基础正则表达式
LANG=C A-Z a-z连续
LANG=zh_CN a A b B...
如果在语系LANG=zh_CN中[A-Z]会将b c选出来
| 特殊符合 | 代表意义 |
|---|---|
| [:alnum:] | 代表英文大小写字符与数字 |
| [:alpha:] | 代表英文大小写字符 |
| [:blank:] | 代表空格键和tab键 |
| [:cntrl:] | 代表键盘上面的控制按键,即包括CR,LF,Tab, Del等 |
| [:digit:] | 代表数字 |
| [:graph:] | 除了空格和tab外的其他所有按键 |
| [:lower:] | 小写字符 |
| [:print:] | 任何可以被打印出来的字符 |
| [:punct:] | 代表标点字符,“ ‘ ? !;:# $ |
| [:upper:] | 大写字符 |
| [:space:] | 任何会产生空白的字符,空格键 tab CR等 |
| [:xdigit:] | 代表十六进制的数字类型,0-9,A-F, a-F |
// 显示行号,并显示查找到的行前面2行,后面3行
# grep -n -A3 -B2 --color=auto '搜寻字符串’ filename
// 不要空白行 -v是反向选择
# grep -v '^$' filename
// 非g开头的xoo
# grep -n '[^g]oo' filename
// 以小写字母开头
# grep -n '^[a-z]' filename
// 小数点代表一个任意字符
# grep -n 'g..d' filename
// 重复0个或者多个前面的RE(Regular Expression)字符,可以是控制符或者一个o以上的字符
# grep -n 'o*' filename
// g......g
# grep -n 'g.*g' filename
// 限定连续RE字符范围{},在g与g之间有2个到3个存在的o
# grep -n 'go\{2,3\}g' filename
# ls -al | wc -l
wc - print newline, word, byte counts for each file
sed
# sed [-nefri] [动作】
参数:
-n : 安静模式,经过sed特殊处理的那一行才会被列出来
-e : 直接在命令行模式进行sed的动作编辑
-f : 直接将sed的动作写在一个文件内,-f filename则可以执行filename内的sed动作
# scriptfile 一行用;分隔
sed [options] -f scriptfile files
-r : sed的动作支持的是扩展型正则表达式的语法
-i : 直接修改读取的文件内容,而不是由屏幕输出
动作说明: [n1,[n2]] function
a\ 在当前行下面插入文本。
i\ 在当前行上面插入文本。
c\ 把选定的行改为新的文本。
d 删除,删除选择的行。
D 删除模板块的第一行。
s 替换指定字符
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区。
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l 列表不能打印字符的清单。
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p 打印模板块的行。 P(大写) 打印模板块的第一行。
q 退出Sed。
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
r file 从file中读行。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
! 表示后面的命令对所有没有被选定的行发生作用。
= 打印当前行号码。
# 把注释扩展到下一个换行符以前。
g 表示行内全面替换。
p 表示打印行。
w 表示把行写入一个文件。
x 表示互换模板块中的文本和缓冲区中的文本。
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
\1 子串匹配标记
& 已匹配字符串标记
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
* 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\< 匹配单词的开始,如:/\ 匹配单词的结束,如/love\
>/匹配包含以love结尾的单词的行。
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。
s : 替换,可以搭配正则表达式 s/old/new/Ng 从第N处匹配处开始替换
默认定界符是/。也可以用其他任意
#删除最后一行
sed '$d' file
# 删除文件中所有开头为test的行
sed '/^test/'d file
# nl /etc/passwd | sed '2,5d'
nl : 将文件内容打印到stdout
// 在第二行后面新增2行
# nl /etc/passd | sed '2a Drinking tea ....'
> drink bear ?'
# cat /etc/man.config | grep 'MAN' | sed 's/#.*$//g' | sed '/^$/d'
// sed后面如果要接超过2个以上的动作,每个动作前面要加-e
# sed -e '4d' -e '6c no six line' filename
// 查看文件内容中特殊字符
# sed -n l filename
# ??-i.bak是啥东西
# sed -i.bak "s/gt 600/gt 900/g" filename
// 所有在test和check所确定的范围内的行都将被打印
sed -n '/test/,/check/p' file
// 打印从第5行开始到第一个包括test开始的行之间的所有行
sed -n '5,/^test/p' file
// 对于模板test和west之间的行,每行的末尾用字符串aaa bbb替换
sed '/test/,/west/s/$/aaa bbb/' file
// 从文件读入: r命令
// file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面
sed '/test/r file' filename
// 写入文件 w
sed -n '/test/w file' example
// 追加(行下)a\
sed '/^test/a\this is a test line' file
// 在第2行之后(行下)插入
sed -i '2a\this is a test line' file
// 插入(行上):i\
sed '/^test/i\this is a test line' file
sed -i '5i\this is a test line' test.conf
// 下一个:n命令
// 如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续
sed '/test/{ n; s/aa/bb/;}' file
// 变形:y命令
// 把1~10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令:
sed '1,10y/abcde/ABCDE/' file
// 打印完第10行后,退出
sed ‘10q' file
sed -n 'p;n' test.txt #奇数行
sed -n 'n;p' test.txt #偶数行
sed -n '1~2p' test.txt #奇数行
sed -n '2~2p' test.txt #偶数行
打印匹配字符串的下一行
grep -A 1 SCC URFILE
sed -n '/SCC/{n;p}' URFILE
awk '/SCC/{getline; print}' URFILE
//保持和获取h和G
在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。
sed -e '/test/h' -e '$G' file
互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换:
sed -e '/test/h' -e '/check/x' file
sed不支持\d这种选项
sed后'{print }'。里面()"需要转义
sed表达式可以使用单引号来引用,但是如果表达式内部包含变量字符串,就需要使用双引号
也可以使用new_db_name=${new_db_name/$replace_string/$replace_with}
如果替换字符串中含有\,替换的时候回出现sed: -e expression #1, char 6: unterminated `s' command](http://blog.csdn.net/wengyupeng/article/details/51840394)
web=$(curl | sed 's/\//g')
扩展正则表达式
egrep === grep -E
| RE字符 | 意义和范例 | ||
|---|---|---|---|
| + | 重复一个或一个以上的前一个RE字符 egrep -n 'go+d' filename god good goo...d |
||
| ? | 0个或者1个的前一个RE字符 egrep -n 'go?d' filename gd god |
||
| egrep -nr 'gd |
goood' filename | ||
| () | 找出组字符串 egrep -n 'g(lad |
oo)d filename glad good |
|
| ()+ | 多重组的判别 egrep 'A(xyz)+C' filename AxyzC AxyzxyzC Axyzxyz....C |
那个!在正则表达式当中不是特殊字符
printf '打印格式‘ 实际内容
参数:
\a : 警告声音输出
\b : 退格键
\f :清除屏幕
\n : 输出新的一行
\r : enter
\t : 水平tab
\v : 垂直tab
\xNN : NN为两位数的数字,可以转换数字成字符
%ns : n个字符串
%ni :
%N.nf
awk
# awk '条件类型1{动作1} 条件类型2{动作2} ....' filename
$0 整行
$1 第一列
...
# last -n 5 | awk '{print $1 "\t lines:" NR "\t columes: " NF}'
# cat /etc/passwd | awk '{FS=":"} $3<10 {print $1 "\t " $3}'
# cat /etc/passwd | awk '{if(NR==1) printf "%10s",$0} NR>=2{}'
搜索/etc/passwd有root关键字的所有行
#awk -F: '/root/' /etc/passwdroot:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
# awk -F: '/root/{print $7}' /etc/passwd /bin/bash
| 变量名称 | 代表意义 |
|---|---|
| NF | 每一行拥有的字段总数 |
| NR | 目前awk所处理的第几行数据 |
| FS | 目前的分隔符,默认是空格键 |
所有awk的动作,即在{}内的动作,如果有需要多个命令辅助时,可以利用分号或者enter来隔开每个命令
awk中变量不需要加$
head tail last
# head -n 3 filename
# tail -n 2 filename
# last
diff
# diff [-bBi] from-file to-file
from-file和to-file可能是-
-b : 忽略一行当中仅有多个空白的区别
-B :忽略空白行
-i : 忽略大小写
cmp
# cmp [-s] file1 file2
-s :列出所有不同的点
patch
# patch -pN < patch_file
# patch -R -pN < patch_file
cut
其语法格式为:
cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file]
使用说明
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定 File 参数,cut 命令将读取标准输入。必须指定 -b、-c 或 -f 标志之一。
主要参数
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除。
pr 文件打印准备
tr
tr [ -c | -cds | -cs | -C | -Cds | -Cs | -ds | -s ] [ -A ] String1 String2
tr { -cd | -cs | -Cd | -Cs | -d | -s } [ -A ] String1
若要将大括号转换为小括号,请输入:tr '{}' '()' < textfile > newfile
这便将每个 {转换成 (,并将每个 }转换成 )。所有其它的字符都保持不变。
若要将大括号转换成方括号,请输入:tr '{}' '\[]' < textfile > newfile
这便将每个 {转换成 [,并将每个 }转换成 ]。左方括号必须与一个 "\"转义字符一起输入。
若要将小写字符转换成大写,请输入:tr 'a-z' 'A-Z' < textfile > newfile
若要创建一个文件中的单词列表,请输入:
tr -cs '[:lower:][:upper:]' '[\n*]' < textfile > newfile
这便将每一序列的字符(除大、小写字母外)都转换成单个换行符。*
(星号)可以使 tr 命令重复换行符足够多次以使第二个字符串与第一个字符串一样长。
若要从某个文件中删除所有空字符,请输入:tr -d '\0' < textfile > newfile
若要用单独的换行替换每一序列的一个或多个换行,请输入:
tr -s '\n' < textfile > newfile
或
tr -s '\012' < textfile > newfile
若要以“?”(问号)替换每个非打印字符(有效控制字符除外),请输入:tr -c '[:print:][:cntrl:]' '[?*]' < textfile > newfile
这便对不同语言环境中创建的文件进行扫描,以查找当前语言环境下不能打印的字符。
要以单个“#”字符替换 字符类中的每个字符序列,请输入:tr -s '[:space:]' '[#*]'
http://www.cnblogs.com/wangkangluo1/archive/2012/05/31/2528059.html
bash 和sed
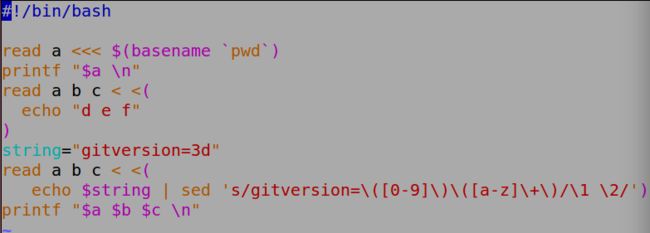
sed -r 后面就可以不专一了
如果不接-r,连+和(都需要专一
<<<和< <(这个只有在bash的时候才能用。所以不能用sh去执行。
grep
- OR
grep 'Tech\|Sales' employee.txt
grep -E 'pattern1|pattern2' filename
egrep 'pattern1|pattern2' filename
grep -e pattern1 -e pattern2 filename
- And
grep -E 'pattern1.*pattern2' filename
grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
grep -E 'pattern1' filename | grep -E 'pattern2'
- NOT
grep -v 'pattern1' filename