字符集和字符集编码区别
在说Unicode、utf-8\utf-16之前,我们必须要明晰两个概念:字符集 和 字符集编码。这是很多人都混淆不解之处。
字符集:可以理解为一张写满字符的表,并且每个字符都附带一个唯一的索引序号。
字符集编码:其实也许说成“字符集编码格式”会更好理解。它是指一个算法,通过这个算法可以算出 字符集上的某一个字符 应该以什么格式记录在硬盘中 或者 序列化网络传输。
注意!字符集编码 是我们需要将数据保存到硬盘或网络传输时才需要进行的操作,操作完毕后我们 会得到字符在 硬盘中的存储格式!!举个例子,Unicode是一个字符集,而 它有 utf-8、utf-16等几种存储方式。Unicode定义了 字符的索引序号,而utf-8\utf-16则定义了这个字符怎么存储或传输!
Unicode字符集上定义了 '罗' 的索引序号是 : 0x7F57,看下图:
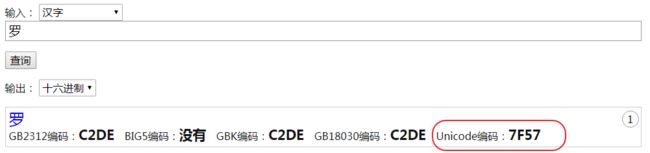
那么当我们需要 将 '罗' 存储在 文本中的时候,我们并不是直接存储0x7F57,而是将0x7F57进行转化(格式)后再存到文本。这个格式化,就是所谓的字符集编码。例如我们将 '罗' 以utf-8的格式:0xE7BD97 存储到文本(硬盘)中。
同样地,其他字符集亦然。不过GBK、GB2312字符集 和字符集编码同名。碰巧的还有,GBK、GB2312字符集 和字符集编码后的格式 也是恰好一致。
tips:在这里介绍一个在线查询字符集的工具:http://www.qqxiuzi.cn/bianma/zifuji.php
Unicode字符集
人类发展至今,不少民族内部会发展出自己一套的字符。每个国家也有每个国家的文字字符。如此一来字符集太多了,在互联网大发展的20世纪里,如果不统一,势必妨碍全球软件之间的交互。因此Unicode字符集出世,它为全世界所有字符都统一分别定义了唯一编号。
UNICODE,全称 “Universal Multiple-Octet Coded Character Set”,简称UCS。
[下面部分摘抄自网络]
UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于 ascii 里的那些”半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高 8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。如 ‘a’ --> 0x0061
但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。(其实发展至今,UNICODE 已经扩展了好多字符,目前的UNICODE 字符集上的字符已经有部分是包含4个字节的了,见下方的Utf-16。这个变化也是对java的对字符的字节定义有影响。后面会写一篇博文介绍。)
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8 就是每次8个位传输数据,而 UTF16 就是每次16个位,只不过为了传输时的可靠性,从UNICODE到 UTF时并不是直接的对应,而是要过一些算法和规则来转换。
UTF8字符编码
上面说道Unicode字符集会存在 Ascii字符浪费字节(实质是浪费磁盘、网络带宽)问题,所以这个问题必须要改进。要想既不在Ascii字符上浪费字节空间、又可以兼顾全球那么多的字符,我们很容易就往这方面想:当存储Ascii字符就用一个字节,当存储其他复杂字符就用两个字节或更多字节。就是 多字节编码方案。
不过要设计多字节编码方案需要考虑如下问题:如果使用多字节表示符号,那么,机器在读取的时候,它怎么知道3个字节表示一个符号,还是表示3个符号。
于是UTF-8 登场了。
Utf-8正是设计出来符合上述多字节需求以及可以让机器识别的方案。
如下图,我们可以归纳出UTF-8的特点:
1. 可变字节。可以 用 1,2,3 或 4 个字节表示一个字符;也可以表示足够多的字符。
2. 明显,Ascii字符集 中的字符 用一个字节。越偏门的字符则只能用越多字节表示。
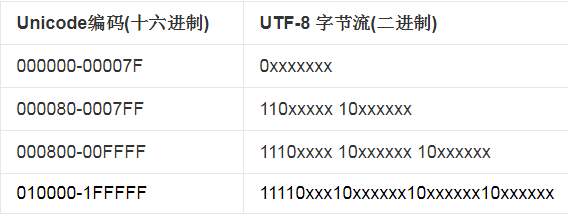
下面我们看看如何从Unicode索引序号 转化到 utf-8 存储格式:
拿 ‘罗’ 做例子:0x7F57,二进制对应的是:0111111101010111。明显是落在000800-00FFFF范围。我们将对应的二进制从从左到右排入UTF-8的第三行中,因此对应的是:
111001111011110110010111
你会发现,刚好等于0xE7BD97
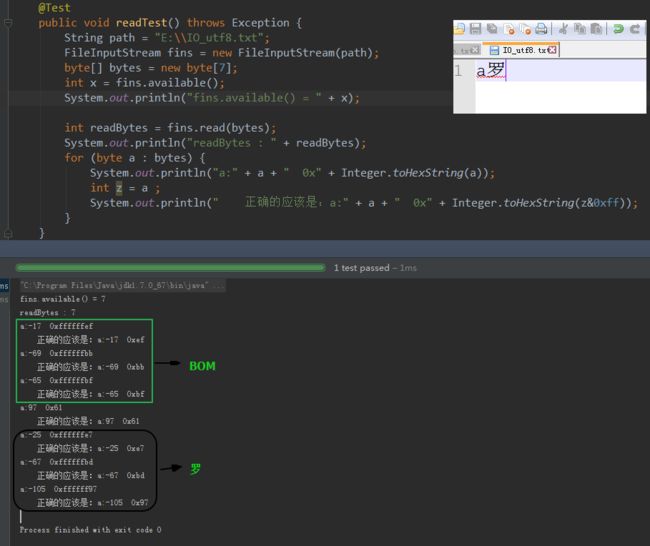
utf-8多字节方案之所以能够让机器辨别,是因为其特殊的格式。假如你编写一个记事本程序,并且你知道文件是utf-8格式的,当你读入文件字节流后要把它映射成文字字符,首先你判断第一个字节是 >=11100000 ,那么意味者你后面只要再读入紧随的两个字节(10xxxxx 10xxxx)就是一个字符的完整的utf-8字节了。
UTF16字符编码
对于日常常见字符,Utf-16字符编码格式,跟平时字符在Unicode字符集中的索引序号一致的,都是两个字节(16bit)。不过发展到后面,Unicode扩展字符集,两个字节已经不够表示,于是就一直扩展到四个字节。同样,Utf-16也只能增加到 4字节 来表示。因此Utf-16 是2 或 4字节的,也属于变长字符编码方案。可是这里要注意,对于超过两个字节才能表示的Unicode字符(增补字符),其Utf-16编码格式不再与其Unicode索引序号一致,而是有一套巧妙的转化算法。
细节如下:
1.Unicode值小于0x10000(即小于等于0xFFFF)的用等于该值的16位整数来表示。
2.Unicode值介于0x10000和0x10FFFF之间的,用一个值介于0xD800和0xDBFF(在所谓的高8位区)的16位整数和值介于0xDC00和0xDFFF(在所谓的低8位区)的16位整数来表示。
3.Unicode值大于0x10FFFF不能按照UTF-16进行编码。

注意:在0xD800和0xDFFF间的值是特别为UTF-16预留,所以不应该将任何字符的值指定为这个区间内的数值.UTF-16比起UTF-8,好处在于大部分字符都以固定长度的字节(2字节)储存,但UTF-16却无法相容于ASCII编码。
Unicode转UTF-16 算法:
将某个字符的Unicode值转换为UTF-16的编码按照以下步骤进行。假设U是给Unicode值,小于x10FFFF。
1) 如果U < 0x10000,U的编码就是无符号的十六位整数,值和其本身的值一样,处理结束。
2) 如果U等于或者小于0x10FFFF,则设U' = U - 0x10000。此时,U'一定小于或者等于0xFFFFF,也就是说,U'的值不会超过20位。
3) 分别初始化2个16位无符号的整数,W1和W2为0xD800和0xDC00。每个整数都有10位可以用来对字符进行编码,正好能容纳U'的20位。
4) 将U'的高10位分配给W1的低10位,将U'的低10位分配给W2的低10位,处理结束。
用数字来表示,第2步到第4步如下所示:
U' = yyyyyyyyyyxxxxxxxxxx
W1 =0xD800 +yyyyyyyyyy= 1101100000000000+ yyyyyyyyyy=110110yyyyyyyyyy
W2 =0xDC00+ xxxxxxxxxx= 1101110000000000+ xxxxxxxxxx=110111xxxxxxxxxx
JDK中具体转化代码如下:
计算高代理位:
java.lang.Character#highSurrogate

计算低代理位:
java.lang.Character#lowSurrogate

上述的算法计算出来的两个char 合起来 就是增补字符 在JVM中的内码。
其实jvm,即java运行时,每个字符的内码并非直接是Unicode字符表上的索引序号,更准确地说应该是Utf-16格式。之所以网上会很多人说是Unicode,是因为对于常见字符,Unicode中的索引序号和Utf-16编码格式 是“长得一样”的。
UTF32字符编码
Utf-32字符编码格式,则是用4个字节(32bit)。
BOM渊源
Unicode系列字符集编码后存储到磁盘、内存、网络传输时,还有一个BOM 的特点。全称:Byte Order Mark,“字节序标识”。
BOM,有两种:BE(BigEndian“大头”),LE(LittleEndian,“小头”)。其实就是 存储 编码后的结果 时是 将每个字节按顺序存储(BE)还是按倒序存储(LE)。
如'a',UTF-16编码后的结果按BE方式存储,就是0061,高位‘00’放前头;按LE方式存储,则是6100,即高位‘00’放后面。
再如'罗':
UTF-16BE存储:7F57;UTF-16LE存储:577F;
UTF-8BE存储:E7BD97;UTF-8LE存储:97BDE7;
这样子的话,问题就来了:当记事本程序读取某个txt文本时,怎么知道是BE存储还是LE?这就是BOM出现的意义了。
Unicode字符集中,FEFF 和 FFFE两个序号 是没有对应的字符的,因此UTF-16格式编码中,人们就在存储文本内容时用它们来作为BE 和 LE 的区分识别标志。其中,BE-->FEFF , LE-->FFFE。
这里有个细节要注意:FEFF 被叫做"ZERO WIDTH NO-BREAK SPACE"字符,中文:”零宽度无中断空格“,它其实是一个空格字符,只是没人被显示出来(人眼看不见、跟没有一样)。而FFFE,则是真的没有意义,没有对应的字符。所以,平时你写网络传输utf-16字符字节流程序时,记得可以传FEFF,就别传FFFE了,对方接收到也是根据其 是否有FEFF 就可以知道你传过来的是 BE还是LE了。(这其实是要发送接收双方协商好)
UTF-8也有BOM的, [0xEF, 0xBB, 0xBF] (你可以通过将FEFF按照上面的方式转化得到),但可有可无, 但用windows的notepad另存为时会自动帮你加上这个, 而很多非windows平台的UTF8文件又没有这个BOM。不过虽然说UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
不过如果UTF-8可以没有BOM,那么在采用GBK默认编码的中文windows中,我们如何识别一个文本文件是UTF-8和GBK?如果我说是用猜,你会否惊讶?可现实真是如此:
其实我们真只能按大量的编码分析来区分。我们平时使用的Notepad++等一些常用的IDE,PHP的mb_系列函数,python的chardet库及其它语言衍生版如jchardet,jschardet等 都在“猜编码”方面非常准。那么这些库是怎么区分这些编码的呢?那就是词库,你会看到库的源码里有大量的数组,其实就是对应一个编码里的常见词组编码组合。同样的文件字节流在一个词组库里的匹配程度越高,就越有可能是该编码,判断的准确率就越大。而文件中的中文越少越零散,判断的准确率就越低。
感慨:看完上面那么多历史渊源,我们才能写好一个相对“智能”的记事本程序啊。
生活场景:
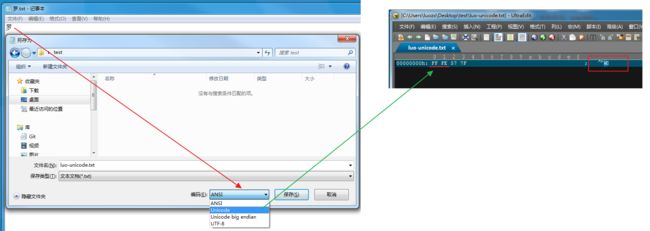
(1)我们在window系统中新建一个记事本,输入'罗'。此时的字符是ANSI编码格式的,即GBK。
(2)如下图,当我们“另存”-> 选择 Unicode big endian ,记事本程序将 内存中的内容 刷到硬盘时,会偷偷地先存储FEFF后再追加存我们的内容。
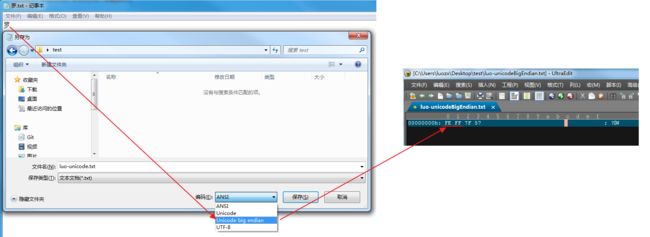
(3)如果我们将 另存为 Unicode,window记事本则 偷偷帮我们 在开头加入 FF FE。
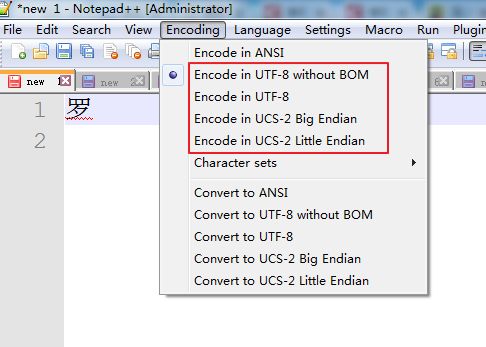
其实在NotePad++中,我们会有更多的选择,如Utf-8 with BOM 等:
其实看到这里,很多人都会产生一个疑问:为什么那么费劲地搞出BE和LE的两种存储方式呢?
具体原因要说到不同CPU读取数据的方式,涉及到汇编知识,读者们自己去百度吧。目的都是为了让CPU更高效。
[后面我会补一遍java程序如何读取和创建存储unicode文本文件的演示。]