高并发(五)--CAS介绍
文章目录
- 悲观锁与乐观锁
-
- 悲观锁
- 乐观锁
- 原子操作类
- CAS
-
- 源码解析
- unsafe
- java8对于原子操作类的优化
- 伪共享
悲观锁与乐观锁
悲观锁
如果是mysql数据库,利用for update关键字+事务。这样的效果就是当A线程走到for update的时候,会把指定的记录上锁,然后B线程过来,就只能等待,A线程修改完数据之后,提交事务,锁就被释放了,这个时候B线程就可以继续做自己的事情了。悲观锁往往是互斥的,这么做是相当影响性能的。
乐观锁
在数据表中加一个版本号的字段:version,这个字段不需要程序员手动维护,是数据库主动维护的,每次修改数据,version都会发生修改。
当version现在是1:
- A线程进来,读到的
version是1。 - B线程进来,读到的
version是1。 - A线程执行了更新的操作:
update stu set name='codebar' where id=1 and version=1,成功。数据库主动把version改成了2。 - B线程执行了更新操作:
update stu set name='hello' where id=1 and version=1
,失败。因为这个时候version的字段已经不是1了。
悲观锁的典型代表是synchronized,乐观锁的典型代表是CAS。
原子操作类
在java中提供了很多的原子操作类,比如AtomicInteger,其中有一个自增的方法。
public class Main {
public static void main(String[] args) {
Thread[] threads = new Thread[20];
AtomicInteger atomicInteger = new AtomicInteger();
for (int i = 0; i < 20; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
atomicInteger.incrementAndGet();
}
});
threads[i].start();
}
join(threads);
System.out.println("x=" + atomicInteger.get());
}
private static void join(Thread[] threads) {
for (int i = 0; i < 20; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果为:
x=20000
这就是原子操作的神奇之处,在高并发的情况下,这种方法会比synchronized更有优势,因为synchronized关键字会让代码串行化,失去了多线程的优势。
例子:有一个需求,一个字段的初始值为0,开三个线程:
- 一个线程执行:当
x=0时,x修改为100 - 一个线程执行:当
x=100时,x修改为50 - 一个线程执行:当
x=50时,x修改为60
public static void main(String[] args) {
AtomicInteger atomicInteger=new AtomicInteger();
new Thread(() -> {
if(!atomicInteger.compareAndSet(0,100)){
System.out.println("0-100:失败");
}
}).start();
new Thread(() -> {
try {
Thread.sleep(500);注意这里睡了一会儿,目的是让第三个线程先执行判断的操作,从而让第三个线程修改失败
} catch (InterruptedException e) {
e.printStackTrace();
}
if(!atomicInteger.compareAndSet(100,50)){
System.out.println("100-50:失败");
}
}).start();
new Thread(() -> {
if(!atomicInteger.compareAndSet(50,60)){
System.out.println("50-60:失败");
}
}).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
运行结果为:
50-60:失败
在这里,调用的方法compareAndSet,首字母就是CAS,而且传递了两个参数,这两个参数是在原生CAS操作中必须要传递的。
CAS
CAS的全称是Compare And Swap,即比较交换。调用原生CAS操作需要确定三个值:
- 要更新的字段:有时被拆分为两个参数:1. 实例 2. 偏移地址
- 预期值
- 新值
源码解析
首先,调用这个方法需要传递两个参数,一个是预期值,一个是新值,这个预期值就是旧值,新值是我们希望修改的值,该方法的内部实现:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
该方法内部调用了unsafe下的compareAndSwapInt方法,除了传递了我们传到此方法的两个参数之外,又传递了两个参数,这两个参数就是我们之前说的实例和偏移地址,this代表是当前类的实例,即AtomicInteger类的实例,偏移地址是我们需要修改的字段在实例的哪个位置。
确定字段的过程不是在java中做的,而是在更底层中做的。
偏移地址是在本类的静态代码中获得的:
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex); }
}
unsafe.objectFileldOffset接收得是Fileld类型的参数,得到的就是对应字段的偏移地址了,这里就是获得value字段在本类,即AtomicInteger中的偏移地址。
value字段的定义:
private volatile int value;
compareAndSwapInt和objectFieldOffset这两个方法的写法是JNI,会调用C或者C++,最终将对应的指定发送给CPU,这是可以保证原子性的。两个方法的定义为:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public native long objectFieldOffset(Field var1);
可以看到这两个方法被native标记了。
对compareAndSwapInt方法的形象解释:
当我们执行compareAndSwapInt方法时,传入10和100,java会和更底层进行通信:老铁,我给你了字段的所属实例和偏移地址,你帮我看一下这个字段的值是不是10,如果是10的话,你就改成100,并且返回true,如果不是的话,不用修改,直接返回false。
其中比较的过程是compare,修改值的过程就是swap,因为是把旧值替换成新值,所以称该过程为CAS。
incrementAndGet的源码:
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
//根据实例和偏移地址获得对应的值
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
incrementAndGet方法会调用到getAndAddInt方法,这里有三个参数:
- var1:实例
- var2:偏移地址
- var4:需要自增的值,这里是1
getAndAddInt方法内部有一个while循环,循环体内部根据实例和偏移地址获得对应的值,这里先称为A,再来看看while里面的判断内容,JDK和更底层进行通讯:嘿!我把实例和偏移地址给你,你帮我看一下这个值是不是A,如果是的话,帮我修改为A+1,返回true,如果不是的话,返回false吧。
问题:为什么需要while循环?
比如同时有两个线程执行到了getIntVolatile方法,拿到的值都是10,其中线程A执行native方法,修改成功,但是线程B就修改失败了,因为CAS操作是可以保证原子性的,所以线程B只能苦逼的再一次循环,这一次拿到的是11,又去执行native方法,修改成功。
像这样的while循环,叫做CAS自旋。
如果并发很高,大量的线程在进行CAS自旋,就会很浪费CPU,在java8之后,对原子操作类进行了一定的优化。
unsafe
Unsafe是不安全的。Unsafe下面有比较多的方法:
objectFieldOffset:接收一个Field类型的参数,返回偏移地址compareAndSwapInt:比较交换,接收四个参数:实例,偏移地址,预期值,新值getIntVolatile:获得值,支持Volatile,接收两个参数:实例,偏移地址
java8对于原子操作类的优化
上面有提到,在高并发之下,N多线程进行自旋竞争同一个字段,这会给CPU造成一定的压力,所以在java8中,提供了更为完善的原子操作类:LongAdder
优化方式:内部维护了一个数组Cell[]和base,Cell[]里面维护了value,在出现竞争的时候,JDK会根据算法,选择一个Cell,对其中的value进行操作,如果还出现竞争,则换一个Cell再次尝试,最终把Cell[]里面的value和base相加,得到最终的结果。
LongAdder类的UML图:

add()方法:
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x)) {
//第一行
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||//第二行
(c = cs[getProbe() & m]) == null ||//第三行
!(uncontended = c.cas(v = c.value, v + x)))//第四行
longAccumulate(x, null, uncontended);//第五行
}
}
- 第一行:||判断,前者判断
cells是否不为空,后者判断CAS是否不成功。
casBase的实现:就是调用compareAndSet方法,判断是否成功:
(1)如果当前没有竞争,返回true;
(2)如果当前有竞争,有线程会返回false。
final boolean casBase(long cmp, long val) {
return BASE.compareAndSet(this, cmp, val);
}
所以第一行代码的意思是:如果cell[]已经被初始化了,或者有竞争,才会进入第二行代码。如果没有竞争,也没有初始化,就不会进入到第二行代码。
如果没有竞争,只会对base进行操作。
- 第二行:||判断,前者判断cs是否为
null,后者判断(cs的长度减1)是否大于0,这两个判断,都是判断Cell[]是否初始化的,如果没有初始化,会进入第五行代码。 - 第三行:如果
cell进行了初始化,通过getProbe()& m算法得到一个数字,判断cs[数字]是否为null,并且把cs[数字]赋值给了c,如果为null,会进入第五行代码。
getProbe()函数:
static final int getProbe() {
return (int) THREAD_PROBE.get(Thread.currentThread());
}
private static final VarHandle THREAD_PROBE;
这个算法是根据THREAD_PROBE算出来的。
- 第四行代码:对c进行
CAS操作,看是否成功,并把返回值赋值给uncontended,如果当前没有竞争,就会成功,如果当前有竞争,就会失败,在外面有一个取非符号,所以如果CAS失败了,会进入第五行代码,需要注意的是,这里已经对cell元素进行操作了。 - 第五行代码:具体实现:
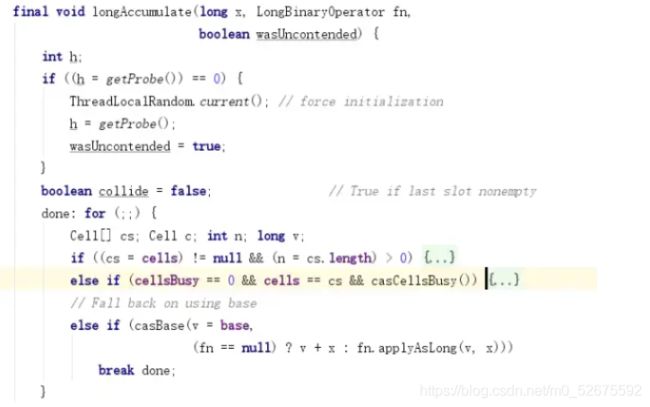
有三个if:
- 判断
cells是否被初始化了,如果被初始化了,进入这个if
该if中的具体内容:

第一个判断:根据算法,拿出cs[]中的一个元素,并且赋值给c,然后判断是否为NULL,如果为NULL,进入这个if,其中的具体内容:
if (cellsBusy == 0) {
// 如果cellsBusy==0,代表现在“不忙”,进入这个if
Cell r = new Cell(x); //创建一个Cell
if (cellsBusy == 0 && casCellsBusy()) {
//再次判断cellsBusy ==0,加锁,这样只有一个线程可以进入这个if
//把创建出来Cell元素加入到Cell[]
try {
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
break done;
}
} finally {
cellsBusy = 0;//代表现在“不忙”
}
continue; // Slot is now non-empty
}
}
collide = false;
初始化Cell[]的时候,其中一个元素是Null,这里对这个为空的元素初始化,也就是只有用到了这个元素,才去初始化。
第六个判断:判断cellsBusy是否为0,并且加锁,如果成功,进入这个if,对Cell[]进行扩容。
try {
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue;
扩容Cell[]的时候,利用CAS加了锁,所以保证线程的安全性
最外面是一个for(;;)死循环,只有break了,才终止循环。
一开始collode为false,在第三个if中,对cell进行CAS操作,如果成功,就break了,所以我们需要假设它是失败的,进入第四了if,第四个if中会判断cell的长度是否大于CPU核心数,如果小于核心数,就会进入第五个判断,这个时候collode为false,会进入这个if,把collode改为true,代表有冲突,然后跑到advanceProbe方法,生成一个新的THREAD_PROBE,再次循环。
如果在第三个if中,CAS还是失败,再次判断Cell[]的长度是否大于核心数,如果小于核心数,会进入第五个判断,这个时候collode为true,所以不会进入到第五个if中去了,这样就进入了第六个判断,进行扩容。
cell[]的扩容时机:当cell[]的长度小于CPU核心数,并且已经两次Cell CAS失败了。
第三个判断:
final boolean casCellsBusy() {
return CELLSBUSY.compareAndSet(this, 0, 1);
}
cas设置CELLSBUSY为1,可以理解为加了个锁,因为马上就要初始化了。
try {
// Initialize table
if (cells == cs) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
break done;
}
} finally {
cellsBusy = 0;
}
初始化cell[],可以看到长度为2,根据算法,对其中的一个元素进行初始化,也就是此时cell[]的长度为2,但是里面有一个元素还是Null,现在只是对其中一个元素进行了初始化,最终把cellsBusy修改成了0,代表现在不忙了。
当出现竞争,且cell[]还没有被初始化的时候,会初始化cell[]
初始化的规则是创建长度为2的数组,但是只会初始化其中的一个元素,另外一个元素为NULL。
在对cell[]进行初始化的时候,是利用CAS加了锁,所以可以保证线程安全。
3. 如果上面都失败了,对base进行CAS操作
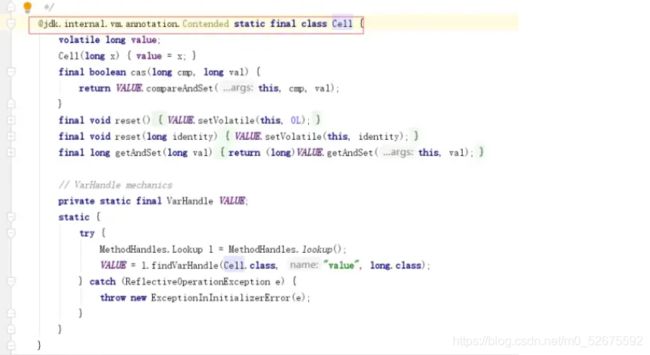
Contended是用来解决伪共享的。
伪共享
CPU与内存的关系:
当CPU需要一个数据,先去缓存中找,如果缓存没有,会去内存找,找到了,就把数据复制到缓存中去,下次直接去缓存中取出即可。
在缓存中的数据,是以缓存行的形式存储的,就是一个缓存行可能不止一个数据,假如一个缓存行的大小是64字节,CPU去内存中取数据,会把临近的64字节的数据都取出来,然后复制到缓存中。对于单线程,这是一种优化,如果CPU需要A数据,把临近的BCDE数据都从内存中取出来,并放入缓存中,CPU如果再需要BCDE数据,就可以直接去缓存中取了。但是在多线程下就有劣势了,因为同一缓存行的数据,同时只能被一个线程读取,这就叫伪共享,有一个解决办法是:如果缓存行的大小是64字节,可以加上一些冗余字段来填充到64字节。但是这种方式不够优雅,所以在Java8中推出了@jdk.internal.vm.annotation.Contended注解,来解决伪共享问题,但是如果开发者想用这个注解,需要添加JVM参数。
感谢并参考:
https://mp.weixin.qq.com/s/GPEHpzQvAXNvH0i__Hok4Q