超像素论文(三)——AINet: Association Implantation for Superpixel Segmentation
一、 传送门
论文链接:https://arxiv.org/abs/2101.10696
二、 简介
超像素的通常策略是将图片分成规则方格,然后估计每个像素和它相邻方格的关系,最后得到超像素分割的结果。因此,如何准确的估计像素和相邻方格的关系至关重要。
在Superpixel Segmentation with Fully Convolutional Networks(CVPR2020)中,利用U-net得到一个 h × w × 9 h\times w \times 9 h×w×9的矩阵来作为像素和周围九个超像素的关系,也可以视作属于该超像素的概率。
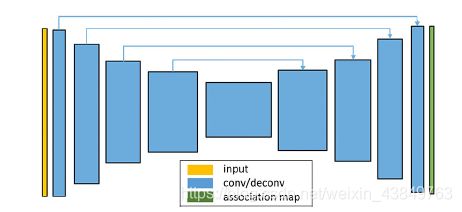
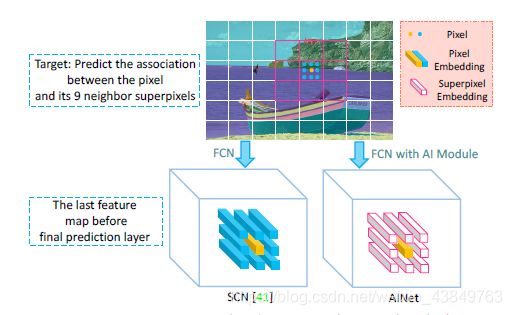
但是该篇论文中认为SpixelFCN中的U-net结构中存在skip-connect操作,对于最后结果是不利的,因为这种操作引入了low-level的pixel-pixel关系。对此,这篇文章提出了Association Implantation (AI) Module,如下图,AI模块直接对像素和超像素的关系进行预测,而不会像FCN一样预测pixel-pixel的关系。
除此之外,这篇文章还提出了新的损失函数,帮助超像素更加贴合图像的边缘。
三、方法
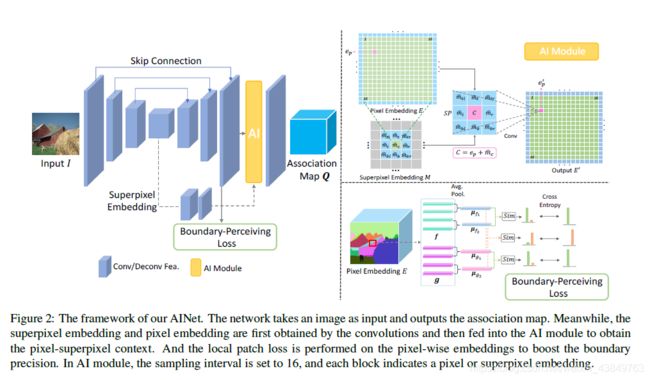
(一)Association Implantation Module
这个模块还是很好理解的,将unet中最中间的部分视作superpixel的编码,unet最后一层输出的作为图像每个像素的feature,将这两部分送去AI模块中,直接计算像素和每个超像素之间的关系,得到最后的pixel-superpixel association,即SpixelFCN中的Q。
为什么最中间的部分可以视作超像素的编码呢?
- 个人理解,unet作为一个encoder-decoder结构,随着在encoder阶段感受野不断增加,我们获得了更deep的特征,矩阵也不断被压缩。然而超像素本质也可以看做是一个特殊矩阵——图像的矩阵压缩,所以encoder得到的结果在和超像素特征是等价的。
AI将每个像素点的和对应的周围超像素结合起来成一个 3 × 3 × D 3\times3\times D 3×3×D的矩阵:
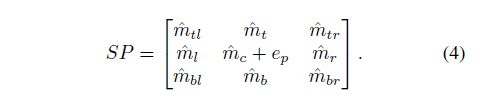
其中 e p ∈ R 1 × 1 × D e_p \in R^{1 \times 1 \times D} ep∈R1×1×D,是一个像素点的特征,D是通道数。 M ^ ∈ R 1 × 1 × D \hat{M} \in R^{1 \times 1 \times D} M^∈R1×1×D是超像素的特征,这个矩阵会被一个 3 × 3 3 \times 3 3×3的卷积变成 1 × 1 × 9 1 \times 1 \times 9 1×1×9作为像素和周围超像素的关联。下面这个公式就是一个普通的卷积公式。
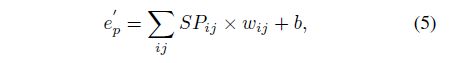
(二)Boundary-Perceiving Loss
之前的超像素的工作中,损失函数主要和语义标签以及位置信息重建相关,但是忽略了一个重要的标准:让超像素贴合物体的边缘。
这个损失函数的过程比较复杂,我们展开来讲,主要目的是让边缘附近的像素,属于同一语义标签的像素更接近,不属于的差异更大。
对于decoder部分最后生成的像素级特征 E ∈ R H × W × D E \in R^{H\times W\times D} E∈RH×W×D,我们在位于GT边缘附近的地方画一个 k × k k \times k k×k的方框,我们将方框内的像素按照语义标签的不同分成两个部分 f 和 g { f 1 , f 2 , . . . , f m , g 1 , g 2 , . . . g n } ; m + n = k 2 \{f_1, f_2, ..., f_m, g_1, g_2, ... g_n\};m+n=k^2 { f1,f2,...,fm,g1,g2,...gn};m+n=k2,然后按照平均数,将f和g在各自分为两部分 f 1 , f 2 , g 1 , g 2 f^1, f^2, g^1, g^2 f1,f2,g1,g2,然后 Boundary-Perceiving Loss 损失函数如下。

损失函数有两部分,第一部分是让同一类的像素更靠近平均值,也就是更加接近彼此;第二部分反之,让不同类的像素差异更大。整体使用了交叉熵函数的思想。实验中,我们将 k k k设置为5。
(三)Augmentation via Patch Jitter
作者对该网络的训练设计了一种Data Aug的方式,主要由以下几种组成:
- Patch Shuffle
- Random Shift
- 将一个随机的Patch用random信息代替,并在语义标签上设置为一个新的类

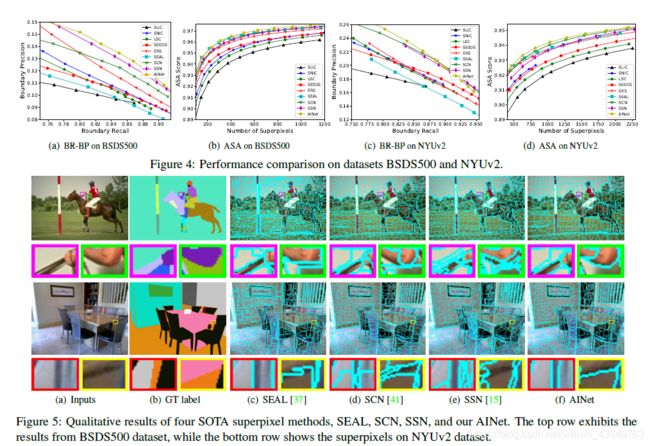
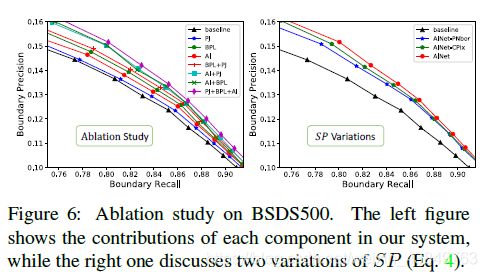
四、实验
具体的setup可以直接参考论文,这里放一下实验结果