spark运行架构:
1、Driver : spark应用的任务控制节点
2、Executor : spark应用的任务的执行进程
3、Cluster Manager : spark任务的资源管理器
如图:
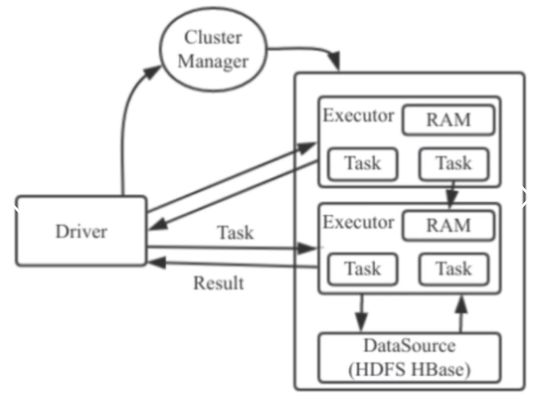
spark运行架构包括Cluster Manager、Driver和Executor;
Executor内有线程池,通过多线程执行相关任务;
Task的中间结果直接写入到内存,有效减少IO开销。
名词解释:
1、Application:应用,即我们提交到Spark的执行程序
2、Job:Spark中对RDD进行Action操作所产生的RDD处理流程
3、Stage:阶段,一个Job会切分成多过Stage,各个Stage之间按照顺序执行
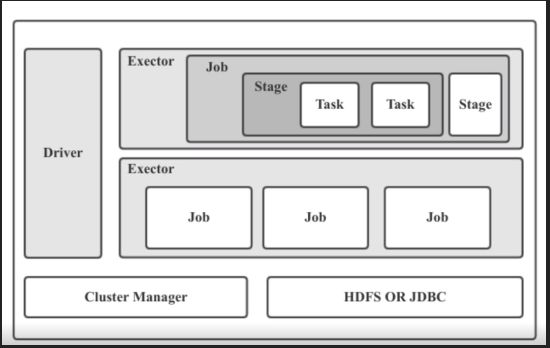
一个Spark Application包含一个Driver和多个job
一个job包含多个Stage,一个Stage又包含多个Task
4、SparkContext:整个应用的上下文,控制应用的生命周期
5、RDD:弹性分布式数据集(Resilient Distributed Dataset)
6、DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系
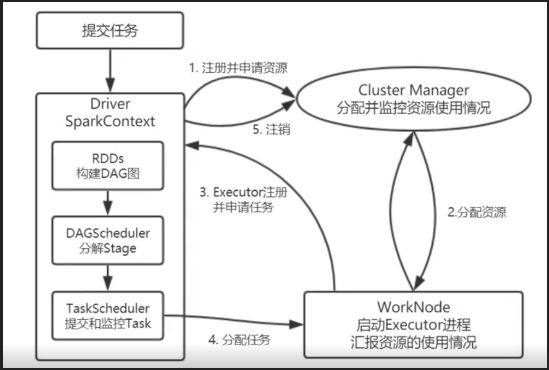
1、提交应用后,Driver会创建SparkContext实例,申请资源
2、ClusterManager分配资源,启动Executor进程,Executor向Dirver注册并申请任务
3、SparkContext生成DAG图通过DAGScheduler解析,生产多个Stage并通过TaskScheduler分配到各个分配给Executor执行
过程:
当一个spark任务被提交的时候,首先要为这个应用构建基本的运行环境,即有任务的控制节点Driver去创建一个应用的上下文sparkCentext, 并且由sparkCentext负责与Cluster Manager 进行注册申请资源。这里呢也就是我们的第一个步,资源管理器为Executor分配资源,并启动Executor进程。Executor与资源管理器保持心跳链接,同时向Dirver申请任务,sparkCentext根据RDD的依赖关系构建出DAG图,将DAG图交给DAG的调度器进行解析,最终将DAG分解成多个Stage,Stage就是一个任务集,最终将一个一个的任务集交个底层的任务调度器进行处理, 任务调度器将任务分发给Executor运行,任务在Executor上运行将结果反馈给Driver,运行完毕之后把数据进行写入,并且释放掉所有占用的资源。
执行特点:
1、Job的执行过程与资源管理器无关,资源管理器只分配资源
2、Executor含有线程池,以多线程的方式提高任务的执行效率
3、每个Task产生的结果会放入内存,避免了大量的IO开销
1.Application:基于spark的用户程序,包含了一个driver program 和集群中多个 executor
2.Driver Program:运行application的main()函数并自动创建SparkContext。通常
SparkContext 代表driver program
3.Executor:为某个Application运行在worker node 上的一个进程。该进程负责运行task并负责将数据存储在内存或者硬盘上,每个application 都有自己独立的 executors
4.Cluster Mannager:在集群上获得资源的外部服务(spark standalon,mesos,yarm)
5.Worker Node:集群中任何可运行application 代码的节点
6.RDD:spark 的基本运算单元,通过scala集合转化,读取数据集生成或者由其他RDD进过算子操作得到
7.Job:可以被拆分成task并行计算的单元,一般为spark action 触发的一次执行作业
8.Stage:每个job会被拆分成很多组task,每组任务被称为stage,也可称TaskSet,该属于经常在日志中看到
9.task:被送到executor上执行的工作单元