使用Python+OpenCV实现在视频中某对象后添加图像
概述
在运动物体后面添加图像是一个典型的计算机视觉项目
了解如何使用传统的计算机视觉技术在视频中添加logo
介绍
我的一位同事向我提出了一个挑战——建立一个计算机视觉模型,可以在视频中插入任何图像,而不会扭曲移动的物体。
如你所想,这是一个非常有趣的项目。
众所周知,处理视频是很困难的,因为它们与图像不同,是动态的,我们没有可以轻易识别和跟踪的静态对象,复杂性水平上升了好几个层次——这就需要我们对图像处理技术和计算机视觉技术的把握。

我决定在背景上加个logo。我稍后将详细说明的挑战是在任何给定视频中插入一个不会妨碍对象动态特性的logo。
我使用Python和OpenCV构建了这个计算机视觉系统,并在本文中分享了我的方法。
目录
陈述问题
获取此项目的数据
为我们的计算机视觉项目制定实现计划
在Python中实现这项技术——让我们添加logo!
理解问题陈述
这是一个非常罕见的计算机视觉使用案例,我们将在视频中嵌入一个logo。现在你一定在想-那有什么大不了的?我们可以简单地把标志贴在视频上,对吧?
但是,这个标志可能会隐藏视频中一些有趣的动作。如果标志妨碍了前面的移动物体怎么办?这会看起来很low。
因此,我们必须弄清楚如何在背景中的某个地方添加logo,这样就不会阻止视频中正在进行的主要操作。
下面的视频-左半部分是原始视频,右半部分的logo出现在舞者身后的墙上:
视频:https://youtu.be/L9KsuvO0VMs
这是我们将在本文中实现的想法。
获取此项目的数据
我从pexels.com网站(一个免费的股票视频网站)上获取数据。如前所述,我们的目标是在视频中放置一个标志,使其出现在某个移动对象的后面。
在本项目我使用了OpenCV本身的标志。你也可以使用任何你想要的标志(也许是你最喜欢的运动队伍标识?)。

你可以从这里下载视频和logo。
https://drive.google.com/file/d/1mXJtJOMTZYm-W6rQavdclbBUEuj3JL4v/view?usp=sharing
为我们的计算机视觉项目制定实现计划
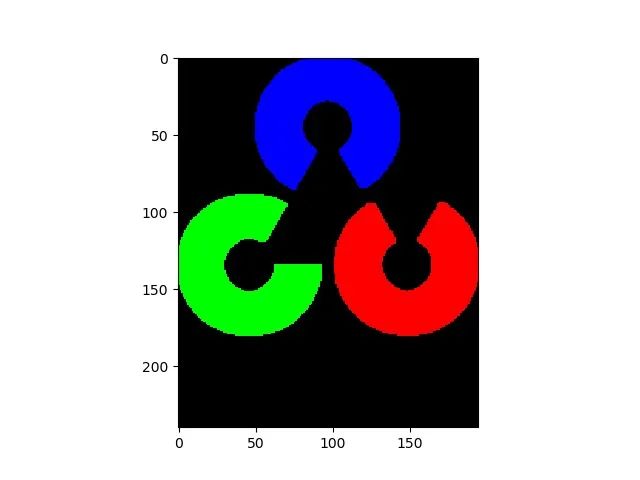
在实施这个项目之前,我们先了解一下一个计算机视觉技术:图像掩码。让我给你看一些插图来了解这项技术。
假设我们要在图像(图2)中放置一个矩形(图1),使第二个图像中的圆出现在矩形的顶部:

所以,期望的结果应该是这样的:

然而,这并不是那么简单的。当我们从图1中选取矩形并将其插入图2中时,它将出现在粉色圆圈的顶部:

这不是我们想要的,圆圈应该在矩形的前面。所以让我们了解如何解决这个问题。
这些图像本质上是数组,这些数组的值是像素值,每种颜色都有自己的像素值。
因此,我们可以将矩形的像素值设置为1,在这里它应该与圆重叠(在图5中),同时保持矩形的其余像素值不变。
在图6中,蓝色虚线包围的区域是我们放置矩形的区域,让我们用R来表示这个区域。我们也将R的所有像素值设置为1,但是我们将保持整个粉色圆圈的像素值不变:

我们的下一步是将矩形的像素值与R的像素值相乘,因为任何数字乘以1都会得到该数字本身,所以所有R的像素值都将被矩形的像素替换。
类似地,矩形的像素值1将被图6的像素替换,最终的结果是这样的:

这是我们将要使用的技术,将OpenCV标志嵌入到视频中的背后原理。
在Python中实现这项技术
你可以使用Jupyter笔记本或任何你选择的IDE,然后我们首先导入必要的库。
导入库
import cv2import reimport osimport randomimport numpy as npimport matplotlib.pyplot as pltfrom os.path import isfile, join
注意:本教程使用的OpenCV库版本是4.0.0。
加载图像
接下来,我们将指定保存logo和视频的工作目录路径。请注意,你应该在下面的代码片段中指定“path”:
# 指定工作目录的路径path = ".../"
# 读取logo图像logo = cv2.imread(path+"opencv_logo.png")
# 读取视频的第一帧cap = cv2.VideoCapture(path+"Pexels Videos 2675513.mp4")ret, frame = cap.read()
至此我们已经加载了logo图像和视频的第一帧。现在让我们看看这些图像或数组的形状:
logo.shape, frame.shape
输出:((240, 195, 3), (1080, 1920, 3))
两个输出都是三维的。第一个维度是图像的高度,第二个维度是图像的宽度,第三个维度是图像中的通道数,即蓝色、绿色和红色。
现在,让我们绘制并查看logo和视频的第一帧:
plt.imshow(logo)plt.show()
plt.imshow(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))plt.show()

图像掩码技术
框架尺寸比logo大得多,因此我们可以把logo放在许多地方。
然而,把logo放在画面的中心对我来说似乎是最合适的,因为大部分的动作都会发生在视频中的那个区域,因此我们将把logo放入框架中,如下所示:
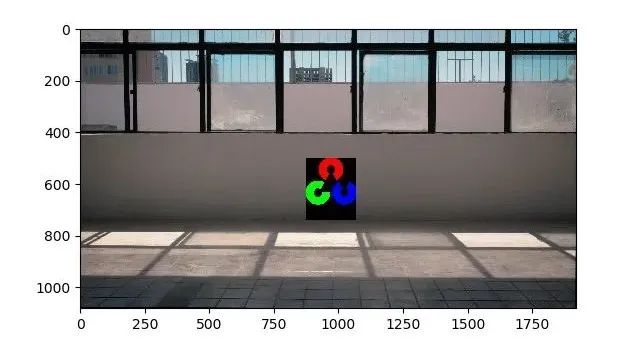
不用担心标志中的黑色背景,我们将在稍后的代码中将黑色区域中的像素值设置为1。现在我们要解决的问题是处理移动物体出现在我们放置标志的同一区域中。
如前所述,我们需要使logo允许自己被移动对象遮挡。
现在,我们将使其中放置logo的区域具有广泛的像素值。理想情况下,此区域中的所有像素值都应相同,那我们怎么做呢?

我们必须使绿色虚线框包围的墙像素具有相同的值。我们可以借助HSV(色调、饱和度、值)颜色空间来完成此操作:
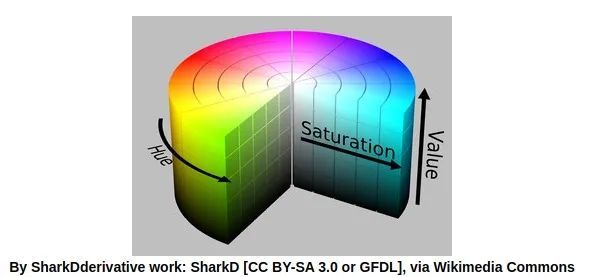
我们的图像是在RGB色彩空间中的,我们将把它转换成HSV图像。下图是HSV版本:
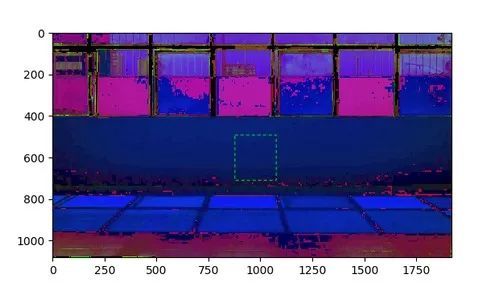
下一步是查找绿色虚线框内零件的HSV值范围,结果显示框中的大多数像素的范围从[6,10,68]到[30,36,122],它们分别是HSV的上下范围。
现在使用这个HSV值范围,我们可以创建一个二进制掩码,此掩码只是像素值为0或255的图像,因此在HSV值的上下范围内的像素将等于255,其余像素将为0。
下面是根据HSV图像准备的掩码,黄色区域中的所有像素的像素值为255,其余像素值为0:

现在,我们可以根据需要轻松地将绿色虚线框内的像素值设置为1,让我们回到代码中:
# HSV的范围lower = np.array([6,10,68])upper = np.array([30,36,122])
# 为图像创建核kernel = np.ones((3,3),np.uint8)
# 每次运行以下while循环时,执行下面的两行cap = cv2.VideoCapture(path+"Pexels Videos 2675513.mp4")cnt = 0
# 循环加载、预处理和显示帧while(True): ret, f = cap.read()
# 提取我们将放置logo的区域 # 此区域的尺寸应与logo的尺寸相匹配 mini_frame = f[500:740,875:1070,:]
# 创建 HSV 图像 hsv = cv2.cvtColor(f, cv2.COLOR_BGR2HSV)
# 创建掩码 mask = cv2.inRange(hsv, lower, upper)
dil = cv2.dilate(mask,kernel,iterations = 5)
# 创建3个通道 mini_dil = np.zeros_like(mini_frame) mini_dil[:,:,0] = dil[500:740,875:1070] mini_dil[:,:,1] = dil[500:740,875:1070] mini_dil[:,:,2] = dil[500:740,875:1070]
# 复制logo图像 logo_copy = logo.copy()
# 当掩码的像素值为0时,将像素值设置为1 logo_copy[mini_dil == 0] = 1
# 将标识的像素值设置为1,其中标识的像素值为0 logo_copy[logo == 0] = 1
# 当logo的像素值不为1时,将像素值设置为1 mini_frame[logo_copy != 1] = 1
# 合并图像(数组乘法) mini_frame = mini_frame*logo_copy
# 在框架中插入logo f[500:740,875:1070,:] = mini_frame
# 调整框架的大小(可选) f = cv2.resize(f, (480, 270), interpolation = cv2.INTER_AREA)
# 显示帧 cv2.imshow('frame', f)
# 保存帧 # cv2.imwrite(path+'frames/'+str(cnt)+'.png',f) cnt+= 1
if cv2.waitKey(20) & 0xFF == ord('q'): cv2.destroyAllWindows() break
上面的代码片段将从视频中加载帧,对其进行预处理,并创建HSV图像和掩码,最后将logo插入到视频中。你完成了!
结尾
在本文中,我们介绍了一个非常有趣的计算机视觉用例,并从零开始实现它。在此过程中,我们还学习了如何使用图像数组以及如何从这些数组中创建掩码。
当你处理其他的计算机视觉任务时,这会对你有所帮助。
原文链接:https://www.analyticsvidhya.com/blog/2020/06/deep-learning-project-image-object-opencv/
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文(无广告)。
↓扫描二维码添加小编↓
