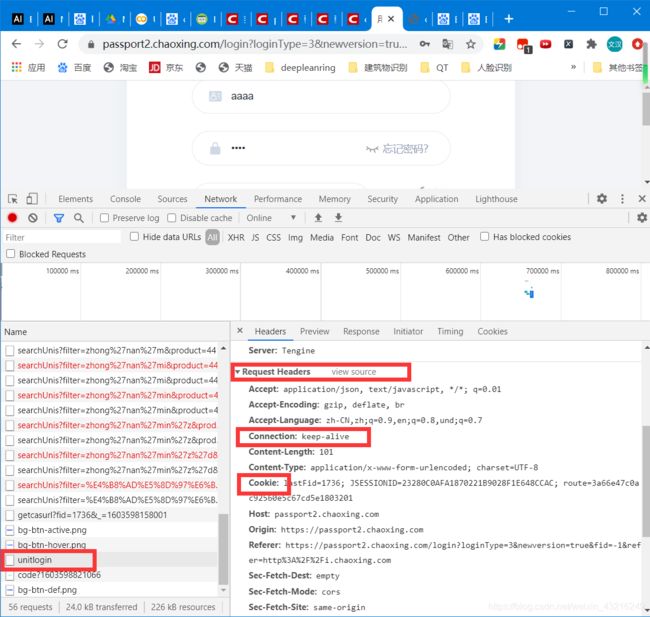
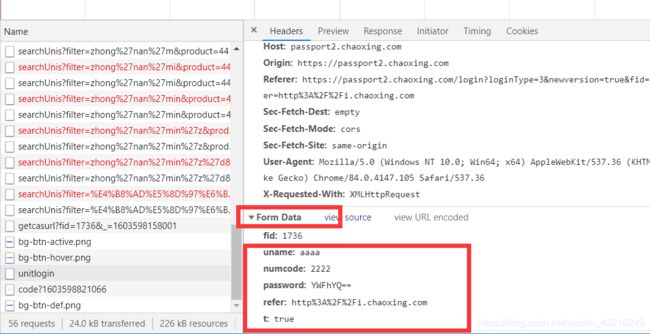
在最后的图中的formdata就是本次登录的信息(账号,密码(base64加密),验证码等)
python几个包的使用
- requetst(网页请求包)
python3下使用requests实现模拟用户登录 —— 基础篇(马蜂窝)
python requests模拟登陆带验证码的网站
还有我的另外几篇博客也说明了用法
Python网络爬虫 一、requests的用法详解 - lxml,etree(网页界面处理包)
lxml库之etree使用小结
Python网络爬虫 二、Xpath语法详解 - email,smtplib(邮件处理包)
Python 发送 email 的三种方式
Python SMTP发送邮件
这里要注意的是阿里云服务器是关闭了25端口的(常用邮件发送端口),因此,当部署在服务器上时,方法一需要进行25端口的解封,方法二改用465端口加上ssl证书(本用法)
使用qq邮箱转发
sftp_obj = smtplib.SMTP_SSL('smtp.qq.com', 465)
- muggle-ocr(验证码识别)
【附源码模型】战网验证码识别
pytesseract败北?轻量级muggleOCR问世,同时支持印刷字和验证码识别- datetime和time(时间包)
datetime 模块详解(基本的日期和时间类型)
- datetime和time(时间包)
6. Centos下的anaconda的使用
YOLOv3-药草识别实现(里面提到了,亲测可用)
CentOS 7安装Anaconda3
7. stmp邮件协议讲解
stmp邮件协议讲解
8. Centos如何进行定时任务
Centos7环境下对Crontab的使用以及问题(Anaconda+python脚本)
代码
#coding=UTF-8
#File name :爬虫超星
#Author:龙文汉
#Data:2020.10.16
#Description:使用爬虫爬取超星的作业详情,获取作业的截至时间
import time
import json
import requests
from lxml import etree
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import os
import base64
import datetime
import smtplib
from email.header import Header
from email.mime.text import MIMEText
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
import threading
import sys
import muggle_ocr
class PaChaongxin():
#main_function
def __init__(self,username,password,emai):
self.username = username
self.password = password
self.to = emai
self.code = 0
self.code_status = None #验证码正确还是失败
self.user_pas_status = None #账户名和密码
self.sender_mail = 'xxxx@xxx'#发送者邮件
self.sender_pass = 'xxxxxxx' # 邮箱的stm密码
self.session = requests.session()
self.header = {
'User-Agent': 'xxxxxxxx'#自己的user_agent
}
def User_Pas(self):
#输入账号,密码
# self.username = input("请输入学号:")
# self.password = input("请输入密码:")
# self.to = input("请输入邮箱:")
#self.username = xxxxxxx
#self.password = 'xxxxx'
#self.to = 'xxxxxx'
return
def Get_code(self):
#获取验证码,以及携带的cookies
code_url = 'https://passport2.chaoxing.com/num/code'#超星验证码网址
path_path = 'vari_code.png'
code_response = self.session.get(code_url)
#保存验证码
img = open(path_path,'wb')
img.write(code_response.content)
img.close()
#显示验证码,并且初始化,人为输入,不适用识别程序
# img_open = Image.open('vari_code.png')
# img = mpimg.imread('vari_code.png',0)
# plt.imshow(img) # 显示图片
# plt.axis('off') # 不显示坐标轴
# plt.show()
# self.code = input("请输入验证码:")
print("befor:",self.code)
self.code = self.Code_Verifed()
print("after:", self.code)
os.remove(path_path)
def Load_Page(self):
#使用session进入登录界面验证
self.password = base64.b64encode(self.password.encode("utf-8")) # 被编码的参数必须是二进制数据
param = {
'fid': 'xxxx',
'uname': self.username,
'numcode': self.code,
'password': self.password,
'refer': 'http%3A%2F%2Fi.chaoxing.com',
't': 'true'
}
header = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,und;q=0.7',
'Connection': 'keep-alive',
'Content-Length': '109',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'passport2.chaoxing.com',
'Origin': 'https://passport2.chaoxing.com',
'Referer': 'https://passport2.chaoxing.com/login?loginType=3&newversion=true&fid=-1&refer=http%3A%2F%2Fi.chaoxing.com',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'xxxxxxxx',#注意自己更改
'X-Requested-With': 'XMLHttpRequest',
}
load_url = 'https://passport2.chaoxing.com/unitlogin?'
load_response = self.session.post(load_url,headers=header,data=param)
load_response_msg = json.loads(load_response.text)
print(load_response_msg,load_response_msg.keys())
if 'mes' in load_response_msg.keys():
if load_response_msg['mes'] == '验证码错误':
print('验证码错误')
self.code_status = True
while(self.code_status):
self.Get_code()
param['numcode'] = self.code
load_response = self.session.post(load_url, headers=header, data=param)
load_response_msg = json.loads(load_response.text)
if 'mes' not in load_response_msg.keys() or load_response_msg['mes'] != '验证码错误':
self.code_status = False
if 'mes' in load_response_msg.keys() and load_response_msg['mes'] == '用户名或密码错误':
print('用户名或密码错误')
self.user_pas_status = True
while(self.user_pas_status):
self.User_Pas()
self.Get_code()
param['numcode'] = self.code
param['uname'] = self.username
param['password'] = self.password
load_response = self.session.post(load_url, headers=header, data=param)
load_response_msg = json.loads(load_response.text)
if 'mes' not in load_response_msg.keys() and load_response_msg['mes'] != '用户名或密码错误':
self.code_status = False
#上面返回的应该是登录成功,接下来,带着新的cookies访问主页
self_page_url = 'http://i.mooc.chaoxing.com'
self_page_response = self.session.get(url=self_page_url,headers = self.header)
#个人空间的主页面,这里直接提取课程的部分,要在左侧的按钮里找到相对应的连接,
#该课程的页面直接镶嵌在本页面,所以带着session直接访问也可以
# self_page_html = etree.HTML(self_page.text)
# return self_page_html
def Get_Class_View(self):
#进入所有课程的界面
class_view_url = 'http://mooc1-2.chaoxing.com/visit/courses'
class_view = self.session.get(class_view_url,headers = self.header)
class_view_html = etree.HTML(class_view.text)
#直接返回整个页面的编码,方便后续的查找
return class_view_html
def Go_to_work(self,Singel_Class_Url_after):
#通过外面直接传来的课程网址,直接跳转
#进入单个课程的界面的作业模块
Singel_Class_Url = 'https://mooc1-2.chaoxing.com'+Singel_Class_Url_after
single_class_response = self.session.get(Singel_Class_Url,headers=self.header)
single_class_page = etree.HTML(single_class_response.text)
url_after = single_class_page.xpath("/html/body/div[4]/div/div/div[2]/ul/li[6]/a/@data")
if len(url_after) == 0:
open_zuoye_url = 'https://mooc1-2.chaoxing.com' + \
single_class_page.xpath("/html/body/div[2]/div/div/div[2]/ul/li[6]/a/@data")[0]
else:
open_zuoye_url = 'https://mooc1-2.chaoxing.com' + \
single_class_page.xpath("/html/body/div[4]/div/div/div[2]/ul/li[6]/a/@data")[0]
work_xml_response = self.session.get(open_zuoye_url,headers=self.header)
work_xml = etree.HTML(work_xml_response.text)
#这里的open_zuoye直接转到了作业的界面
#调用每个作业的函数,方便多线程
single_class_text = self.Get_work_time(work_xml)
return single_class_text
def Get_work_time(self,work_xml):
# 以上就是关于页面跳转的函数,接下来就是作业的截取
#作业的信息提取
work_num = len(work_xml.xpath('//*[@id="RightCon"]/div/div/div[2]/ul/li'))
class_name = work_xml.xpath('/html/body/div[2]/div/h1/span[1]/@title')[0]
#邮件的内容:[[课程],[作业名称,截至时间,剩余时间]*n]的列表
#无作业的课程直接返回
if work_num == 0:
return None
work_text_info = []#有作业的课程
work_text_info.append(class_name)#添加课程名
#对每个项目进行整理
for i in range(1,work_num+1):
work_name = work_xml.xpath('//*[@id="RightCon"]/div/div/div[2]/ul/li['+str(i)+']/div[1]/p/a/text()')[0].strip()
work_status = work_xml.xpath('/html/body/div[3]/div[1]/div/div/div/div[2]/ul/li['+str(i)+']/div[1]/span[3]/strong/text()')[0].strip()
work_end_time = work_xml.xpath('//*[@id="RightCon"]/div/div/div[2]/ul/li['+str(i)+']/div[1]/span[2]/text()')
# print(work_end_time)
if len(work_end_time) == 0:#无截至日期的课程
break
else:
work_end_time = work_end_time[0]
print(class_name,work_name,work_end_time)
if work_status != '已完成' and work_status != "待批阅":#存在未完成的课程
work_text_info.append([])
#增加作业名
work_text_info[-1].append(work_name)
#使用datatime,计算时间差
current_time = time.strftime("%Y-%m-%d %H:%M", time.localtime())
#转化位datatime的格式
current_time_tran = datetime.datetime.strptime(current_time ,"%Y-%m-%d %H:%M")
work_end_time_tran = datetime.datetime.strptime(work_end_time ,"%Y-%m-%d %H:%M")
if work_end_time_tran<current_time_tran:
work_text_info[-1].append("你没做的,已经过期了!")
break
time_mul = work_end_time_tran - current_time_tran
time_mul_day = time_mul.days
time_m, time_s = divmod(time_mul.seconds, 60)
time_h, time_m = divmod(time_m, 60)
lea_time =str(time_mul_day)+'天:'+str(time_h)+'小时:'+str(time_m)+'分钟'
work_text_info[-1].append(lea_time)
print(class_name,"已经结束")
#返回单课程的作业信息
return work_text_info
def Code_Verifed(self):
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
with open(r'vari_code.png', 'rb') as f:
captcha_bytes = f.read()
code = sdk.predict(image_bytes=captcha_bytes)
return code
def send_email_by_qq(self,text):
# 利用邮箱发邮件提醒
# 设置总的邮件体对象,对象类型为mixed
msg_root = MIMEMultipart('mixed')
# 邮件添加的头尾信息等
msg_root['From'] = 'xxxx@xxxxx'
msg_root['To'] = self.to
# 邮件的主题,显示在接收邮件的预览页面
subject = '快到作业截止时间了!'
msg_root['subject'] = Header(subject, 'utf-8')
# 构造文本内容
text_inf = "未完成作业总览:\n"
for i in range(0,len(text)):
text_inf += text[i][0]+"\n"#添加标题
for x in range(1,len(text[i])):
text_inf += '\t\t'
text_inf += str(text[i][x])
text_inf += "\n\n"
text_sub = MIMEText(text_inf, 'plain', 'utf-8')
print(text_inf)
msg_root.attach(text_sub)
# # 构造超文本
# url = "https://blog.csdn.net/chinesepython"
# html_info = """
# 点击以下链接,你会去向一个更大的世界
#
# i am very galsses for you
# """% url
# html_sub = MIMEText(html_info, 'html', 'utf-8')
# # 如果不加下边这行代码的话,上边的文本是不会正常显示的,会把超文本的内容当做文本显示
# html_sub["Content-Disposition"] = 'attachment; filename="csdn.html"'
# # 把构造的内容写到邮件体中
# msg_root.attach(html_sub)
# # 构造图片
# image_file = open(r'D:\python_files\images\test.png', 'rb').read()
# image = MIMEImage(image_file)
# image.add_header('Content-ID', '')
# # 如果不加下边这行代码的话,会在收件方方面显示乱码的bin文件,下载之后也不能正常打开
# image["Content-Disposition"] = 'attachment; filename="red_people.png"'
# msg_root.attach(image)
# # 构造附件
# txt_file = open(r'D:\python_files\files\hello_world.txt', 'rb').read()
# txt = MIMEText(txt_file, 'base64', 'utf-8')
# txt["Content-Type"] = 'application/octet-stream'
# #以下代码可以重命名附件为hello_world.txt
# txt.add_header('Content-Disposition', 'attachment', filename='hello_world.txt')
# msg_root.attach(txt)
try:
sftp_obj = smtplib.SMTP_SSL('smtp.qq.com', 465)
sftp_obj.login(self.sender_mail, self.sender_pass)
sftp_obj.sendmail(self.sender_mail, self.to, msg_root.as_string())
sftp_obj.quit()
print('sendemail successful!')
except Exception as e:
print('sendemail failed next is the reason')
print(e)
def Begin(self):
self.User_Pas()#获取信息
self.Get_code()#获取验证码以及cookies信息,用session进行保存
self.Load_Page()#进入个人中心,更新cookies
class_view_html = self.Get_Class_View()#进入所有作业的单页面,并且返该界面
len_class = len(class_view_html.xpath('/html/body/div/div[2]/div[3]/ul/li'))#计算一共有多少个课程
all_text = []#总的邮件信息
for i in range(1,len_class):#开始遍历每门课
print('开始第',i)
Singel_Class_Url_after = class_view_html.xpath('/html/body/div/div[2]/div[3]/ul/li['+str(i)+']/div[2]/h3/a/@href')[0]
# print(Singel_Class_Url_after)
# all_text.append([threading.Thread(target=self.Go_to_work,args=(Singel_Class_Url_after)).start()])
work_text = self.Go_to_work(Singel_Class_Url_after)
if work_text == None or len(work_text) <= 1:
continue
else:
all_text.append(work_text)
#将没有作业的课程删除
return all_text
if __name__ == '__main__':
pachong = PaChaongxin(学号,密码,邮箱)
work_email = pachong.Begin()
pachong.send_email_by_qq(work_email)
总结
果然任务驱动加上兴趣的学习,能更加扩展知识面,本次实例,都了解了:爬虫知识,网络知识,密码学,云服务器的使用,邮件知识,python的使用。总体来说,收益匪浅。希望大家能共同进步