Pytorch03:自定义网络层,以Dropout层为例
写在前面
除了使用自己的数据集(详见Pytorch02:使用自己的数据构建可供网络运行的数据集进行训练),定义自己需要的网络层也是很常见的情景,尤其是在实现较为复杂的网络结构,或者需要在基本网络上进行修改的时候。本文将介绍如何在Pytorch中自定义一个Dropout层,并在其基础上进行修改,来作为对自定义网络层方式的简单介绍。
一、要实现什么东西
首先,我们要了解,如果实现了一个自定义的网络层,应该在哪里使用它。在VGG-16(详见Pytorch01:使用标准数据集CIFAR-10搭建VGG16网络)中,均是使用torch.nn的网络层对象来构建网络的,其中,全连接层的部分如下:
self.classifier = nn.Sequential(
# 14, 512=>4096
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(), # 标准Dropout层
# 15, 4096=>4096
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(), # 标准Dropout层
# SelfDropout(), # 自定义Dropout层
# 16, 4096=>output_sizes
nn.Linear(4096, num_classes),
)
我们如果要实现一个自定义的Dropout网络层,目标就是用一个自定义的SelfDropout()对象替换掉原来的nn.Dropout()对象。
二、实现自定义网络层类的定义
主要是参考了torch.nn.Dropout()的源码。首先是要继承nn.Module类,这个和定义一个网络类似。然后实现它的forward()函数。
import torch.nn.functional as F
# 自定义一个dropout层
class SelfDropout(nn.Module):
def __init__(self, p: float = 0.5, inplace: bool = False) -> None:
super(SelfDropout, self).__init__()
if p < 0 or p > 1:
raise ValueError("dropout probability has to be between 0 and 1, "
"but got {}".format(p))
self.p = p
self.inplace = inplace
# 下面是自定义的内容
# nn.Parameter将变量变成模型的参数,不仅可以参加反向传播的参数更新,还能够在model.cuda()时一同被送到GPU中
self.dropout_mask = nn.Parameter(torch.zeros(4096))
# 能够打印用户定制化的额外信息,为重载函数
def extra_repr(self) -> str:
return 'p={}, inplace={}'.format(self.p, self.inplace)
# 前向传播,为重载函数
def forward(self, input: Tensor) -> Tensor:
# self.training是通过self.train()和self.eval()控制的
# self.train: self.training=True
# self.train: self.training=False
if self.training:
return F.dropout(input, self.p, True, self.inplace)
else:
# input.size()=[batch_size, 4096], self.dropout_mask.size()=[4096]
# 乘法结果为全0,size=[batch_size, 4096],为对应位相乘
return input * self.dropout_mask
- 在
torch.nn.functional中封装了标准dropout前向传播和反向传播的过程,这里只是简单地调用。 - 在
forward函数中用self.training来区分训练阶段和测试阶段。self.training的值是由model.train()和model.eval()修改的。 - 由于dropout层没有参数,所以原来的
torch.nn.Dropout()实现中是没有参数的。但在自定义的网络层中,加入了参数self.dropout_mask。该参数需要是Tensor类型,且需要用nn.Parameter进行封装。封装后,该变量能够随网络参与反向传播的自动梯度更新,且在model = model.cuda()时能够随其他的网络参数一起送入GPU中。注意,如果不封装的话,在使用GPU时是不能和神经网络的输入、输出进行运算的,因为该变量只能被CPU使用。参见博客PyTorch里面的torch.nn.Parameter()和博客4.4 自定义层。 - 参数的访问方式和初始化方法可以参考博客Pytorch—模型参数与自定义网络层。
extra_repr函数用来打印额外的关于该网络层的信息,可由用户自定义。- 在原来的Dropout层中,测试阶段的前向传播是不会Dropout任何神经元的,仅在训练过程中Dropout。这是为了让神经元在训练阶段学习其他神经元的功能,从而提高网络的泛化能力。而该自定义的Dropout层主要是修改了在测试阶段的前向传播过程,目的是在测试阶段也进行Dropout,但不是随机Dropout而是固定地Dropout部分神经元。通过参数
self.dropout_mask和input相乘的方式,就可以来固定Dropout掉某些神经元,达到在全连接层上进行特征选择的目的。 self.dropout_mask在本文中简单设置为全0,但可以令某些位为1,这样就可以选择特征向量上对应的特征。
三、VGG-16网络结构的修改
直接将原来的nn.Dropout()对象换成SelfDropout()对象即可。
self.classifier = nn.Sequential(
# 14, 512=>4096
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(), # 标准Dropout层
# 15, 4096=>4096
nn.Linear(4096, 4096),
nn.ReLU(True),
# nn.Dropout(), # 标准Dropout层
SelfDropout(), # 自定义Dropout层
# 16, 4096=>output_sizes
nn.Linear(4096, num_classes),
)
四、关于自定义参数更新的问题
如果是如上面代码中定义那样,自定义的参数只在测试阶段使用,则该参数是不会被更新的。但如果自定义的参数在训练过程中被使用的话,则需要控制其是否更新的方法。
- 在训练过程中被梯度更新。需要设置
self.dropout_mask.requires_grad = True,此时,虽然在初始化的时候将该参数设置为0,但是随着网络的训练,它可以通过梯度更新自身的值,这样值就随迭代过程发生了改变。实际上,如果是参数要被更新的话,无论其初始化是为常数还是随机值,都只会影响其训练过程,最后网络还是会让它趋向一个最优解的。代码和其输出结果如下:
class SelfDropout(nn.Module):
def __init__(self, p: float = 0.5, inplace: bool = False) -> None:
super(SelfDropout, self).__init__()
if p < 0 or p > 1:
raise ValueError("dropout probability has to be between 0 and 1, "
"but got {}".format(p))
self.p = p
self.inplace = inplace
# 下面是自定义的内容
# nn.Parameter将变量变成模型的参数,不仅可以参加反向传播的参数更新,还能够在model.cuda()时一同被送到GPU中
self.dropout_mask = nn.Parameter(torch.zeros(4096))
self.dropout_mask.requires_grad = True
# 能够打印用户定制化的额外信息,为重载函数
def extra_repr(self) -> str:
return 'p={}, inplace={}'.format(self.p, self.inplace)
def forward(self, input: Tensor) -> Tensor:
if self.training:
print(self.dropout_mask)
return input * self.dropout_mask
else:
return input * self.dropout_mask
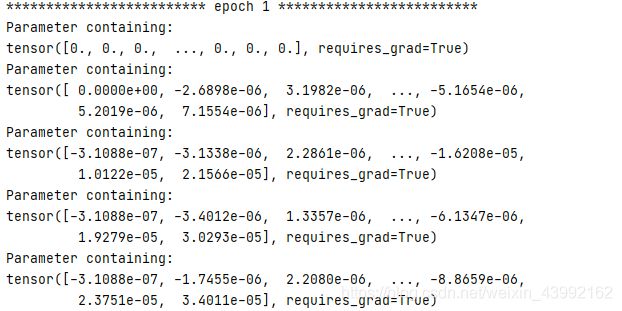
- 在训练过程中固定该参数。如果是要固定该参数,不让它用梯度更新,则设置
self.dropout_mask.requires_grad = False,这样该参数就不会随梯度更新了。打印的结果如下:
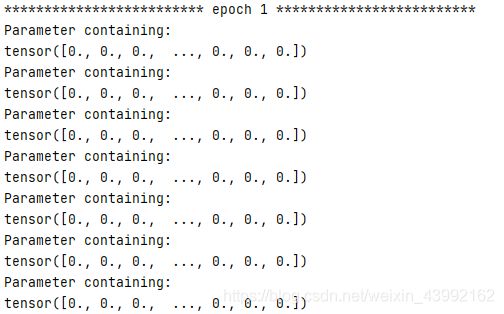
注意,无论是在测试阶段还是训练阶段被使用,无论是不是设置为更新参数,在使用nn.Parameter封装之后,该参数就自动拥有了梯度值,只不过是是否使用其梯度来更新它本身的值的区别而已。