一.数据读取:
csv文件:csv_data= pd.read_csv('/路径/test.csv')
txt文件:f= open('/路径/test.txt', 'r')
excel文件:
import xlrd
f=xlrd.open_workbook(r'\路径\demo.xlsx',formatting_info=True)
table =data.sheet_by_name("Sheet2")
or
df = pd.read_excel("\路径\window regulator.xlsx",sheetname="Sheet2")
二.数据处理和清洗:
- 数据清洗:
A.调整数值及格式,去掉噪声,不可信值,缺失值较多的字段
1)去掉空格,换行符:
" xyz ".strip() # returns "xyz"
" xyz ".lstrip() # returns "xyz "
" xyz ".rstrip() # returns " xyz"
" x y z ".replace(' ', '') # returns "xyz"
2)用split断开再合上 ''.join(your_str.split())
3)用正则表达式来完毕替换: import re strinfo = re.compile('word') b = strinfo.sub('python',a)print b 输出的结果也是hello python
4)删除pandas DataFrame的某一/几列:
方法一:直接del DF['column-name']
方法二:采用drop方法,有下面三种等价的表达式:
i. DF= DF.drop('column_name', 1);
ii. DF.drop('column_name',axis=1,inplace=True)
iii. DF.drop([DF.columns[[0,1, 3]]],axis=1,inplace=True)
5)删除DataFrame某行
DataFrame.drop(labels=None,axis=0,index=None,columns=None, inplace=False)
在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1;inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了。
- 数据类型转换:
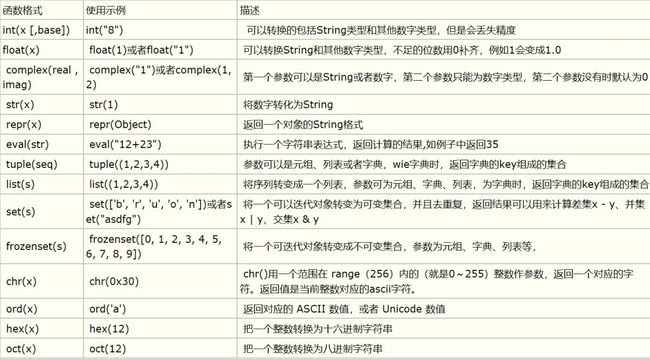
B.归一化处理,离散化处理,数据变换(log,0-1,exp,box-cox):
1)0-1标准化:这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理。
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x;
2)Z-score标准化:这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布,个人认为在一定程度上改变了特征的分布。
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x;
3)Sigmoid函数:Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,且在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0,是个人非常喜欢的“归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
def sigmoid(X,useStatus):
if useStatus:
return 1.0 / (1 +np.exp(-float(X)));
else:
return float(X);
4)变换数据范围:除了上述介绍的方法之外,另一种常用的方法是将属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现。
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
5)正则化:正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。正则化的主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
p-范数的计算公式:||X||p=(|x1|^p+|x2|^p+...+|xn|^p)^1/p
该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性。可以使用preprocessing.normalize()函数对指定数据进行转换,用processing.Normalizer()类实现对训练集和测试集的拟合和转换。
6)Box-cox变换(stats.boxcox):Box-Cox变换是Box和Cox在1964年提出的一种广义幂变换方法,是统计建模中常用的一种数据变换,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式,Box-Cox变换可以明显地改善数据的正态性、对称性和方差相等性,对许多实际数据都是行之有效的。
- 数据采样:
A.无放回的抽样
使用 random.sample
import random
idxTest = random.sample(range(nPoints),nSample)
得到的idxTest 是一个list形式
B.有放回的抽样
使用 random.choice (一次选一个)
BagSamples=50
for i in range(nBagSamples):
idxBag.append(np.random.choice(range(len(xTrain))))
choice直接选出的不是list
更多方法详见pandas.DataFrame.resample
三.特征工程: