最近在打算学习用Python来分析处理数据,这里做一下记录,让以后复习方便一些。Python我安装的是Anaconda3,里边包含了很多科学计算用的包,比如numpy、matplotlib、pandas、Scipy等。IDE用的是PyCharm。
学习pandas我看了一些视频,但总是感觉还是不尽人意,然后还是选择去官网看文档,正好看到一个翻译的中文的文档,对英语不好的人来说还是挺不错,链接:https://apachecn.github.io/pandas-doc-zh/10min.html
当然,看文档是记不住那么多函数的,所以我打算找了个实战例子来巩固自己的学习成果。正好老师给我推荐了个已经过气的去年的JData大赛的题目。但是看了一下题目,额……有种无从下手的感觉,所以还是看看大佬们的代码学习学习。
这是一位好心大佬daoliker提供的入门程序:https://github.com/daoliker/JData
数据集:链接:https://pan.baidu.com/s/1i5dXf5LQk-qG8qClQ_6DeA
提取码:4t6n
里边有好几个.py文件,让我来一个个分析吧
商品数据特征统计分析
经过一番百度,得知.py文件的执行顺序为:
python create_item_table.py
python explore_data.py
python create_user_table.py
这一步的目的,是把文件中的数据按照商品和用户两个维度进行聚合
create_item_table.py
根据经验,解读程序都是先从main开始的:
if __name__ == "__main__":
item_base = get_from_jdata_product()
item_behavior = merge_action_data()
item_comment = get_from_jdata_comment()
……
1.获取商品信息
第一个函数get_from_jdata_product()
定义如下:
def get_from_jdata_product():
df_item = pd.read_csv(PRODUCT_FILE, header=0)
return df_item
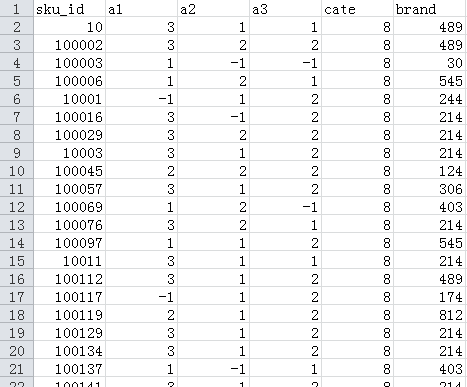
很简单的一个函数,就是读取PRODUCT_FILE文件内容,其内容格式如下(前面一部分):
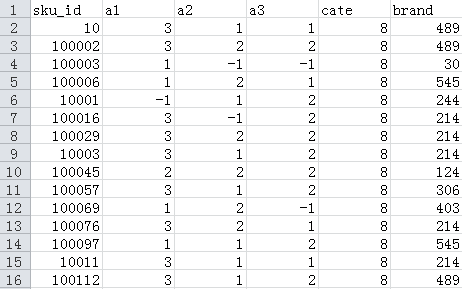
- sku_id 商品编号 脱敏
- a1 属性1 枚举,-1表示未知
- a2 属性2 枚举,-1表示未知
- a3 属性3 枚举,-1表示未知
- cate 品类ID 脱敏
- brand 品牌ID 脱敏
2.对行为信息进行一些处理
第二个函数merge_action_data():
可以看到这个函数先是获取get_from_action_data处理过的每个月用户对商品的行为数据,用来计算以下这些统计特征:
- buy_addcart_ratio(购买加购转化率),
- buy_browse_ratio(购买浏览转化率),
- buy_click_ratio(购买点击转化率),
- buy_favor_ratio(购买收藏转化率)
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_EXTRA_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).sum()
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
df_ac.ix[df_ac['buy_addcart_ratio'] > 1., 'buy_addcart_ratio'] = 1.
df_ac.ix[df_ac['buy_browse_ratio'] > 1., 'buy_browse_ratio'] = 1.
df_ac.ix[df_ac['buy_click_ratio'] > 1., 'buy_click_ratio'] = 1.
df_ac.ix[df_ac['buy_favor_ratio'] > 1., 'buy_favor_ratio'] = 1.
return df_ac
那么get_from_action_data干了啥?
get_from_action_data()函数,它是对ACTION_XXX_FILE文件进行一些统计,ACTION_XXX_FILE内容格式如下:
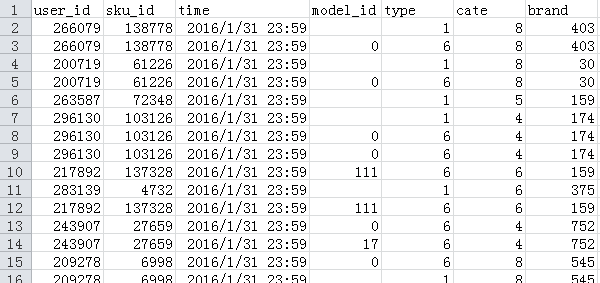
- user_id 用户编号 脱敏
- sku_id 商品编号 脱敏
- time 行为时间
- model_id 点击模块编号,如果是点击脱敏
- type 1.浏览(指浏览商品详情页); 2.加入购物车;3.购物车删除;4.下单;5.关注;6.点击
- cate 品类ID 脱敏
- brand 品牌ID 脱敏
由于.csv文件比较大(500M左右)直接操作reader对内存要求比较大,所以需要迭代来操作:
def get_from_action_data(fname, chunk_size=100000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop: #对reader进行迭代操作
try:
chunk = reader.get_chunk(chunk_size)[["sku_id", "type"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).apply(add_type_count)
df_ac = df_ac.drop_duplicates('sku_id') # 去掉重复项
return df_ac
可以看到这里只读取["sku_id", "type"]这两列,原因是只这两列就可以计算出这么一些信息:
browse_num(浏览数),
addcart_num(加购数),
delcart_num(删购数),
buy_num(购买数),
favor_num(收藏数),
click_num(点击数)
其计算过程在add_type_count(group)函数里边:
def add_type_count(group):
behavior_type = group['type'].astype(int)
#print(behavior_type.head(10))
type_cnt = Counter(behavior_type) #对各个type进行统计返回一个dict
#print(type_cnt)
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['sku_id', 'browse_num', 'addcart_num',
'delcart_num', 'buy_num', 'favor_num',
'click_num']]
如果想知道每一步计算的结果是什么,可以在那一步之后加个print
而最后merge_action_data()返回的就是这么样的一个DataFrame
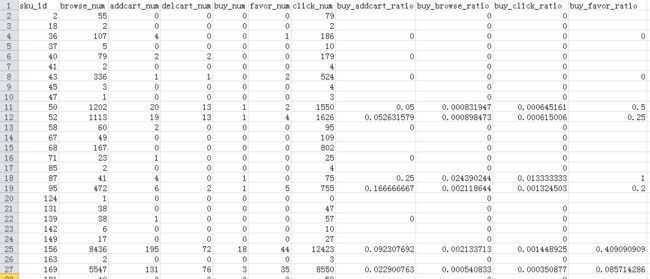
3.处理评论数据
第三个函数get_from_jdata_comment也是非常简单的,它处理的文件是COMMENT_FILE,其内容如下:
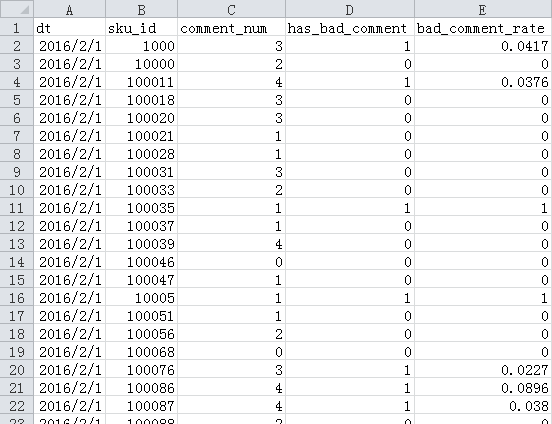
- dt 截止到时间 粒度到天
- sku_id 商品编号 脱敏
- comment_num 累计评论数分段0表示无评论,1表示有1条评论,
2表示有2-10条评论,
3表示有11-50条评论,
4表示大于50条评论 - has_bad_comment 是否有差评0表示无,1表示有
- bad_comment_rate 差评率差评数占总评论数的比重
函数定义:
def get_from_jdata_comment():
df_cmt = pd.read_csv(COMMENT_FILE, header=0)
df_cmt['dt'] = pd.to_datetime(df_cmt['dt'])
# 查找最新评论索引
idx = df_cmt.groupby(['sku_id'])['dt'].transform(max) == df_cmt['dt']
df_cmt = df_cmt[idx]
return df_cmt[['sku_id', 'comment_num',
'has_bad_comment', 'bad_comment_rate']]
可以看到这个函数做的事情就这么几个:读取文件数据、转换时间格式、返回最新的评论数据
csv文件里的时间一般都是是str的,为了便于处理所以需要把它转换成datetime类。
从表中可以看到一个商品的评论信息可能会有对应好几个时间的,我们只需要得到最新的评论信息就行了。而且返回值也不需要'dt'这一列了。
4.类SQL操作
经过这三个函数我们得到3个新的表 item_base、item_behavior、item_comment。
item_base = get_from_jdata_product()
item_behavior = merge_action_data()
item_comment = get_from_jdata_comment()
item_base:
item_behavior :
item_comment:
接下来要做的就是把这些表给融合起来:
由于本程序的目的是生成商品数据特征表,所以必须保证商品数据的完整。
so
以下连接操作都是以item_base为基准主键'sku_id'为的左连接操作:
# SQL: left join
item_behavior = pd.merge(
item_base, item_behavior, on=['sku_id'], how='left')
item_behavior = pd.merge(
item_behavior, item_comment, on=['sku_id'], how='left')
item_behavior.to_csv(ITEM_TABLE_FILE, index=False)
最后得到的表的内容如下:
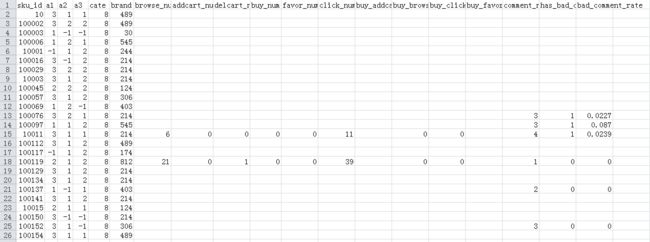
以上都是本萌新的个人理解,如有错误欢迎指出
create_item_table.py全部代码:
#-*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from collections import Counter
ACTION_201602_FILE = "data/JData_Action_201602.csv"
ACTION_201603_FILE = "data/JData_Action_201603.csv"
ACTION_201603_EXTRA_FILE = "data/JData_Action_201603_extra.csv"
ACTION_201604_FILE = "data/JData_Action_201604.csv"
COMMENT_FILE = "data/JData_Comment.csv"
PRODUCT_FILE = "data/JData_Product.csv"
USER_FILE = "data/JData_User.csv"
NEW_USER_FILE = "data/JData_User_New.csv"
ITEM_TABLE_FILE = "data/item_table.csv"
def get_from_jdata_product():
df_item = pd.read_csv(PRODUCT_FILE, header=0)
return df_item
# apply type count
def add_type_count(group):
behavior_type = group['type'].astype(int)
type_cnt = Counter(behavior_type)
group['browse_num'] = type_cnt[1]
group['addcart_num'] = type_cnt[2]
group['delcart_num'] = type_cnt[3]
group['buy_num'] = type_cnt[4]
group['favor_num'] = type_cnt[5]
group['click_num'] = type_cnt[6]
return group[['sku_id', 'browse_num', 'addcart_num',
'delcart_num', 'buy_num', 'favor_num',
'click_num']]
def get_from_action_data(fname, chunk_size=100000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[["sku_id", "type"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).apply(add_type_count)
df_ac = df_ac.drop_duplicates('sku_id') # 去掉重复项
return df_ac
def get_from_jdata_comment():
df_cmt = pd.read_csv(COMMENT_FILE, header=0)
df_cmt['dt'] = pd.to_datetime(df_cmt['dt'])
# find latest comment index
idx = df_cmt.groupby(['sku_id'])['dt'].transform(max) == df_cmt['dt']
df_cmt = df_cmt[idx]
return df_cmt[['sku_id', 'comment_num',
'has_bad_comment', 'bad_comment_rate']]
def merge_action_data():
df_ac = []
df_ac.append(get_from_action_data(fname=ACTION_201602_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201603_EXTRA_FILE))
df_ac.append(get_from_action_data(fname=ACTION_201604_FILE))
df_ac = pd.concat(df_ac, ignore_index=True)
df_ac = df_ac.groupby(['sku_id'], as_index=False).sum()
df_ac['buy_addcart_ratio'] = df_ac['buy_num'] / df_ac['addcart_num']
df_ac['buy_browse_ratio'] = df_ac['buy_num'] / df_ac['browse_num']
df_ac['buy_click_ratio'] = df_ac['buy_num'] / df_ac['click_num']
df_ac['buy_favor_ratio'] = df_ac['buy_num'] / df_ac['favor_num']
df_ac.ix[df_ac['buy_addcart_ratio'] > 1., 'buy_addcart_ratio'] = 1.
df_ac.ix[df_ac['buy_browse_ratio'] > 1., 'buy_browse_ratio'] = 1.
df_ac.ix[df_ac['buy_click_ratio'] > 1., 'buy_click_ratio'] = 1.
df_ac.ix[df_ac['buy_favor_ratio'] > 1., 'buy_favor_ratio'] = 1.
return df_ac
if __name__ == "__main__":
item_base = get_from_jdata_product()
item_behavior = merge_action_data()
item_comment = get_from_jdata_comment()
# SQL: left join
item_behavior = pd.merge(
item_base, item_behavior, on=['sku_id'], how='left')
item_behavior = pd.merge(
item_behavior, item_comment, on=['sku_id'], how='left')
item_behavior.to_csv(ITEM_TABLE_FILE, index=False)
参考:
https://blog.csdn.net/liuhuoxingkong/article/details/70049019
https://github.com/daoliker/JData
https://apachecn.github.io/pandas-doc-zh/10min.html