本文将使用PocketSphinx来实现Android平台的离线语音识别
优点: 离线,不用联网 识别较准(大家都说99% 我觉得只有80%)
缺点: 自定义语音命令麻烦 只能小范围识别
网上看了很多例子 我跟你说 那都是坑 根本就是错误的教程...
不废话 开始教程:
1.先确定要识别的词组
我的需求是实现离线识别 以下词组
中文: 向前 向后 向左 向右
英文: FORWARD BACKWARD TURNLEFT TURNRIGHT
(很多这样的教程 好像基本没教怎么识别英文来着...)
2.生成并修改lm和dic文件
先生成中文的 新建一个txt文件 命名为 text.txt
并把 向前 向后 向左 向右这四个词写上去,然后保存..
如图

注意很多文章都说这样的格式 向前
这样的格式 我只想跟你说 你被坑了... 这样做出来的语音识别demo是没有任何识别反应的 真害人..
打开这个链接 在线转换lm文件 , 点击选择文件选择刚才的text.txt文件

然后点击 COMPILE KNOWLEDGE BASE 提交
然后分别打开这两个文件 查看内容 并分别复制内容到新建的text.dic和text.lm文件里, 保存 (如果乱码 请使用谷歌浏览器 或 修改浏览器显示编码)

例如 我的 text.dic文件文本内容为:(我本来是写向前 向后 向左 向右 现在你看 顺序乱了 我不知道这样的目的 我建议保留转换后的顺序 可能与优先级有关吧)
向前
向右
向后
向左
而text.lm的内容为
Language model created by QuickLM on Tue Nov 22 03:42:55 EST 2016
Copyright (c) 1996-2010 Carnegie Mellon University and Alexander I. Rudnicky
The model is in standard ARPA format, designed by Doug Paul while he was at MITRE.
The code that was used to produce this language model is available in Open Source.
Please visit http://www.speech.cs.cmu.edu/tools/ for more information
The (fixed) discount mass is 0.5. The backoffs are computed using the ratio method.
This model based on a corpus of 4 sentences and 6 words
\data\
ngram 1=6
ngram 2=8
ngram 3=4
\1-grams:
-0.7782 -0.3010
-0.7782 -0.2218
-1.3802 向前 -0.2218
-1.3802 向右 -0.2218
-1.3802 向后 -0.2218
-1.3802 向左 -0.2218
\2-grams:
-0.9031 向前 0.0000
-0.9031 向右 0.0000
-0.9031 向后 0.0000
-0.9031 向左 0.0000
-0.3010 向前 -0.3010
-0.3010 向右 -0.3010
-0.3010 向后 -0.3010
-0.3010 向左 -0.3010
\3-grams:
-0.3010 向前
-0.3010 向右
-0.3010 向后
-0.3010 向左
\end\
还有的说有什么UTF-8编码问题 我只想说 我没遇到 我用的Sublime Text3文本编辑器 你如果有问题 你换我这个文本编辑器试试
完成上面的然后 脑残的一步来了 手动找字典(拼音)
哪里来的拼音字典? 先去这里下载一个压缩文件
https://sourceforge.net/projects/cmusphinx/files/pocketsphinx/0.7/然后找到 pocketsphinx-0.7.tar.gz 点击下载(下不动用迅雷)
下载好后解压
pocketsphinx-0.7\pocketsphinx-0.7\model\hmm\zh\tdt_sc_8k 为中文语言模型文件
pocketsphinx-0.7\model\lm\zh_CN\xxxx.dic为拼音读音字典
同理
pocketsphinx-0.7\model\hmm\en_US\hub4wsj_sc_8k 为英文语言模型文件
pocketsphinx-0.7\model\lm\en_US\xxxx.dic 为英文读音字典
你还会发现有台湾的等等
我目录的中文语言文件字典为mandarin_notone.dic 打开 你会发现里面有很多文字对应读音(拼音)

这时 我们回到刚才的text.dic和text.lm文件 打开text.dic文件
一个词一个词 在mandarin_notone.dic字典中快捷键查找 (词找不到就单个字找) 然后复制拼音到相应的词语右边 注意拼音和词语要至少留一个空格 然后拼音和拼音之间也要留一个空格
编辑text.dic文件,我的找好了 如下:
向前 x iang q ian
向右 x iang y ou
向后 x iang h ou
向左 x iang z uo
好了 保存...
英文的也一样步骤 字典的话,要从英文字典上查 英文最好都大写 并且多个单词时最好不留空格
3.没了(第一篇 ~ 就是这么草率...)
编写安卓程序?
代码太多 略.. 但我文章下面直接放demo
网上其他教程很多都是打开demo就闪退 其实原因是
你还要手动复制模型和字典文件到sd卡上
我写的这个demo也是基于它, 但我解决了这个问题 我把文件放在 assets里 并且我把模型文件和字典都整合放到一起了 ,如下
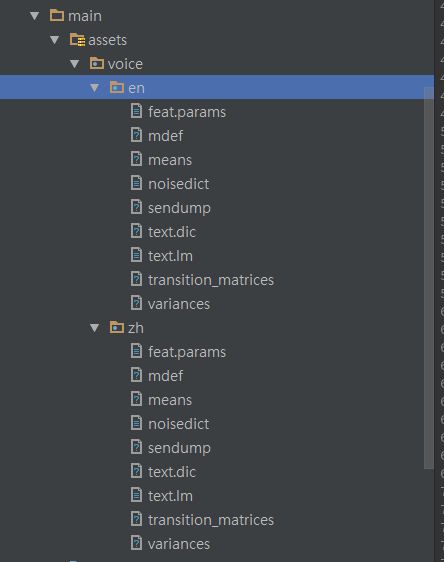
这样 就能自动复制文件到临时路径 并让你们快速实现离线语音功能 程序员不需要担心其他操作.
实际情况下那demo遗留了一个 严重的bug 就是过100s左右会c库异常闪退 这个问题我也解决了
还有个 文字不断重复 和回调一直回调同一个识别答案这个问题也解决了...
我做了判断 , 文件都放在data/data/com.packagename.xxx/file/下
并且根据手机语言切换识别中文还是英文...
publicRecognizerTask(Context context) {
String dataPath = context.getFilesDir().getAbsolutePath();
File zhPath =newFile(dataPath +"/voice/zh");
if(!zhPath.exists()) {
zhPath.mkdirs();
}
File enPath =newFile(dataPath +"/voice/en");
if(!enPath.exists()) {
enPath.mkdirs();
}
pocketsphinx
.setLogfile(dataPath +"/voice/pocketsphinx.log");
String rootPath = isZh(context) ? zhPath.getPath() : enPath.getPath();//根据环境选择中英文识别
String dicPath = rootPath +"/text.dic";
String imPath = rootPath +"/text.lm";
if(!newFile(dicPath).exists()) {
releaseAssets(context,"/", dataPath);
}
Config c =newConfig();
c.setString("-hmm", rootPath);
c.setString("-dict", dicPath);
c.setString("-lm", imPath);
c.setFloat("-samprate",8000.0);
c.setInt("-maxhmmpf",2000);
c.setInt("-maxwpf",10);
c.setInt("-pl_window",2);
c.setBoolean("-backtrace",true);
c.setBoolean("-bestpath",false);
this.ps =newDecoder(c);
this.audio =null;
this.audioq =newLinkedBlockingQueue();
this.use_partials =false;
this.mailbox = Event.NONE;
}
代码很简单的 放Demo吧
我去, 怎么没代码高亮提示 还有怎么上传资源... 知道的说下.. 我只能传CSND的了
~~~~~点我下载~~~~~