今天我们先来看两个经典的面试题:
1、应用程序启动 在
main函数之前都具体做了哪些内容?2、
load在什么时候调用?子类、父类以及分类load的调用顺序?
带着这几个问题我们开始本节的内容:
- 1、App编译/启动流程及动态链接器dyld
- 2、map_images流程分析
- 3、load_images流程分析
- 4、面试题答案(仅供参考~)
一、App编译流程及启动流程dyld
下面图示编译流程
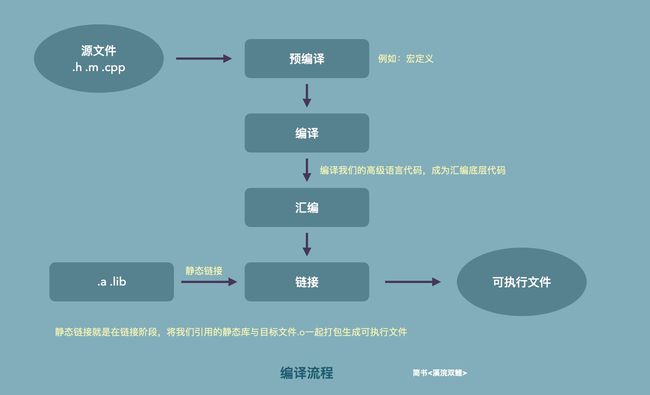
注意:只有静态库会在编译阶段会打包进入可执行文件,动态库是在程序运行时才会被加入可执行文件。静态库与动态库知识点深入传送门
应用程序启动前,会先对代码进行编译,在编译阶段会把静态库打包到可执行性文件中,编译完成后,进入启动阶段,谈及App启动流程,肯定少不了我们的动态链接器dyld,整个启动过程都是它在进行协调,dyld操作流程如下图:
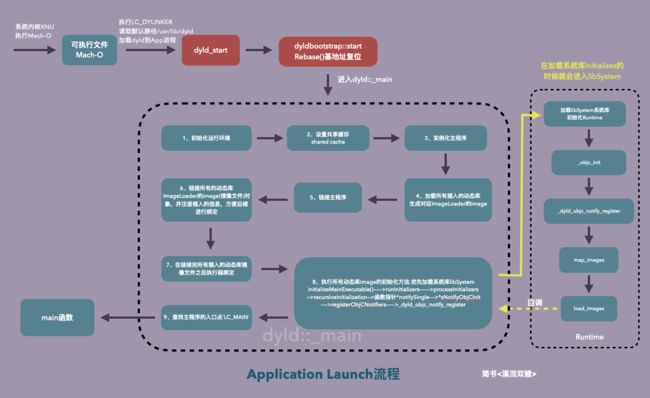
从App启动角度深入了解dyld
其实在App启动过程中主要分为main函数之前和main函数之后,main函数之后就是从main函数到我们第一个视图出现的这段时间。先来看一下main()之前主要做了哪些操作:
main()之前通过调用dyld对主程序运行环境初始化,生成imageLoader把动态库生成对应的image镜像文件,载入到内存中,然后进行链接绑定,接着初始化所有动态库,在执行所有插入的动态库初始化的时候,同时也对load_images进行了绑定。执行初始化这个过程中,会优先初始化系统库libSystem,运行起来Runtime,这个过程会进入Runtime的入口函数_objc_init,接下来把之前链接的动态库及符号都交给Runtime进行map_images和load_images操作,然后Runtime执行完load_images之后会回调到dyld内部,dyld收到信息回调后,最后查找main()函数的入口LC_MAIN,找到后就会调起我们的main()函数,进入我们开发者的代码。
接下来结合文章开始的面试题,我们就来仔细分析一下Runtime的map_images和load_images流程中间做了哪些操作?
二、map_images流程分析
Objc源码下载地址
还是从系统库libSystem的Runtime入口函数_objc_init开始分析:
/***********************************************************************
* _objc_init
* Bootstrap initialization. Registers our image notifier with dyld.
* Called by libSystem BEFORE library initialization time
**********************************************************************/
void _objc_init(void)
{
static bool initialized = false;
if (initialized) return;
initialized = true;
// fixme defer initialization until an objc-using image is found?
//读取影响运行时的环境变量。
environ_init();
tls_init();
//运行C ++静态构造函数。libc在dyld调用我们的静态构造函数之前调用_objc_init()
static_init();
lock_init();
//初始化libobjc的异常处理系统。由map_images()调用。
exception_init();
注册回调函数
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
}
接下来我们开始进入map_images:
void
map_images(unsigned count, const char * const paths[],
const struct mach_header * const mhdrs[])
{
mutex_locker_t lock(runtimeLock);
return map_images_nolock(count, paths, mhdrs);
}
进来后发现map_images直接返回了map_images_nolock。
先来看一下map_images函数的注释部分,我们得知:map_images主要作用就是处理由dyld映射的image(此处的image泛指二进制可执行程序)。
继续点进入map_images_nolock的实现部分, 我们来分析这里面主要做了什么:
void
map_images_nolock(unsigned mhCount, const char * const mhPaths[],
const struct mach_header * const mhdrs[])
{
定义一系列变量
......
必要时执行首次初始化
//如果是第一次,就准备初始化环境
if (firstTime) {
preopt_init();
}
// Find all images with Objective-C metadata.
hCount = 0;
计算class数量,根据总数调整各种表的大小。
// Count classes. Size various table based on the total.
int totalClasses = 0;
int unoptimizedTotalClasses = 0;
{
uint32_t i = mhCount;
while (i--) {
const headerType *mhdr = (const headerType *)mhdrs[i];
auto hi = addHeader(mhdr, mhPaths[i], totalClasses, unoptimizedTotalClasses);
if (!hi) {
// no objc data in this entry
continue;
}
if (mhdr->filetype == MH_EXECUTE) {
// Size some data structures based on main executable's size
#if __OBJC2__
size_t count;
_getObjc2SelectorRefs(hi, &count);
selrefCount += count;
_getObjc2MessageRefs(hi, &count);
selrefCount += count;
#else
_getObjcSelectorRefs(hi, &selrefCount);
#endif
#if SUPPORT_GC_COMPAT
// Halt if this is a GC app.
if (shouldRejectGCApp(hi)) {
_objc_fatal_with_reason
(OBJC_EXIT_REASON_GC_NOT_SUPPORTED,
OS_REASON_FLAG_CONSISTENT_FAILURE,
"Objective-C garbage collection "
"is no longer supported.");
}
#endif
}
hList[hCount++] = hi;
if (PrintImages) {
_objc_inform("IMAGES: loading image for %s%s%s%s%s\n",
hi->fname(),
mhdr->filetype == MH_BUNDLE ? " (bundle)" : "",
hi->info()->isReplacement() ? " (replacement)" : "",
hi->info()->hasCategoryClassProperties() ? " (has class properties)" : "",
hi->info()->optimizedByDyld()?" (preoptimized)":"");
}
}
}
......
执行一次运行时初始化,必须将其推迟到找到可执行文件本身为止。 这需要在进一步初始化之前完成。(如果可执行文件不包含Objective-C代码,但稍后会动态加载Objective-C,则该可执行文件可能不会出现在此infoList中。
if (firstTime) {
//初始化sel方法表 并注册系统内部专门的方法。
sel_init(selrefCount);
arr_init();
#if SUPPORT_GC_COMPAT
// Reject any GC images linked to the main executable.
// We already rejected the app itself above.
// Images loaded after launch will be rejected by dyld.
for (uint32_t i = 0; i < hCount; i++) {
auto hi = hList[i];
auto mh = hi->mhdr();
if (mh->filetype != MH_EXECUTE && shouldRejectGCImage(mh)) {
_objc_fatal_with_reason
(OBJC_EXIT_REASON_GC_NOT_SUPPORTED,
OS_REASON_FLAG_CONSISTENT_FAILURE,
"%s requires Objective-C garbage collection "
"which is no longer supported.", hi->fname());
}
}
#endif
#if TARGET_OS_OSX
// Disable +initialize fork safety if the app is too old (< 10.13).
// Disable +initialize fork safety if the app has a
// __DATA,__objc_fork_ok section.
if (dyld_get_program_sdk_version() < DYLD_MACOSX_VERSION_10_13) {
DisableInitializeForkSafety = true;
if (PrintInitializing) {
_objc_inform("INITIALIZE: disabling +initialize fork "
"safety enforcement because the app is "
"too old (SDK version " SDK_FORMAT ")",
FORMAT_SDK(dyld_get_program_sdk_version()));
}
}
for (uint32_t i = 0; i < hCount; i++) {
auto hi = hList[i];
auto mh = hi->mhdr();
if (mh->filetype != MH_EXECUTE) continue;
unsigned long size;
if (getsectiondata(hi->mhdr(), "__DATA", "__objc_fork_ok", &size)) {
DisableInitializeForkSafety = true;
if (PrintInitializing) {
_objc_inform("INITIALIZE: disabling +initialize fork "
"safety enforcement because the app has "
"a __DATA,__objc_fork_ok section");
}
}
break; // assume only one MH_EXECUTE image
}
#endif
}
直接开始image读取
if (hCount > 0) {
_read_images(hList, hCount, totalClasses, unoptimizedTotalClasses);
}
firstTime = NO;
}
对源码进行分析, map_images_nolock 方法的流程如下:
1、 判断是不是第一次,如果是第一次,那么就开始准备初始化环境
if (firstTime) {
preopt_init();
}
2、计算class数量,根据总数调整各种表的大小(这个步骤里面会判断GC(Garbage Collection),因为Objective-C之前是做了垃圾回收机制兼容的,现在则不支持了。尽管目前不支持GC了,但是苹果并没有删除这些兼容性代码)
// Count classes. Size various table based on the total.
int totalClasses = 0;
int unoptimizedTotalClasses = 0;
{
uint32_t i = mhCount;
while (i--) {
调整表的大小部分操作
......
GC相关逻辑判断
#if SUPPORT_GC_COMPAT
// Halt if this is a GC app.
if (shouldRejectGCApp(hi)) {
_objc_fatal_with_reason
(OBJC_EXIT_REASON_GC_NOT_SUPPORTED,
OS_REASON_FLAG_CONSISTENT_FAILURE,
"Objective-C garbage collection "
"is no longer supported.");
}
#endif
}
hList[hCount++] = hi;
}
}
3、判断是不是首次执行,如果是,会初始化各种表
if (firstTime) {
sel_init(selrefCount);
arr_init();
......
继续逻辑判断GC相关
#if SUPPORT_GC_COMPAT
......
#endif
}
4、接着开始读取images,并将firstTime置为 NO
//判断,然后进行images读取
if (hCount > 0) {
_read_images(hList, hCount, totalClasses, unoptimizedTotalClasses);
}
//将firstTime置为NO,下次就不重新创建表了
firstTime = NO;
总结map_images_nolock的流程就是:
- 判断
firstTime,firstTime为YES,则执行环境初始化的准备,为NO就不执行 - 计算class数量,根据总数调整各种表的大小并做了GC相关逻辑处理(不支持GC则打印提示信息)
- 判断
firstTime,firstTime为YES,执行各种表初始化操作,为NO则不执行 - 执行
_read_images进行读取,然后将firstTime置为NO,就不再进入上面的逻辑了,下次进入map_images_nolock就开始直接_read_images
接下来我们重点分析_read_images底层实现,看看到底做了哪些主要操作,进入源码实现如下:
/***********************************************************************
* _read_images
* Perform initial processing of the headers in the linked
* list beginning with headerList.
*
* Called by: map_images_nolock
*
* Locking: runtimeLock acquired by map_images
**********************************************************************/
void _read_images(header_info **hList, uint32_t hCount, int totalClasses, int unoptimizedTotalClasses)
{
定义一系列局部变量
......
1. 重新初始化TaggedPointer环境****************
if (!doneOnce) {
doneOnce = YES;
......
if (DisableTaggedPointers) {
disableTaggedPointers();
}
initializeTaggedPointerObfuscator();
......
注意!!!!!创建表gdb_objc_realized_classes和allocatedClasses
......
int namedClassesSize =
(isPreoptimized() ? unoptimizedTotalClasses : totalClasses) * 4 / 3;
gdb_objc_realized_classes =
NXCreateMapTable(NXStrValueMapPrototype, namedClassesSize);
allocatedClasses = NXCreateHashTable(NXPtrPrototype, 0, nil);
......
}
// Discover classes. Fix up unresolved future classes. Mark bundle classes.
2. 开始遍历头文件,进行类与元类的读取操作并标记(旧类改动后会生成新的类,并重映射到新的类上)************************
for (EACH_HEADER) {
//从头文件中拿到类的信息
classref_t *classlist = _getObjc2ClassList(hi, &count);
if (! mustReadClasses(hi)) {
// Image is sufficiently optimized that we need not call readClass()
continue;
}
bool headerIsBundle = hi->isBundle();
bool headerIsPreoptimized = hi->isPreoptimized();
for (i = 0; i < count; i++) {
Class cls = (Class)classlist[i];
//!!!!!!核心操作,readClass读取类的信息及类的更新
Class newCls = readClass(cls, headerIsBundle, headerIsPreoptimized);
......
}
}
......
3. 读取@selector*************************************
// Fix up @selector references
static size_t UnfixedSelectors;
{
mutex_locker_t lock(selLock);
for (EACH_HEADER) {
if (hi->isPreoptimized()) continue;
bool isBundle = hi->isBundle();
SEL *sels = _getObjc2SelectorRefs(hi, &count);
UnfixedSelectors += count;
for (i = 0; i < count; i++) {
const char *name = sel_cname(sels[i]);
sels[i] = sel_registerNameNoLock(name, isBundle);
}
}
}
......
4. 读取协议protocol*************************************
// Discover protocols. Fix up protocol refs.
for (EACH_HEADER) {
extern objc_class OBJC_CLASS_$_Protocol;
Class cls = (Class)&OBJC_CLASS_$_Protocol;
assert(cls);
NXMapTable *protocol_map = protocols();
bool isPreoptimized = hi->isPreoptimized();
bool isBundle = hi->isBundle();
protocol_t **protolist = _getObjc2ProtocolList(hi, &count);
for (i = 0; i < count; i++) {
readProtocol(protolist[i], cls, protocol_map,
isPreoptimized, isBundle);
}
}
......
5. 处理分类category,并rebuild重建这个类的方法列表method list*******************************
// Discover categories.
for (EACH_HEADER) {
category_t **catlist =
_getObjc2CategoryList(hi, &count);
bool hasClassProperties = hi->info()->hasCategoryClassProperties();
for (i = 0; i < count; i++) {
category_t *cat = catlist[i];
Class cls = remapClass(cat->cls);
......
bool classExists = NO;
if (cat->instanceMethods || cat->protocols
|| cat->instanceProperties)
{
addUnattachedCategoryForClass(cat, cls, hi);
if (cls->isRealized()) {
remethodizeClass(cls);
classExists = YES;
}
if (PrintConnecting) {
_objc_inform("CLASS: found category -%s(%s) %s",
cls->nameForLogging(), cat->name,
classExists ? "on existing class" : "");
}
}
if (cat->classMethods || cat->protocols
|| (hasClassProperties && cat->_classProperties))
{
addUnattachedCategoryForClass(cat, cls->ISA(), hi);
if (cls->ISA()->isRealized()) {
remethodizeClass(cls->ISA());
}
if (PrintConnecting) {
_objc_inform("CLASS: found category +%s(%s)",
cls->nameForLogging(), cat->name);
}
}
}
}
......
if (DebugNonFragileIvars) {
realizeAllClasses();
}
最后是一堆打印***********
......
}
_read_images的实现主要分为以下步骤:
- 重新初始化TaggedPointer环境
- 开始遍历头文件,进行类与元类的读取操作并标记(旧类改动后会生成新的类,并重映射到新的类上)
- 读取@selector方法
- 读取协议protocol
- 处理分类category,并rebuild重建这个类的方法列表method list
既然是读取类,类的结构中包含类本身以及类的所有信息(例如分类,方法,协议)。
下面我们就针对这些我们想知道的内容进行分析:类与元类的读取、方法@selector的读取、协议protocol的读取以及分类category的读取
第1步、重新初始化TaggedPointer环境
判断doneOnce,如果doneOnce为NO,则首先重置及初始化taggedPointer,然后创建两个表,一个叫gdb_objc_realized_classes用来存放已命名的类的列表,另一个叫allocatedClasses用来存放已分配的所有类(和元类)
if (!doneOnce) {
doneOnce = YES;//这个逻辑只执行一次
//重置及初始化TaggedPointer环境
if (DisableTaggedPointers) {
disableTaggedPointers();
}
initializeTaggedPointerObfuscator();
//创建表gdb_objc_realized_classes和allocatedClasses
int namedClassesSize =
(isPreoptimized() ? unoptimizedTotalClasses : totalClasses) * 4 / 3;
gdb_objc_realized_classes =
NXCreateMapTable(NXStrValueMapPrototype, namedClassesSize);
allocatedClasses = NXCreateHashTable(NXPtrPrototype, 0, nil);
}
分别点到这两个表的定义部分,根据注释能查看出这两个表大概的作用
// This is a misnomer: gdb_objc_realized_classes is actually a list of
// named classes not in the dyld shared cache, whether realized or not.
gdb_objc_realized_classes实际上是不在dyld共享缓存中的已命名类的列表,无论是否实现
NXMapTable *gdb_objc_realized_classes; // exported for debuggers in objc-gdb.h
/***********************************************************************
* allocatedClasses
* A table of all classes (and metaclasses) which have been allocated
* with objc_allocateClassPair.
**********************************************************************/
static NXHashTable *allocatedClasses = nil;
这里拓展一下这两张表的类型:gdb_objc_realized_classes的类型是NXMapTable,allocatedClasses表的类型是NXHashTable。
可以简单理解NSHashTable、NSMapTable分别对应的是我们常用的NSSet和NSDictionary,并且额外提供了weak指针来使用垃圾回收机制。
NSDictionary底层实现也是使用了NSMapTable(散列表),(备注:苹果官网并没有这些类的实现,想要查看NSDictionary和NSArray的实现源码可以去GNUstep官网下载或者百度网盘下载)
使用NSMapTable是因为它更强大NSMapTable相对于NSDictionary的优势
第2步、类与元类的读取
遍历头文件,进行类与元类的读取操作,读取完后标记
// Discover classes. Fix up unresolved future classes. Mark bundle classes.
for (EACH_HEADER) {
classref_t *classlist = _getObjc2ClassList(hi, &count);
if (! mustReadClasses(hi)) {
// Image is sufficiently optimized that we need not call readClass()
continue;
}
bool headerIsBundle = hi->isBundle();
bool headerIsPreoptimized = hi->isPreoptimized();
for (i = 0; i < count; i++) {
Class cls = (Class)classlist[i];
Class newCls = readClass(cls, headerIsBundle, headerIsPreoptimized);
if (newCls != cls && newCls) {
// Class was moved but not deleted. Currently this occurs
// only when the new class resolved a future class.
// Non-lazily realize the class below.
resolvedFutureClasses = (Class *)
realloc(resolvedFutureClasses,
(resolvedFutureClassCount+1) * sizeof(Class));
resolvedFutureClasses[resolvedFutureClassCount++] = newCls;
}
}
}
其中主要做了readClass来读取编译器编写的类和元类,我们重点来仔细分析一下类的读取过程,进入readClass源码
Class readClass(Class cls, bool headerIsBundle, bool headerIsPreoptimized)
{
const char *mangledName = cls->mangledName();
if (missingWeakSuperclass(cls)) {
// No superclass (probably weak-linked).
// Disavow any knowledge of this subclass.
if (PrintConnecting) {
_objc_inform("CLASS: IGNORING class '%s' with "
"missing weak-linked superclass",
cls->nameForLogging());
}
addRemappedClass(cls, nil);
cls->superclass = nil;
return nil;
}
......
Class replacing = nil;
if (Class newCls = popFutureNamedClass(mangledName)) {
......
class_rw_t *rw = newCls->data();
const class_ro_t *old_ro = rw->ro;
memcpy(newCls, cls, sizeof(objc_class));
rw->ro = (class_ro_t *)newCls->data();
newCls->setData(rw);
freeIfMutable((char *)old_ro->name);
free((void *)old_ro);
addRemappedClass(cls, newCls);
replacing = cls;
cls = newCls;
}
if (headerIsPreoptimized && !replacing) {
......
assert(getClass(mangledName));
} else {
addNamedClass(cls, mangledName, replacing);
addClassTableEntry(cls);
}
......
return cls;
}
从源码中可以看出,readClass方法有返回值,并且包含三种逻辑处理:
- 找不到该类的父类,可能是弱绑定,直接返回nil;
- 找到类了,判断这个类是否是一个future的类(可以理解为需要实现的一个类,也可以理解为这个类是否有变化),如果有变化则创建新类,并把旧类的数据拷贝一份然后赋值给新类newCls,然后调用addRemappedClass进行重映射,用新的类替换掉旧的类,并返回新类newCls的地址
- 找到类了,如果类没有任何变化,则不进行任何操作,直接返回class
从readClass的底层实现部分做个延伸思考:日常开发中,对于已经启动完成的工程项目,如果我们未修改任何类的数据,那么再次点击运行会很快完成,但是一旦我们在对这些类进行修改后,在读取这些类的信息(包括类本身的信息以及下面我们要继续分析的协议protocol、分类category、方法selector),就需要对该类的数据进行更新,这个更新实际上是新建一个类,然后拷贝旧类的数据赋值给新类,然后重映射并用新类替换掉新类,这里面的拷贝以及读写过程其实是相当耗时的!这是类信息改动之后项目再次Run运行起来会比较慢的原因之一。
继续分析,既然做了类信息的读取,那么读取到的数据到底存在哪里呢?在readClass源码最后部分找到这两句代码
addNamedClass(cls, mangledName, replacing);
addClassTableEntry(cls);
先看这两句的第一句代码做了什么:进入addNameClass找到
NXMapInsert(gdb_objc_realized_classes, name, cls);
发现已经读取完成的类,会被存放到了这个表gdb_objc_realized_classes里面!
然后继续看第二句里面做了啥:
static void addClassTableEntry(Class cls, bool addMeta = true) {
runtimeLock.assertLocked();
......
if (!isKnownClass(cls))
NXHashInsert(allocatedClasses, cls);
if (addMeta)
addClassTableEntry(cls->ISA(), false);
}
分析源码注释及源码得出,addClassTableEntry里面会把这个读取完成的类直接先添加到allocatedClasses表里面,然后再判断addMeta是否为YES,然后会把当前这个类的元类metaClass也添加到allocatedClasses这个表里面。
这里是一个递归的逻辑,我们需要来分析一下:由于我们上一步是这样直接调用的:
addClassTableEntry(cls);
所以进入这个方法的时候,只传入了一个cls并没有传入addMeta,所以这里addMeta默认就是YES,然后继续递归调用当前addClassTableEntry,注意:第二次递归调用的时候,addMeta传入的是false,所以第二次就不会再添加元类了,这里的逻辑主要是保证元类只添加一次。所以addClassTableEntry里面其实是做了把类和元类都加到allocatedClasses表里面。
到此为止,类和元类的读取我们已经明白了,下面用同样的分析,分析类的方法、协议以及分类
第3步、方法@selector的读取
接下来进到第四部的代码部分
// Fix up @selector references
static size_t UnfixedSelectors;
{
mutex_locker_t lock(selLock);
for (EACH_HEADER) {
if (hi->isPreoptimized()) continue;
bool isBundle = hi->isBundle();
SEL *sels = _getObjc2SelectorRefs(hi, &count);
UnfixedSelectors += count;
for (i = 0; i < count; i++) {
const char *name = sel_cname(sels[i]);
sels[i] = sel_registerNameNoLock(name, isBundle);
}
}
}
点击sel_registerNameNoLock,找到__sel_registerName,在它里面找到关键代码
if (!namedSelectors) {
namedSelectors = NXCreateMapTable(NXStrValueMapPrototype,
(unsigned)SelrefCount);
}
if (!result) {
result = sel_alloc(name, copy);
// fixme choose a better container (hash not map for starters)
NXMapInsert(namedSelectors, sel_getName(result), result);
}
逻辑其实就是:把方法名插入并存储到namedSelectors这个表里面.
第4步,协议protocol的读取
// Discover protocols. Fix up protocol refs.
for (EACH_HEADER) {
extern objc_class OBJC_CLASS_$_Protocol;
Class cls = (Class)&OBJC_CLASS_$_Protocol;
assert(cls);
创建表protocol_map
NXMapTable *protocol_map = protocols();
bool isPreoptimized = hi->isPreoptimized();
bool isBundle = hi->isBundle();
拿到头文件中协议列表
protocol_t **protolist = _getObjc2ProtocolList(hi, &count);
for (i = 0; i < count; i++) {
读取protocol
readProtocol(protolist[i], cls, protocol_map,
isPreoptimized, isBundle);
}
}
找到关键函数readProtocol,进入发现其实读取protocol的操作是把protocol存进协议表protocol_map。
insertFn(protocol_map, installedproto->mangledName, installedproto);
第5步,分类category的读取
来看看分类部分的逻辑
// Discover categories.
for (EACH_HEADER) {
从头文件中找到所有分类
category_t **catlist =
_getObjc2CategoryList(hi, &count);
bool hasClassProperties = hi->info()->hasCategoryClassProperties();
for (i = 0; i < count; i++) {
category_t *cat = catlist[i];
Class cls = remapClass(cat->cls);
根据分类,获取分类对应的类
if (!cls) {
如果分类所属的类找不到,那么就会把这个这个分类category_t置为nil
......
catlist[i] = nil;
......
continue;
}
......
如果分类所属的类找到了,那么判断这个分类里面的实例方法instanceMethods,协议protocols,以及属性instanceProperties是否存在,如果存在,就把这些方法分别同步更新到对应的类和元类中
bool classExists = NO;
//把分类新增的方法、协议、属性都添加到类中
if (cat->instanceMethods || cat->protocols
|| cat->instanceProperties)
{
addUnattachedCategoryForClass(cat, cls, hi);
if (cls->isRealized()) {
remethodizeClass(cls);
classExists = YES;
}
......
}
//把分类新增的方法、协议、属性都添加到元类中
if (cat->classMethods || cat->protocols
|| (hasClassProperties && cat->_classProperties))
{
addUnattachedCategoryForClass(cat, cls->ISA(), hi);
if (cls->ISA()->isRealized()) {
remethodizeClass(cls->ISA());
}
......
}
}
}
总结一下分类category的读取,里面主要做了下面这些步骤:
- 从头文件中获取所有的分类列表
catlist,然后循环遍历这个列表 - 在循环中,判断当前分类
cat所属的类是否存在,如果不存在则把这个分类置为空catlist[i] = nil; 如果这个分类所属的类存在,那么开始下面两个步骤: - 第一个步骤:判断这个分类
cat中是否有实例方法instanceMethods,协议protocols以及属性实例instanceProperties,如果有,那么进入remethodizeClass,重新rebuild当前类cls的方法列表 - 第二个步骤:继续判断这个分类
cat中是否有类方法classMethods,协议protocols以及类属性_classProperties,然后重新rebuild当前类所对应元类cls->ISA()的方法列表。
注意第一步和第二步这两个方法分别对应处理的是分类的类和分类的类对应的元类。处理类调用的是
remethodizeClass(cls);,而处理元类调用的是remethodizeClass(cls->ISA())。
接下来我们进入remethodizeClass方法实现部分继续深究这个方法实现步骤:
static void remethodizeClass(Class cls)
{
category_list *cats;
bool isMeta;
runtimeLock.assertLocked();
isMeta = cls->isMetaClass();
// Re-methodizing: check for more categories
if ((cats = unattachedCategoriesForClass(cls, false/*not realizing*/))) {
......
attachCategories(cls, cats, true /*flush caches*/);
free(cats);
}
}
找到关键实现attachCategories函数,进入
将方法列表以及属性和协议从类别附加到类。
static void
attachCategories(Class cls, category_list *cats, bool flush_caches)
{
if (!cats) return;
if (PrintReplacedMethods) printReplacements(cls, cats);
bool isMeta = cls->isMetaClass();
// fixme rearrange to remove these intermediate allocations
method_list_t **mlists = (method_list_t **)
malloc(cats->count * sizeof(*mlists));
property_list_t **proplists = (property_list_t **)
malloc(cats->count * sizeof(*proplists));
protocol_list_t **protolists = (protocol_list_t **)
malloc(cats->count * sizeof(*protolists));
// Count backwards through cats to get newest categories first
int mcount = 0;
int propcount = 0;
int protocount = 0;
int i = cats->count;
bool fromBundle = NO;
while (i--) {
auto& entry = cats->list[i];
method_list_t *mlist = entry.cat->methodsForMeta(isMeta);
if (mlist) {
mlists[mcount++] = mlist;
fromBundle |= entry.hi->isBundle();
}
property_list_t *proplist =
entry.cat->propertiesForMeta(isMeta, entry.hi);
if (proplist) {
proplists[propcount++] = proplist;
}
protocol_list_t *protolist = entry.cat->protocols;
if (protolist) {
protolists[protocount++] = protolist;
}
}
auto rw = cls->data();
prepareMethodLists(cls, mlists, mcount, NO, fromBundle);
rw->methods.attachLists(mlists, mcount);
free(mlists);
if (flush_caches && mcount > 0) flushCaches(cls);
rw->properties.attachLists(proplists, propcount);
free(proplists);
rw->protocols.attachLists(protolists, protocount);
free(protolists);
}
注意,这里面的类型和Class类中的类型是完全一致并且对应的,下面贴上Class的class_rw_t结构做个对比
struct class_rw_t {
// Be warned that Symbolication knows the layout of this structure.
uint32_t flags;
uint32_t version;
const class_ro_t *ro;
method_array_t methods;
property_array_t properties;
protocol_array_t protocols;
......
}
注意类结构中方法表、属性表、协议表的类型分别是method_array_t、property_array_t、protocol_array_t,而这个三个表底层都是由list_array_tt进行实现的,只不过里面存储的数据类型不相同,这个三个表里面分别对应存储的是method_list_t、property_list_t以及protocol_list_t类型的数据
class method_array_t :
public list_array_tt
{
typedef list_array_tt Super;
public:
method_list_t **beginCategoryMethodLists() {
return beginLists();
}
method_list_t **endCategoryMethodLists(Class cls);
method_array_t duplicate() {
return Super::duplicate();
}
};
class property_array_t :
public list_array_tt
{
typedef list_array_tt Super;
public:
property_array_t duplicate() {
return Super::duplicate();
}
};
class protocol_array_t :
public list_array_tt
{
typedef list_array_tt Super;
public:
protocol_array_t duplicate() {
return Super::duplicate();
}
};
并且list_array_tt在设计的时候,提供了attachList方法,可以调用这个方法往表里继续添加数据
void attachLists(List* const * addedLists, uint32_t addedCount) {
if (addedCount == 0) return;
if (hasArray()) {
// many lists -> many lists
uint32_t oldCount = array()->count;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
array()->count = newCount;
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
else if (!list && addedCount == 1) {
// 0 lists -> 1 list
list = addedLists[0];
}
else {
// 1 list -> many lists
List* oldList = list;
uint32_t oldCount = oldList ? 1 : 0;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)malloc(array_t::byteSize(newCount)));
array()->count = newCount;
if (oldList) array()->lists[addedCount] = oldList;
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
}
所以,通过结合objc_class源码,来对比分析attachCategories源码,我们能够明白attachCategories函数里面主要做了下面的操作:
- 对应Class的结构,新建方法表
method_list_t **mlists、property_list_t **proplists、protocol_list_t **protolists - 根据当前类cls分类的数量,进行while循环,把分类里面包含的方法,协议,属性都加到上面的三个表中
- 获取当前类的
rw,通过rw拿到对应的methods、properties、protocols,然后由于这三个表都是由list_array_tt实现,直接调用list_array_tt的attachLists方法,把category分类里面的方法,协议,属性都添加到当前类的表里面去。
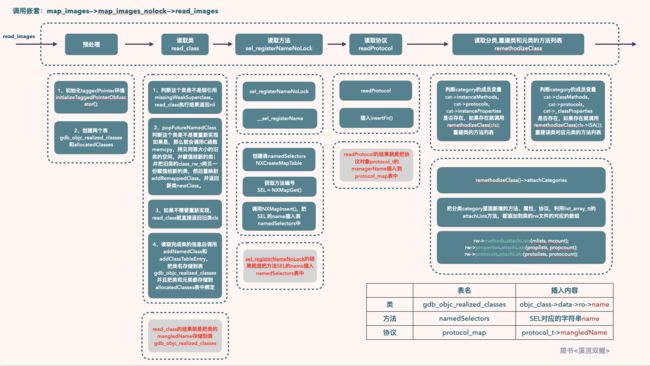
到此,map_images的主要操作都已经分析完成,下面总结一下map_images的主要流程及流程图。
流程如下:
- 初始化环境TaggedPointer环境,同时新建两个表:
gdb_objc_realized_classes用来存储读取完成的类的类名,allocatedClasses存储已经创建的类及元类,接下来作为类是否创建的逻辑判断 - 读取类
read_class,如果是需要实现的新类,那么进行实现并重映射,并用新类的地址替换旧类的地址,然后把实现的类的类名存储到表gdb_objc_realized_classes中,同时顺带把这个类以及元类都保存到表allocatedClasses中做了关联绑定,方便后续逻辑处理 - 读取类的方法@selector,调用
sel_registerNameNoLock,把方法名存储到表namedSelectors中 - 读取类的protocol协议,调用
readProtocol,把协议对象protocol_t的mangledName存储到表protocol_map中。 - 最后读取类的分类category,category对应两个逻辑分别调用
remethodizeClass,这两个逻辑分别是:实例方法/属性/协议添加到当前类,而类方法/属性/协议添加给当前类对应的元类,因为类方法本身就是是存储在元类中的。具体操作就是先获取到所有分类及中的数据,添加到新的数组中,然后直接调用rw->methods.attachLists/rw->properties.attachLists/rw->protocols.attachLists,利用list_array_tt中的attachLists方法,把这些分类,协议,属性都添加到类和元类的rw数据中
流程图如下:
三、load_images流程分析
接下来我们分析load_images底层的逻辑流程,点击load_images进入
void
load_images(const char *path __unused, const struct mach_header *mh)
{
// Return without taking locks if there are no +load methods here.
if (!hasLoadMethods((const headerType *)mh)) return;
recursive_mutex_locker_t lock(loadMethodLock);
// Discover load methods
{
mutex_locker_t lock2(runtimeLock);
prepare_load_methods((const headerType *)mh);
}
// Call +load methods (without runtimeLock - re-entrant)
call_load_methods();
}
找到关键代码
- prepare_load_methods
- call_load_methods
开始分析
1、prepare_load_methods底层实现
贴上prepare_load_methods源码
void prepare_load_methods(const headerType *mhdr)
{
size_t count, i;
runtimeLock.assertLocked();
//先递归调度 类和父类
classref_t *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
//再调度分类
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
Class cls = remapClass(cat->cls);
if (!cls) continue; // category for ignored weak-linked class
realizeClass(cls);
assert(cls->ISA()->isRealized());
add_category_to_loadable_list(cat);
}
}
进入schedule_class_load,这个函数底层如下
static void schedule_class_load(Class cls)
{
......
schedule_class_load(cls->superclass);
add_class_to_loadable_list(cls);
......
}
这里面添加的方法add_class_to_loadable_list的底层实现如下
void add_class_to_loadable_list(Class cls)
{
IMP method;
loadMethodLock.assertLocked();
取到load方法
method = cls->getLoadMethod();
......
loadable_classes[loadable_classes_used].cls = cls;
loadable_classes[loadable_classes_used].method = method;
loadable_classes_used++;
}
我们发现这个添加过程实际上就是把loadable_class类型的结构体,存储到表待调度load的这张表loadable_classes中,而存储的结构体loadable_class类型包含类名cls以及该类的load方法IMP。
struct loadable_class {
Class cls; // may be nil
IMP method;
};
cls->getLoadMethod()方法得到的就是该类的Load方法
IMP
objc_class::getLoadMethod()
{
......
mlist = ISA()->data()->ro->baseMethods();
if (mlist) {
for (const auto& meth : *mlist) {
const char *name = sel_cname(meth.name);
if (0 == strcmp(name, "load")) {
return meth.imp;
}
}
}
return nil;
}
schedule_class_load底层实现原理是:获取父类,然后继续递归调用schedule_class_load,然后把这些类按父类的父类->父类->子类这个顺序把类和类的load方法添加到loadable_classes表中。这也是为什么类的+(load)方法执行顺序是从父类到子类的。
在调用schedule_class_load添加完成类之后,又继续处理分类,分类内部调用_category_getLoadMethod拿到分类中重写的load方法,然后也调用add_category_to_loadable_list把分类cat和分类的load方法添加到表loadable_categories中。
所以总结prepare_load_methods准备load方法的逻辑就是:
- 先处理类:递归按照先父类再子类的顺序,把类和类的load方法整合成一个结构体对象
loadable_class,然后把这个结构体对象存到表loadable_classes中。 - 处理完成类之后,再开始处理分类:获取分类的load方法,把分类和分类的load方法整合成一个结构体对象
loadable_category然后存储到表loadable_categories中。
到这里,load方法准备工作完毕。
2、call_load_methods底层实现
接下来进入重点,load方法的调用部分
void call_load_methods(void)
{
static bool loading = NO;
bool more_categories;
loadMethodLock.assertLocked();
// Re-entrant calls do nothing; the outermost call will finish the job.
if (loading) return;
loading = YES;
void *pool = objc_autoreleasePoolPush();
do {
// 1. Repeatedly call class +loads until there aren't any more
while (loadable_classes_used > 0) {
call_class_loads();
}
// 2. Call category +loads ONCE
more_categories = call_category_loads();
// 3. Run more +loads if there are classes OR more untried categories
} while (loadable_classes_used > 0 || more_categories);
objc_autoreleasePoolPop(pool);
loading = NO;
}
先观察这个函数实现部分,发现这个do—while循环被包含在objc_autoreleasePoolPush()和objc_autoreleasePoolPop中,苹果使用了autoreleasePool是为了节省内存开销。
然后我们继续来看循环体部分:
do {
//1、while循环调用call_class_loads()方法
while (loadable_classes_used > 0) {
call_class_loads();
}
//2、调用call_category_loads()并返回一个bool布尔值并赋值给more_categories
more_categories = call_category_loads();
} while (loadable_classes_used > 0 || more_categories);
接下来我们继续分析call_class_loads和call_category_loads底层实现。
先来看看调用类的load函数call_class_loads:
static void call_class_loads(void)
{
int i;
// Detach current loadable list.
struct loadable_class *classes = loadable_classes;
int used = loadable_classes_used;
loadable_classes = nil;
loadable_classes_allocated = 0;
loadable_classes_used = 0;
// Call all +loads for the detached list.
for (i = 0; i < used; i++) {
Class cls = classes[i].cls;
load_method_t load_method = (load_method_t)classes[i].method;
if (!cls) continue;
if (PrintLoading) {
_objc_inform("LOAD: +[%s load]\n", cls->nameForLogging());
}
(*load_method)(cls, SEL_load);
}
// Destroy the detached list.
if (classes) free(classes);
}
简化源码如下
static void call_class_loads(void)
{
......
for (i = 0; i < loadable_classes_used; i++) {
Class cls = loadable_classes[i].cls;
load_method_t load_method = (load_method_t) loadable_classes[i].method;
......
(*load_method)(cls, SEL_load);
}
......
}
这个过程其实就是从之前存储好的表loadable_classes中取出Class和对应load方法的load_method_t对象,直接调用。
然后看看调用分类的load函数call_category_loads
static bool call_category_loads(void)
{
int i, shift;
bool new_categories_added = NO;
// Detach current loadable list.
struct loadable_category *cats = loadable_categories;
int used = loadable_categories_used;
int allocated = loadable_categories_allocated;
loadable_categories = nil;
loadable_categories_allocated = 0;
loadable_categories_used = 0;
// Call all +loads for the detached list.
for (i = 0; i < used; i++) {
Category cat = cats[i].cat;
load_method_t load_method = (load_method_t)cats[i].method;
Class cls;
if (!cat) continue;
cls = _category_getClass(cat);
if (cls && cls->isLoadable()) {
......
(*load_method)(cls, SEL_load);
cats[i].cat = nil;
}
}
......
return new_categories_added;
}
这个过程和类的逻辑基本一致,也是就是从之前存储好的表loadable_categories中取出分类Category和对应load方法的load_method_t对象,然后通过_category_getClass获取到分类对应的类,然后用类直接调用load方法。
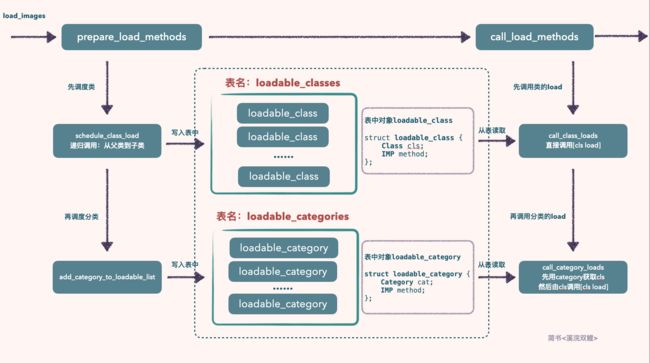
到此为止,load_images主要流程也已经分析完毕。load_images主要做了下面这些步骤:
第一步.准备load方法:prepare_load_methods
以先处理类,后处理分类 以及 先处理父类,后处理子类的顺序存储到待调度的表中。
类的处理逻辑:把类对象
Class和类对应的load方法的IMP整合成一个loadable_class类型的结构体对象存储在表loadable_classes中。分类的处理逻辑:把分类对象
Category和对应的load方法IMP整合成一个loadable_category类型的结构体对象存储在表loadable_categories中。
第二步.调用load方法:call_load_methods
以先调用类
Class的load,后处理分类Category,通过分类找到对应的类,然后由类调用load方法的顺序进行处理这个调用处理的顺序是根据准备方法
prepare_load_methods中准备好的两张表loadable_classes和loadable_categories的顺序而来的。调用完就从表中移除,全部调用完结束循环。
下面是我对load_images方法实现逻辑的的流程图:
四、面试题答案(仅供参考~)
1、应用程序启动 在main函数之前都具体做了哪些内容?
程序启动时,系统XNU执行程序的可执行二进制文件,从内核态切换到用户态,根据路径找到并运行动态链接器dyld,并把控制权交给dyld,然后启动dyld进行程序环境初始化,然后读取可执行文件Mach-O,开始根据头文件内容读取动态库并初始化主程序,初始化主程序后,就开始链接读取完成的动态库到主程序可执行文件中,然后初始化动态库。在初始化其他动态库之前,会最先初始化系统库libsystem,运行Runtime。系统库libsystem初始化完成后,就会初始化其他动态库,然后由Runtime调用
map_images来读取类、方法、协议以及分类并存储到对应的表中(注意:分类并不是直接存,而是通过attachLists方法把分类的数据添加到类里面),然后Runtime会继续调用load_images调用所有类的load方法以及分类的load方法,这些都做完之后,通过dyld提供的回调_dyld_objc_notify_register,告诉dyld加载完毕,然后dyld就开始找主程序的入口main函数,最后进入程序的main函数。
2、load在什么时候调用?子类、父类以及分类load的调用顺序?
load方法调用是在应用程序main函数之前,应用启动时dyld处理完image镜像文件,通过回调传给runtime,交由runtime在load_images方法中调用的。
load方法调用顺序为:先处理类,后处理分类;处理类的顺序是先父类,后子类在调用类的
load方法时,做了递归处理,会先调用父类的load,然后再调用子类的load,所有类的load方法调用完成后,才会开始处理所有类的分类,分类的处理顺序取决于Mach-O头文件,和类的顺序没有直接关系。先后顺序即:父类->子类->所有类的分类验证方式:实现子类和父类,重写load方法,在其中进行NSLog打印便可以看出,这里我就不验证了。