最近发现一直用,但也不懂本质上是啥。。。学习了一波。
看了好多大佬的博客,多谢啦。附上地址:
1.https://blog.csdn.net/aitangyong/article/details/38822505
2.https://www.cnblogs.com/dolphin0520/p/3932921.html
3.https://blog.csdn.net/linghu_java/article/details/17123057
4.https://machenxing.github.io/2018/06/05/%E7%BA%BF%E7%A8%8B%E6%B1%A0%EF%BC%9A%E4%BD%BF%E7%94%A8Executors%E5%92%8CThreadPoolExecutor/
5.https://blog.csdn.net/tuke_tuke/article/details/51353925
6.https://blog.csdn.net/fwt336/article/details/81530581
7.https://www.cnblogs.com/zhaoyan001/p/7049627.html
8.https://www.jianshu.com/p/87bff5cc8d8c
一、大致结构
一般写的时候经常是:
ExecutorService executorService = new ThreadPoolExecutor(...);
或者
ExecutorService executorService = Executors.newFixedThreadPool(..);
这里边涉及到几个Java的类,从网上盗了一张别人的图,挺清晰的。

1.Executor接口
它是"执行者"接口,它是来执行任务的。准确的说,Executor提供了execute()接口来执行已提交的 Runnable 任务的对象。Executor存在的目的是提供一种将"任务提交"与"任务如何运行"分离开来的机制。
这个接口只有一个方法:
void execute(Runnable command);
2.Executors
Executors是个静态工厂类。它通过静态工厂方法返回ExecutorService、ScheduledExecutorService、ThreadFactory 和 Callable 等类的对象。说白了就是拿它获取线程池。
3.ExecutorService接口
这是个接口类,里边有一堆关于线程的方法,比方说shutdown,submit等。
4.ThreadPoolExecutor
就是ExecutorService的实现类啦,也是最经常用的部分。它继承自AbstractExecutorService,这个类实现了ExecutorService绝大数的方法。
别人的总结哈:
1、Executor是一个顶层接口,在它里面只声明了一个方法execute(Runnable),返回值为void,参数为Runnable类型,从字面意思可以理解,就是用来执行传进去的任务的;
2、然后ExecutorService接口继承了Executor接口,并声明了一些方法:submit、invokeAll、invokeAny以及shutDown等;
3、抽象类AbstractExecutorService实现了ExecutorService接口,基本实现了ExecutorService中声明的所有方法;
4、最后ThreadPoolExecutor继承了类AbstractExecutorService。
二、创建线程
最经常用的就是ThreadPoolExecutor啦,先看下它提供了四个构造方法,总的来说就是7个参数变量
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
(1)corePoolSize:核心线程数。也就是该线程池的基本大小。
比方说在一个线程池里核心线程数为5,那么这5个线程被创建出来之后是不会被释放的。如果某时刻还没有达到最大核心线程数,就会接着创建新的核心线程,直到最大值。所以这个值
不过刚创建或者没有任务提交的时候,线程不会启动的,这样线程池的大小可能就不是corePoolSize
(2)maximumPoolSize:线程池中允许的最大线程数。
这个可能要大于等于corePoolSize,如果当前所有corePoolSize的线程已满,但还没有达到maximumPoolSize,就会开始创建非核心线程。但和核心线程的区别是,等到这些线程空闲下来会被回收释放掉。也就是该线程池可以达到的最大线程数。
这个值可以通过setMaximumPoolSize()这个方法改掉。
另外ThreadPoolExecutor有一个属性largestPoolSize,是用来记录此线程池曾经达到的最大线程数,而不是当前的最大线程。
(3)keepAliveTime:空闲线程允许存活的最长时间
一般情况下,这个时间限制是针对于非核心线程的,超过这个时间,线程将被释放销毁。如果想要对核心线程也生效的话,取决于另一个属性allowCoreThreadTimeOut的值。
(4)unit : 时间单位
这个就没什么说的啦,时间单位。
(5)workQueue : 任务队列。存储暂时无法执行的任务,等待空闲线程来执行任务。
1、ArrayBlockingQueue:数组结构的有界阻塞队列,先进先出FIFO。
2、LinkedBlockingQueue:链表结构的无界阻塞队列。先进先出FIFO排序元素。
3、SynchronousQueue:不存储元素的阻塞队列,就是每次插入操作必须等到另一个线程调用移除操作。
(6)threadFactory : 线程工程,用于创建线程。
一个简单的实现类是DefaultThreadFactory,也可以定制自己的。
(7)handler:表示当拒绝处理任务时的策略。
一般来说,如果当前线程池线程数已经达到最大值了,而且没有空闲线程,这样再来任务的时候,就会采用一定的拒绝策略。
1、ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
2、ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
3、ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
4、ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
使用Executors创建线程
上边提到啦,Executors是个静态工厂,用它可以创建一些类型的线程池。除了ThreadPoolExecutor外,还有基于ScheduledThreadPoolExecutor、ForkJoinPool之类的其他类型的线程池(这个就不记录啦,因为还没学会/(ㄒoㄒ)/~~)有兴趣ForkJoinPool可以看http://blog.dyngr.com/blog/2016/09/15/java-forkjoinpool-internals/
只看ThreadPoolExecutor的话,其实具体还是上述七个参数不同组合导致的不同分类:
(1) newFixedThreadPool()
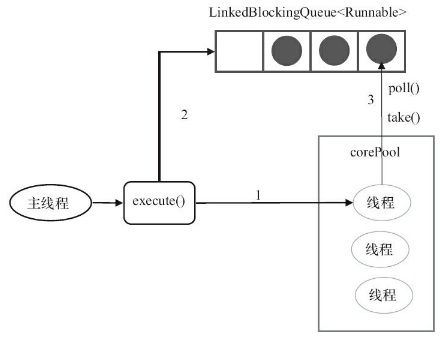
根据参数就可以发现,这是个固定大小的线程池,核心线程数和最大线程数都是nThreads,当corePoolSize满了之后就加入到LinkedBlockingQueue无界队列中等待。
另外,加入线程池的线程属于托管状态,线程的运行不受加入顺序的影响。
还有一个重载的方法,可以设置threadFactory。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
}
(2)newSingleThreadExecutor()

这个和newFixedThreadPool差不多,就是线程数的差异,这个就一个。满了就放入队列中,执行完了就从队列取一个。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
}
(3)newCachedThreadPool()
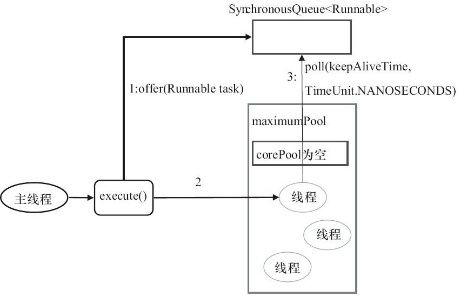
这个从参数看的话,核心线程数是0,但是线程池大小可以认为是无限大,有60s的存活时间。而且用的SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。
我觉得这个主要缓存是缓存的是线程池,比方说某时间点来了10个任务,开了10个线程去跑,但跑完他不会被回收,再来5个的话就会用这10个中的5个run。这样可以减少不必要的线程创建和销毁上的消耗。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
}
em.. 但是看资料的时候发现:
在阿里巴巴java开发手册中明确指出,不允许使用Executors创建线程池。

线程状态
创建完线程之后,这些线程就会有一些状态,它反映在一些属性上:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
其中AtomicInteger:利用低29位表示线程池中线程数,通过高3位表示线程池的运行状态:
1、RUNNING:-1 << COUNT_BITS,即高3位为111,该状态的线程池会接收新任务,并处理阻塞队列中的任务;
2、SHUTDOWN: 0 << COUNT_BITS,即高3位为000,该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
3、STOP : 1 << COUNT_BITS,即高3位为001,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
4、TIDYING : 2 << COUNT_BITS,即高3位为010;
5、TERMINATED: 3 << COUNT_BITS,即高3位为011