后续会继续介绍, 主要有三种方式:
通过sampling技术,生成均衡的样本
调整算法,允许算法改变权重weight变得cost-sensitive。
采用集成学习思想, 将major类进行横向划分,形成小的均衡的样本集群。
Sampling技术
Sampling技术比较直观,就是怎么把样本变成均衡的。 我们知道不均衡数据, 最重要的还是收集minority数据。 但是一般这是一个长期的过程。 那么, 在不可能收集到minonrity的情况下, 只能通过“重复”或者产生“假”数据来增加数量,达到均衡。
这里假设是个两类问题, 不均衡就存在major类和minor类。
Sampling技术主要分成两大类:减少majior类达到数量均衡,叫undersampling, 另外一种增加minor类达到数量均衡,叫oversampling。
而undersampling又至少分成两种:一种随机的Resampling(with/without replacement), 另外一种是带border cleaning的,就是尽量避免选择临近对方的样本。
类似的, oversampling也分成两种, 一类是不生成合成(without-synthesize)数据的, 一类是合成数据的(with-synthesize)。当然,除了这主要的两类, 就是杂交(hybrid)的情况了。
1.Undersampling (downsampling):
1.1 Resampling (with/without replacement):
随机选部分majority和minority组合 (不再描述)。
1.2 With border cleaning
基于相邻(neighboring),聚类(clustering)等方法。
2.Oversampling (upsampling):
2.1 Resampling (with replacement & without synthesize)
随机重复minority和majority组合 (不再描述)。
2.2 With synthesize
线性插值(interpolate)。
3.Hybrid
3.1 With simulation & with border cleaning
先插值然后去除边界等。
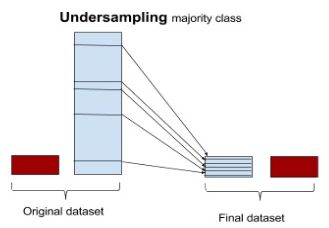
undersampling (downsampling) 因为减少了majority的样本数目, 所以潜在的风险是丢失了重要的数据, 很容易underfitting导致,使得泛化性能变差。
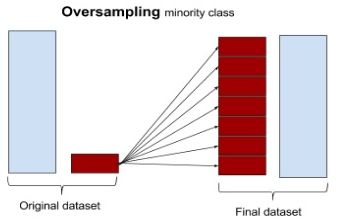
oversampling (upsampling) 重复了数据, 也存在风险使得部分数据过于强调,而overfitting, 另外还可能增加计算量。
带边界清理的UnderSampling with Border Cleaning
重要的技术也有两大类:
1. 边界相邻匹配:Tomek Links, NearMiss-T.
2. 聚类:Condensed Nearest Neighbor (CNN),Edited Nearest Neighbor (ENN)
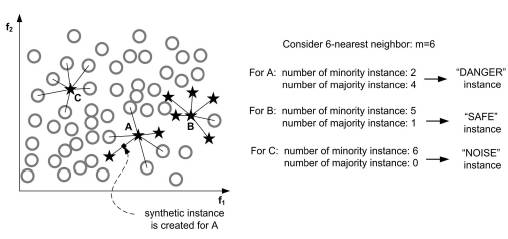
邻居的定义
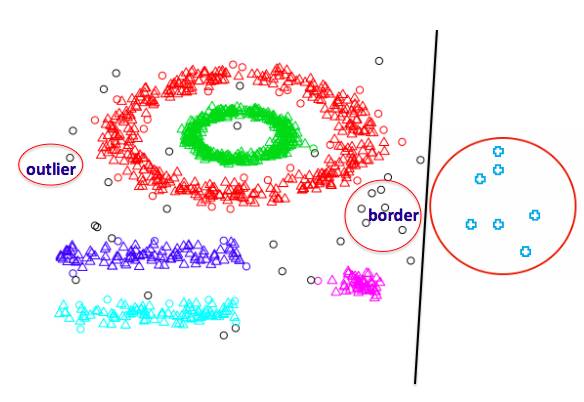
一般邻居大体分成三类: A点的kNN主要是其他类, 这个点就是边界点, DANGER情况, 比较难处理。 B点的kNN主要是自己类, 叫安全点SAFE。 如果kNN全是其他类, 那么自己就是Outlier,或者NOISE。
清理Tomek Links:
Tomek links是对于minority的点, 如果它的1NN刚好是majority,那么这就构成了一个Tomek Link, 在undersampling的情况下, 认为这个majority离的太近了, 就会删除这个majority点。
】
NearMiss-T系列算法
NearMiss是基于相邻思想的一系列算法, 有3个典型算法NM-1, NM-2, NM-3。
NearMiss-1:
对于每个majority的点, 找到它对应的在minority里面k个最近邻(Nearest Neighbor), 然后计算它到这个minority的kNN中心之间距离, 保留那些距离小的点。
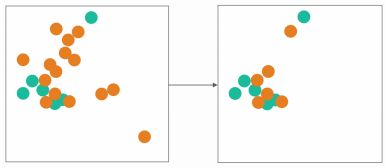
NearMiss-2:
刚好和NM-1相反, 它不是找minority里k个最近邻, 而是k个最远邻(Farthest Neighbor), 然后计算majority里面那个点到这个kFN中心之间的距离, 保留那些距离小的点。NM-2有点诡异,找的是最远的minority点,保留的小距离的majority点。
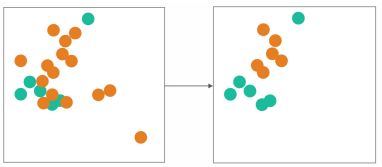
NearMiss-3:
和NM-1,和NM-3极大不一样的是, NM-3的k个点不是来自minority, 而是来自majority。 对于每个minority的点, 保留与该点最近的majority的kNN点。 k是可调节参数。 是不是刚好和Tomek Links相反。
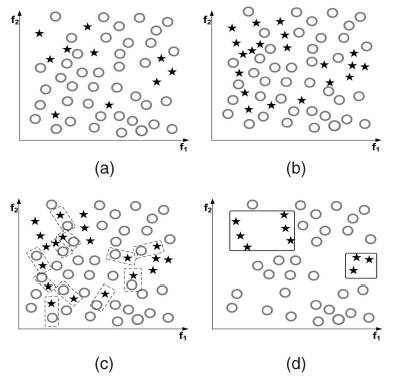
效果比较:
如下图,可以大致比较一下NM-T系列的效果。
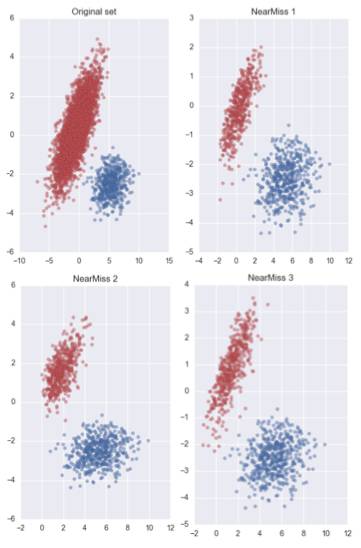
基于聚类的方法:
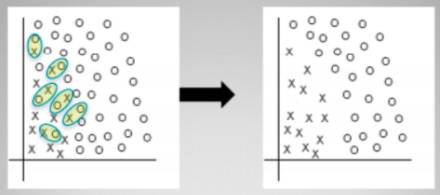
在解释聚类方法前, 再提一下, 非均衡的扩展,类别内部(inner-class)也是可以有非均衡的。 虽然同一个类, 但是有些特征比较稀少。 因此对于这种情况, 随机的undersampling会导致类别内非均衡性没有被照顾。 如下图, 同一个类别内,还是有不同特征的聚类。
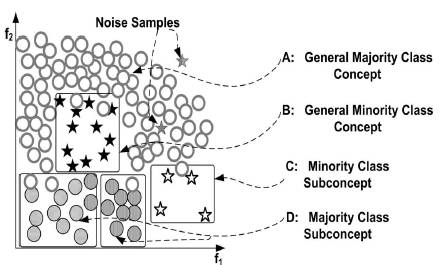
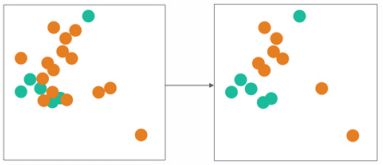
因此聚类方法就是, 将majority进行聚类, 然后找到代表性的类别进行抽样, 这样的好处是既能照顾类别内非均衡, 还能发现outlier和border。
Condensed Nearest Neighbor (CNN):
通过1NN来压缩majority, 就是找到训练集T的一个子集U,使得T中每个点, 它在U中1NN点都同一个类别就好了。

Edited Nearest Neighbor (ENN):
类似于Tomek Link的思想, 对于每个majority如果它的kNN投票结果不是majority就删除它。
其他更多的undersampling方法, 例如One-Sided Selection,Instance Hardness Threshold等,可以参考https://github.com/scikit-learn-contrib/imbalanced-learn/blob/master/README.rst
带合成的Oversampling技术 With synthesize
SMOTE -Synthetic Minority Oversampling Technique
最经典的SMOTE算法, 其实比较简单。
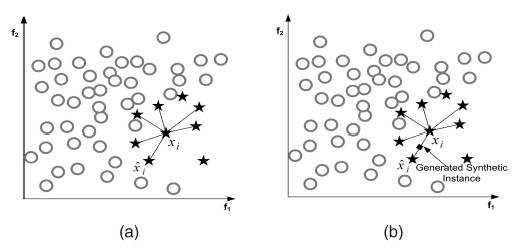
第一步, 随机选一个minority点,找它在minority中的kNN点。 然后再从kNN中随机标记一个点。
第二步, 线性差值上面两个点, 生成要的SMOTE点。
Borderline SMOTE
由于SMOTE没有考虑排除前面提到的SAFE, NOISE点的情况, 由于这些点性质明确,不需要合成数据了。 bSMOTE就是只用DANGER点进行合成。
ADASYN - Adaptive synthetic sampling approach for imbalanced learning
ADASYN把前面的SAFE, DANGER, NOISE点的简单划分变成了分布概率。 根据delta和K的比例按权重来合成。 delta就是KNN中属于majority的部分。
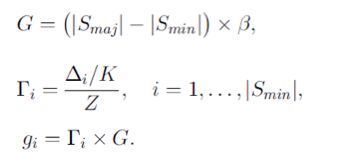
杂交 Hybrid
如果把SMOTE和前面的undersampling技术综合起来就是杂交的技术了。
一边合成minority的数据, 一边删除majority的数据,是不是要更快达到均衡。
SMOTE + Tomek
先合成SMOTE点, 然后根据Tomek思想去除Tomek links。
SMOTE +ENN 算法也是类似的。
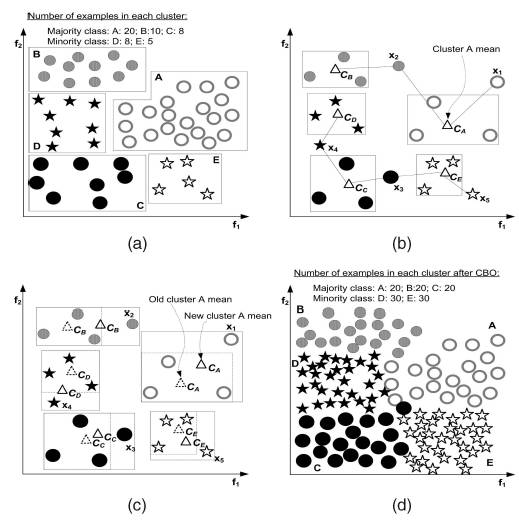
CBO - Clustering Based Oversampling
另外一种合成是, 先通过clutering只保留核心点, 然后通过合成技术进行oversampling。
Cost-Sensitive Learning
大部分分类算法, 允许安装class的比例来调整权重(weight), 而形成cost-senistive的学习, 譬如SVM, Random Forest。
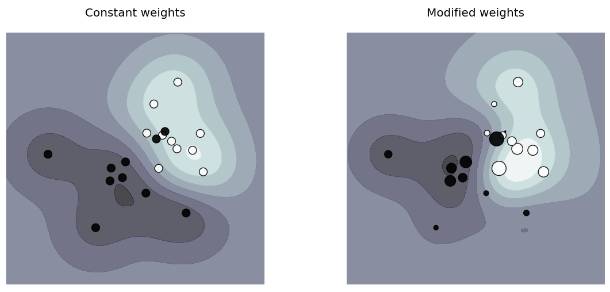
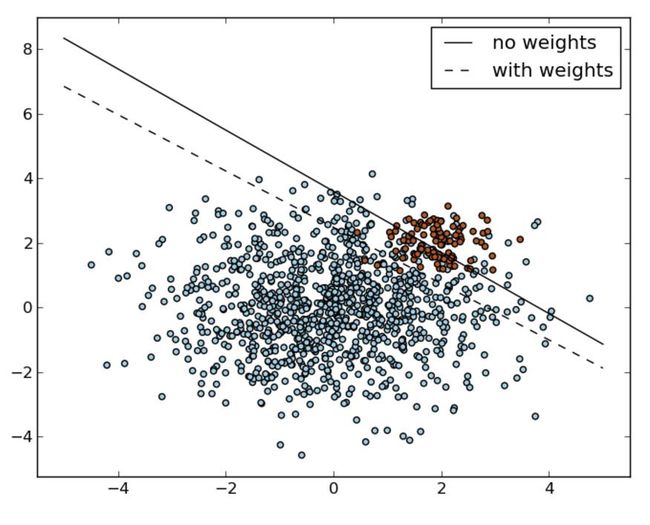
权重Weight调整
weight调整就是要保护minority的边界。
集成学习
集成学习的基本思想就是把majority进行划分,然后和minority组合成小的训练集, 然后生成学习器, 最后再集成。
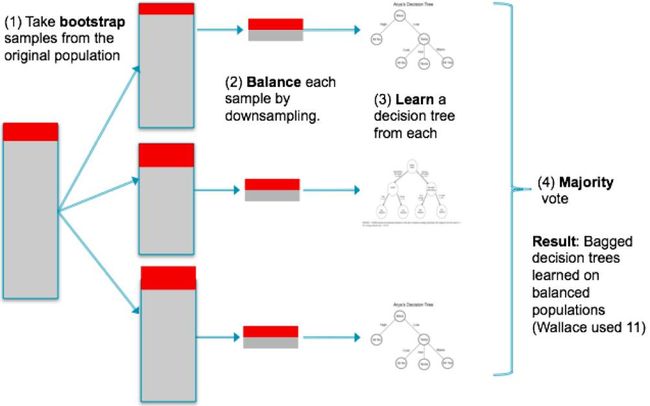
可以根据resampling with replacement做成bagging方式。 也可以根据resampling without replacement做成boosting/cascade方式。
例如:EasyEnsemble, BalanceCascade就是典型的代表。
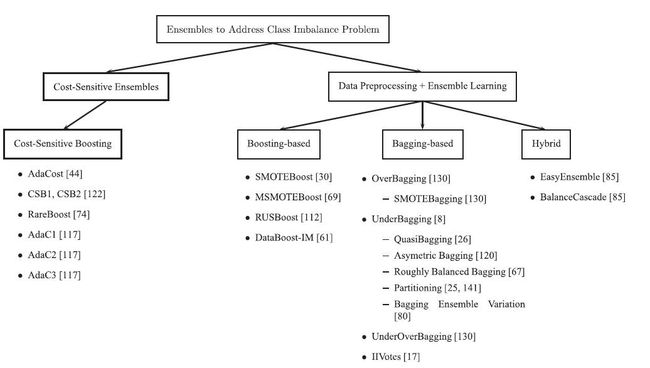
大杂交
如果再结合oversampling的技术, 就可以杂交出来各种集成学习的技术了。
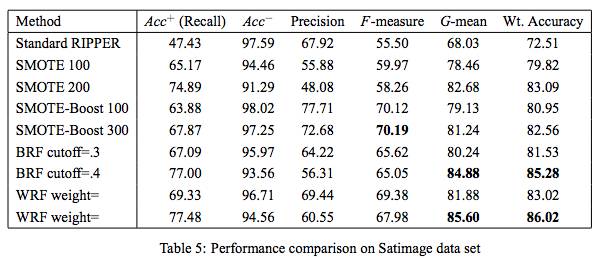
简单性能比较
这里列举了SMOTE方法,基于cost-sensitive的WeightedRandom Forest(WRF), 基于集成学习的Balace Random Forest(BRF)的性能, 可以看到其实BRF和WRF效果都比较好, 要比单纯的Oversampling的效果要好。
小结, 本文大体给出了如何学习的基本方法,最后给个整体评价。
Sampling技术:
优点:独立于学习器, 容易实现
缺点:对噪音敏感, 容易欠拟合或者过拟合。
Cost-sensitive学习器:
优点:通过cost自动调节weight来修正bias。
缺点:cost具有不确定性, 算法实现成本高
集成学习:
优点:效果比较好, 对噪音不敏感
缺点:计算量大, 容易过拟合

参考:
http://www.kdnuggets.com/2016/08/learning-from-imbalanced-classes.html/2
https://github.com/scikit-learn-contrib/imbalanced-learn/blob/master/README.rst
https://arxiv.org/pdf/1608.06048.pdf
http://101.96.10.62/statistics.berkeley.edu/sites/default/files/tech-reports/666.pdf