基于HiSpark Wi-Fi IoT套件_5-OLED中文显示
上一篇报告已经过去一个月了,主要是公司项目太急,耽搁太长时间。上一次的报告主要主要介绍了HI3861的IIC操作,控制OLED显示英文“hello world”,当时调试的时候其实是想显示中文的,但是因为原先IAR开发环境下的中文显示程序移植到鸿蒙里面后居然一堆错误,编译器差异文中对应细节会详述,所以只显示了英文。
那之后总归觉得OLED怎么也得能显示中文吧,所以本篇主要介绍怎么在OLED上显示中文,当然是基于上次报告的代码,最终代码会在文末附件里。主要内容有如下几点:
1、 汉字取模
2、 代码编写修改
3、 烧录测试
01
汉字取模
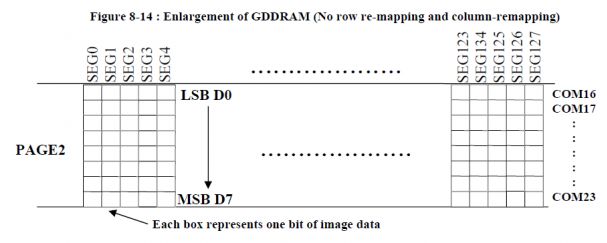
上次报告已经介绍过,套件使用的OLED显示cache如下图所示,显示点阵对应cache每个字节的顺序是从左到右从上到下,而显示的每个字节的bit是高位在下。
通过显存与点阵对应关系,那汉字取模要遵循字节从左到右从上到下,字节内为纵向8点(一个字节位数)下高位取模方式,使用的取模软件是“LcmZimoLCD字模提取工具软件”,报告后边会在附件中体现。因此,最终软件设置界面设置内容如下图所示:

设置完成后点击“参数确认“并在下方文字框中输入”你好“并点击输入字串进入下一界面,下一界面如下图所示:

// --------- 汉字字模的数据结构定义 ----------- //
typedef struct typFNT_GB1 // 汉字字模数据结构
{
signed char Index[2]; // 汉字内码索引
char Msk[32]; // 点阵码数据
};
///
// 汉字字模表 //
// 汉字库: 宋体16.dot 纵向取模下高位,数据排列:从左到右从上到下//
///
struct typFNT_GB16 code GB_16[] = // 数据表
{
"你",0x40,0x20,0xF8,0x07,0x40,0x20,0x18,0x0F,
0x08,0xC8,0x08,0x08,0x28,0x18,0x00,0x00,
0x00,0x00,0xFF,0x00,0x00,0x08,0x04,0x43,
0x80,0x7F,0x00,0x01,0x06,0x0C,0x00,0x00,
"好",0x10,0x10,0xF0,0x1F,0x10,0xF0,0x80,0x82,
0x82,0x82,0xE2,0x92,0x8A,0xC6,0x80,0x00,
0x40,0x22,0x15,0x08,0x14,0x63,0x00,0x00,
0x40,0x80,0x7F,0x00,0x00,0x00,0x00,0x00
};
// 汉字表:
// 你好
此处生成的代码需要做进一步修改方可使用鸿蒙系统使用的GCc编译器,具体修改内容会在代码修改中做详述。
02
代码编写与修改
代码修改主要有如下几点。
1、 单个汉字字符机构体修改:
修改汉字取模软件生成的代码,能够通过鸿蒙交叉编译器,其中结构体 struct typFNT_GB16 内的signed char Index[2]; 索引值由2更改为3,因为单个汉字在双引号内时还需要一个字节存储字符串结束字符“\0”。最终更改后的结构体如下:
struct typFNT_GB16 // 汉字字模数据结构
{
unsigned charindex[3]; // 汉字内码索引
charmask[32]; // 点阵码数据
};
2、 汉字码表:
查看上文中生成的汉字码表struct typFNT_GB16 code GB_16[],可以看出字模软件将所有数据都以字节数组的方式存放的,这种存放方式在IAR中可以直接编译通过,也就是IAR会将字符数组映射到struct typFNT_GB16内容中,而鸿蒙使用的GCC编译器不支持此类操作,所以上次报告未能实现中文显示。根据编译器报错提示,需要将生成的汉字码表更改为如下:
const structtypFNT_GB16 ST_GB_16[] =
{
{
{"你",},
{
0x40,0x20,0xF8,0x07,0x40,0x20,0x18,0x0F,
0x08,0xC8,0x08,0x08,0x28,0x18,0x00,0x00,
0x00,0x00,0xFF,0x00,0x00,0x08,0x04,0x43,
0x80,0x7F,0x00,0x01,0x06,0x0C,0x00,0x00,
}
},
{
{"好",},
{
0x10,0x10,0xF0,0x1F,0x10,0xF0,0x80,0x82,
0x82,0x82,0xE2,0x92,0x8A,0xC6,0x80,0x00,
0x40,0x22,0x15,0x08,0x14,0x63,0x00,0x00,
0x40,0x80,0x7F,0x00,0x00,0x00,0x00,0x00,
}
},
};
3、 显示函数添加中文显示代码:
需要在OLED驱动中添加汉字处理部分,本报告依据上一个报告主要是修改OLED_DrawString16函数。其中有几个需要特别注意的在代码中有注释。修改后代码如下:
ntOLED_DrawString16(int x , int y ,const char* p_str , int color)
{
int i , j , m ;
const unsigned char *p_asc = 0;
const char* p_cn = 0;
const struct typFNT_GB16* p_cn_lib ;
if((x >= 120) || (y >= 7))
return -1;
while(*p_str != '\0')
{
// 判断当前字节是不是汉字字符,
// 汉字编码用两个字节表示一个汉字,并且起始自己大于0x7f
// 本来使用(*p_str)<0X80,但是编译器编译有Warning提示
// 提示为此条指令永远为true,编译中不允许有告警故更改为
// (*p_str)&0X80)==0
if(((*p_str)&0X80)==0)
{
p_asc = nAsciiDot16X8 + ((*p_str -32)<< 4) ;
for(j = 0 ; j < 2 ; j++)
{
for(i = 0 ; i < 8 ; i++)
{
if(color)
{
OLEDBuffer[(y + j)][x +i]= * p_asc ++ ;
}
else
{
OLEDBuffer[(y + j)][x +i] = ~(* p_asc ++) ;
}
}
}
x += 8 ;
p_str ++ ;
}
Else
{
printf("[xxxxx]hanzi.\r\n");
p_cn = (char*)-1 ;
p_cn_lib = ST_GB_16 ;
m = GetSTLiberayNum();
for(i = 0 ; i < m ; i++)
{
printf("[xxxxx] *p_str =%x.\r\n",*p_str);
// 此处多一个char型指针取值与0xff解释在代码末尾
if(((*p_str)&0xff) ==p_cn_lib->index[0])
{
printf("[xxxxx]bingo1.\r\n");
if(((*(p_str+1))&0xff)== p_cn_lib->index[1])
{
p_cn = p_cn_lib->mask ;
printf("[xxxxx]bingo2.\r\n");
break ;
}
}
p_cn_lib++;
}
if(p_cn != (char*)-1)
{
for(j = 0 ; j < 2 ; j++)
{
for(i = 0 ; i < 16 ;i++)
{
if(color)
{
OLEDBuffer[(y +j)][x + i]= * p_cn ++ ;
}
else
{
OLEDBuffer[(y +j)][x + i] = ~(* p_cn ++) ;
}
}
}
}
x += 16 ;
p_str += 2;
}
}
return x;
}
以上代码修改过程中从注释可以看出有两个地方编译器有特别之处,第一个在代码注释中已经解释,而第二个贴别解释一下,因为本人也很困惑。
其中((*p_str)&0xff) == p_cn_lib->index[0]这一条,p_str按照定义类型是“const char*”,对其取值应该是char类型,而实际取值后是一个4字节数值。可能所使用的gcc中char为4字节的类型,使用printf("[xxxxx] *p_str =%x.\r\n",*p_str);语句串口打印居然在字符值前面添加了0xffffff--。所以才有了((*p_str)&0xff)的处理。此处问题折腾了半个下午才找到原因,一方面对gcc使用不多,不是很熟悉,另一方面可能是自己编程方式有问题。
4、 显示代码添加:
在OLED显示驱动中添加OLED_DrawString16(8,4,"你好",1);语句,并修改BUILD.gn文件添加字库代码文件,编译生成bin文件。
04
编译测试
编译测试不多说了,下载后按RESET按键重启,OLED显示内容如下图:

END!
![]()

扫二维码|关注我们
HarmonyOS社区
电子发烧友与华为官方共建
![]()