SIGIR2021 | 超越I2I和向量内积,淘宝新一代召回范式:PDN模型

摘要
一般来说业务的推荐系统的常用的召回算法有两个范式,相似度索引范式(如I2I),EBR范式(如DeepMatch)。I2I范式缺点在于对共现少的pair难以泛化,难以建模U2I部分,从而模型缺乏准确和个性化。EBR范式虽建模了U2I部分,将用户的兴趣整合成了一个向量。但却无法建模用户每一个行为和打分item之间的关系(类似于Target Attention),从而召回即缺乏多样性。为了融合两者的优点,尽可能的减少两者的缺点,我们提出了一种新的范式Path based Deep Network(PDN)。PDN模型用TriggerNet建模U2I的部分,SimNet建模I2I的部分,进而端到端的建模U2I2I。目前PDN模型已经在手淘首页内容信息流场景上全量,成为线上最主要的召回源,带来了20%左右的点击个数、GMV、多样性的提升。同时PDN也被SIGIR2021高分录取。
背景
推荐技术在淘宝中的应用是十分重要和普遍的,目的在于建立一个桥梁使得用户可以直达他们感兴趣的商品以提高用户的体验及效益转换。一般的推荐系统主要包含召回,粗排,精排和重排四大环节。由于召回环节处在整条推荐链路的最底层,决定了推荐效果的瓶颈及上限,因此本次工作主要针对有好货场景的该环节进行优化。召回环节的主要任务是高效地从整个商品池中筛选出一小部分(一般来说是千~十万级)用户可能感兴趣的商品供其他环节进行筛选和排序。工业界的召回链路大致包含两类算法:相关索引召回范式,向量化召回范式(Embedding Based Retrieval, EBR)。
目前工业界,相关索引召回以Item2Item范式为主。具体做法是:Step1、离线阶段,基于一些商品相似度衡量指标(如皮尔逊相关系数)去构建倒排索引表;Step2、服务阶段,利用用户的历史行为序列直接查表进行检索。
Item2Item范式的优势在于:
1、可以保证用户兴趣的相关性;
2、行为丰富的用户召回也是多样的;
3、可以捕捉用户的实时兴趣。
但是存在以下四点问题:
1、往往I2I的索引是基于一种共现的统计,可能出现冷门商品排不上,新品排不了的问题;
2、如何即考虑I2I的共现信息,又考虑Item两端的Side Info;
3、如何将这种索引的建立和多样的业务目标关联;
4、如何考虑多个Trigger指向相同的一个Item的联合概率。
向量化召回模型( EBR)可以利用Side Info,也试图去建模用户多个行为的联合概率,因此近年受到更多的关注。简单来说,该算法分别得到用户表示和商品表示后,在服务的时候利用近邻搜索实现召回。当然,这类算法也存在不足,主要有两点,一个是这类算法仅用一个或若干个(类似于MIND)向量对用户进行表示,无法像i2i那样,逐商品细粒度的表示用户的多维兴趣;另一个是由于商品端和用户端是并行架构,难以引入目标商品与交互过商品的共现信息。
总体来说,由于受到现有召回模型框架的约束,双塔模型采用了用户信息和商品Profile信息,却无法显式地利用商品共现信息。I2I索引主要利用采用了商品共现信息,但是忽略了用户和商品Profile信息,且无法考虑行为序列对目标商品的综合影响。同时,由于相似度计算方法有所不同,线上往往有多种I2I索引同时工作,我们希望找到一种方法能统一这种I2I相似度,并且尽可能的解决上述提到的四点问题。
引子
如图1所示,我们将推荐问题归纳为基于二度图的链式预测问题:
![]()
其中,N(u)表示用户交互过的商品集合。现有的大多数工作,包括i2i的协同过滤方法和双塔模型都能看作上述公式的特例。例如,基于回归的商品协同滤波方法可以被定义为:
![]()
其中,定义为预测用户对交互商品感兴趣程度的函数,![]() 表示交互商品与目标商品的相关性程度。因此,该方法可以看作对n条二跳路径的求和,每条路径的权重为
表示交互商品与目标商品的相关性程度。因此,该方法可以看作对n条二跳路径的求和,每条路径的权重为![]() 。此外基于向量召回的方法,例如MF,可以被定义为:
。此外基于向量召回的方法,例如MF,可以被定义为:
![]()
其中,qi、pu、pj分别表示目标商品,用户信息和交互商品的特征向量。MF可以看作是对二度图的n+1条路径进行求和,具体来说,qi、pu表示直接路径的权重,![]() 表示二跳路径的权重。同样的,MF的深度化版本YotubeDNN可以被定义为:
表示二跳路径的权重。同样的,MF的深度化版本YotubeDNN可以被定义为:
![]()
已有召回方法受到召回效率、模型结构的限制,难以使用到图中的所有信息。例如,I2I范式缺少了用户信息和商品信息,EBR范式没有显式地建模商品共现信息。因此,我们提出了一种新型框架path-based deep network (PDN),来合理使用所有信息以实现低时延的个性化用户多峰兴趣召回。

图1:将用户对目标商品的喜爱程度解耦成二度图
其中第一跳表示用户对交互商品的喜爱程度,第二跳表示交互商品与目标商品的相似程度。其中,zu表示用户u的用户信息(id,性别等),![]() 表示用户交互过的n个商品的商品信息(id,类目等),xi表示目标商品的商品信息,
表示用户交互过的n个商品的商品信息(id,类目等),xi表示目标商品的商品信息,![]() 表示用户对第k个交互商品的行为信息(停留时长,购买次数等),
表示用户对第k个交互商品的行为信息(停留时长,购买次数等),![]() 表示第k个交互商品和目标商品的相关性信息(共现次数等),边的粗细表示该条边的权重大小。
表示第k个交互商品和目标商品的相关性信息(共现次数等),边的粗细表示该条边的权重大小。
方法
为了保证召回的时候能结合个性化的用户细粒度多峰兴趣,我们基于如图1所示的二度图构建了新一代召回框架。该框架克服了之前框架无法使用所有信息的劣势,并且融入了i2i和双塔模型各自的优势实现统一的优化。
其中,图1包含n(历史行为序列长度)条二跳路径及1条直接路径(user&position bias)。二跳路径中的第一跳表示为用户对交互商品的感兴趣程度,第二跳表示为交互商品与目标商品的相似度,因此,与双塔模型不同的是,我们细粒度的独立建模了用户的多峰兴趣(每个交互商品建立一个兴趣表示路径),解决了单一向量难以表达多维兴趣的问题。直接路径表示了用户对目标商品的直观喜爱程度,例如女生可能对服饰更感兴趣,男生可能对电子产品更感兴趣。
具体来说,对于n条二跳路径,我们的框架
(1)基于用户信息,行为信息和交互商品信息,采用一个TriggerNet建模用户对每一个交互过商品的喜爱程度,最终得到一个变长的用户表示向量(维度为1×n),其中,第k个维度表示用户对第k个交互商品的喜爱程度;
(2)基于交互商品与目标商品的信息,相关性信息,采用Similarity Net建模交互商品与目标商品的相似度,最终得到一个变长的目标商品表示向量,其中,第k维表示第k个交互商品和目标商品的相似度。最后综合n+1条路径的权重,预测最后对目标商品的喜爱程度。

图2 PDN整体框架
▐ PDN整体概述
图2展示了我们所提出的召回框架PDN,主要包含Embedding Layer,Trigger Net (TrigNet), Similarity Net (SimNet), Direct & Bias Net 四个模块。PDN的前向过程可以概括为:
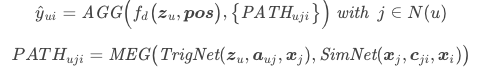
其中,fd表示直接路径权重的计算函数,PATHuij表示基于交互商品j的二跳路径权重,AGG表示融合n+1条路径权重,预测用户与目标商品相关性的评分函数。MEG表示融合每条二跳图权重的函数。
为了保证PDN满足召回环节的时延要求,我们将MEG定义为两个向量的点积或相加,fd定义为点积,因此,PDN可以被形式化的定义为:
![]()
下面,我们将详细介绍PDN中的各个模块。
▐ Embedding Layer
如图1所示,PDN主要使用四类特征,包括用户信息zu,商品信息x,行为信息![]() 以及商品相关性信息
以及商品相关性信息![]() 。PDN通过Embedding Layer将其转化为编码向量:
。PDN通过Embedding Layer将其转化为编码向量:
![]()
其中du, di, da, dc表示各类特征的维度。
▐ Trigger Net & Similarity Net
经过编码层后,PDN计算用户与目标商品间的每条二跳路径。对于第一跳,PDN利用TrigNet计算用户对每个交互商品的喜爱程度来补获用户的多峰兴趣。具体来说,给定用户u及他的交互商品j,计算方式如下所示:
![]()
其中
![]()
表示concatenation操作,tuj表示u对j的喜爱程度。当用户有n个交互商品时,Tu =[tu1,tu2,...,tun]可以被看作一个变长的用户表示。双塔模型往往以一个或多个定长的向量对用户进行表示,这被认为是捕获多兴趣的瓶颈,因为多兴趣信息被没有约束地混合到几个向量里,导致召回的不准确。相较于这类方法,Tu能更加细粒度地刻画用户的多峰兴趣,且更具可解释性,因为向量中的每一个维度显式传递了用户的感兴趣程度。
对于第二跳,SimNet基于商品信息和共现信息计算交互商品与目标商品的相似度:
![]()
其中,sji表示商品j和i的相似度,Si =[s1i,s2i,...,sni]可以被看作目标商品的变长向量表示。值得强调的是,SimNet显式的学习了商品间的相似度,因此,它可以实现线上的独立部署来代替原有的i2i策略。得到tuj和sji后,PDN计算得到每条二跳路径的相关性权重:
![]()
▐ Direct & Bias Net
位置偏差等选择性偏差被证明是推荐系统中的重要影响因素。例如,一个用户更倾向于去点击靠近顶部的商品,即使它不是最相关的商品。为了消除该类偏差,我们基于会导致选择性偏差的特征(位置信息等)训练了一个浅层塔。如图2所示,训练期间,Bias Net的输出ybias被添加到主模型的输出中。而在服务的时候,Bias Net被移除以保证无偏差的打分。Direct Net是类似的,主要建模user bias,我们将这两部独立出来主要是为了让TrigNet、SimNet学习出来的东西是和用户、position无关的。
▐ 损失函数
用户是否会点击该商品可以被看作是二分类任务。因此,PDN融合了n+1条路径的权重以及偏差得分得到用户与商品的相关性得分,并将其转化为点击概率:

由于softplus的引入,导致![]() ,因此,我们利用1-exp()将预测值投影到0到1之间。我们采取交叉熵损失训练该模型:
,因此,我们利用1-exp()将预测值投影到0到1之间。我们采取交叉熵损失训练该模型:
![]()
其中,yu,i为样本标签。
▐ 约束学习
为了确保模型收敛到更优的区域,我们精心设计了二跳路径上的约束形式。正如上面所提到的,在TrigNet和SimNet的最后一层,我们利用exp()代替其他激活函数来约束输出为正,即![]() 。
。
如果允许负权重的输出,导致PDN在更宽泛的参数空间中搜索局部最优值,这很容易导致过度拟合。由于我们在真实使用的时候,SimNet是用于生成Index,而TrigNet是用于Trigger Selection。这种过拟合的后果可不是效果差一些,而很可能导致学习出来的索引不可用。
我们通过允许相关权重为负的例子,来说明不带约束的学习可能出现的问题。
第一个例子,如图3左所示,某个用户点击过Ipad和华为P40pro,有一个负样本的Iphone出现,假设商品相似度都学对了,但Trigger这个部分过拟合了。这个负样本的出现可能是表示用户在这个类目上的兴趣已经消费完了,我们希望通过这个负例让模型捕捉到这个信息,因此是希望模型能学出两个较小的Trigger Weight。但如图中一正一负的情况,也是一种次优解,此时Loss比较小,优化器可能落入这个陷阱出不来。
第二个例子,如图3右所示。某个用户点击过耐克套装和特仑苏,有一个负样本的Iphone出现,假设Trigger Weight学对了,但相似度这个部分过拟合了。此时0.8*-0.8+0.5*0.5=-0.11,产生的Loss非常低。却学出了特仑苏和Iphone之间的相似度。如果约束为正时,优化器就会这两个相似度尽可能往0压,从而避免一正一负这种过拟合的情况。

图3 当二跳路径权重为负时的bad case
线上使用
▐ 基于路径的检索
为了满足召回环节的时延要求,如图4所示,我们构造了一种新的基于贪心策略的召回链路:基于路径的检索(path retrieval)。具体来说,我们将路径检索解耦为两部分:
(1)利用TrigNet检索出用户最感兴趣的top-m个交互商品;
(2)利用SimNet构建的商品相似度索引分别对top-m中的每个交互商品实现i2i检索。
对于TrigNet,我们将其部署为实时的线上服务用于对每个交互商品打分;对于SimNet,我们基于其所计算的商品相似度离线构造倒排索引表。线上召回环节的步骤可以总结如下:
索引生成:基于SimNet,我们为商品池中的每一个商品选取k个最相关的商品构建索引,并存储相关性得分sji。详细生成方法见4.2。
交互商品提取:当用户进入场景,我们使用TrigNet为用户所有交互过的商品进行打分tuj,并返回top-m个交互商品。
Top-K检索:我们基于top-m个交互商品查询SimNet构建的索引表。并基于如下公式对m×k个候选商品进行得分并返回最后召回结果。
![]()
此时不再需要Position Bias和User Bias。整体召回框架如图5所示。

图4 基于路径的检索(path retrieval)
▐ 索引生成
由于商品池很大,我们需要压缩相似度矩阵RN×N →RN×k,以保证离线的计算效率和存储资源。具体包含三个步骤。
步骤一,候选商品对枚举:我们主要基于两个策略生成候选pair对,一个是同一个Session中共现过的商品,另一个是基于商品的信息,例如同品牌/同店铺的商品。
步骤二,候选对排序:利用SimNet对每一个pair对进行打分。
步骤三,索引构建:对每个商品,基于simNet的得分按照某种规则进行排序截断,构造N×k的索引表。
由于SimNet的输入除了共现信息,还有两端的side info,我们可以解决新品召回的问题。具体的做法是,在步骤一的时候,多枚举出一些和新品在商品属性的角度很相似度商品对。

图5 整体召回框架
实验
▐ 离线验证
表1给出了I2I召回方法的离线验证,用的是线上曝光点击日志。离线召回方法为,利用用户3天内的所有行为作为Trigger,用不同的四种索引,每一个Trigger在索引中找TopN(3/8)个。
这种验证方法是所用Trigger都用上的,不同用户召回个数是不一样的。考虑到有些相似度倒排索引,在某些Trigger下,不一定满3个或者8个,特地加上了Precision这个指标。其中RankI2I为GBDT模型,使用了Swing I2I的作为特征,也使用了item的profile。
PDN模型的SimNet侧使用的特征和RankI2I大体一致,训练目标也一致,均是有好货一跳页的CTR。PDNV13和PDNV43的区别在于,V43采用了带约束学习。
表1 基于有好货曝光日志的离线Hitrate对比
Swing I2I |
RankI2I |
PDNv13 |
PDNv43 |
|
TOP3 Hit-Rate |
7.56% |
14.55% |
12.08% |
22.99% |
TOP3 Precision |
0.08% |
0.15% |
0.12% |
0.23% |
TOP8 Hit-Rate |
13.09% |
20.18% |
22.12% |
34.68% |
TOP8 Precision |
0.06% |
0.09% |
0.09% |
0.14% |
▐ 线上效果
表2是线上AB实验的效果,Baseline是有多路召回组成,分为索引召回部分和向量召回部分。索引召回部分同时用SwingI2I、RankI2I、DeepI2I等,向量召回部分有单塔/双塔(Deep Match)/Node2Vec等等。线上实验是将索引召回全部替换为PDNv43(统一了索引,即Trigger保持不变,替换之前所有种I2I索引)。图6是,PDNv43上线之后的线上占比,它将单/双塔召回的比例压缩为6%。几乎吃掉了全部的算法召回部分的份额。
表2 有好货在线效果对比


图6 有好货在线召回分路占比
▐ 用户Trigger数影响分析
I2I范式的召回,受制于Trigger数的影响。我们特地的对比了多个方法。按照用户的Trigger 数,将用户分为4段:小于等于15的,15~30个的,30~45个的,大于45个的。我们采用两种方法进行验证:一种如表3,是TopN的Hitrate;一种如图7,是TopN用户兴趣的类目覆盖度(Diversity)。
在不同分段上PDN比Swing I2I以及双塔均有较大的提升。值得关注的是,当Trigger数比较少的时候,双塔的Hitrate也低。说明在用户行为不丰富的时候,双塔召回也难以预测用户的兴趣。相对于SwingI2I而言,在Trigger数小于等于45时,hitrate的绝对增幅稳定在20%这样。相对于双塔,hitrate的绝对增幅稳定在15%这样。从多样性的角度,PDNv43相比于双塔,一直维持15~20%绝对值增幅。图7中的BST[3],也是一种双塔向量召回,只是用户序列那侧用Transformer建模。
表3 基于有好货曝光日志的离线Hitrate对比(按照Trigger进行用户分段)
Hirate@300 with various trigger number |
||||
0 |
15 |
30 |
n>45 |
|
SWINGI2I |
6.59% |
11.07% |
13.09% |
14.13% |
双塔(EBR) |
12.30% |
17.51% |
19.06% |
20.04% |
PDNv43 |
26.35% |
32.61% |
32.92% |
29.46% |
PDNV43对比其他方法的hitrate提升值(+后面为绝对提升 x后面为相对提升) |
||||
PDNv43 Vs. Swing |
+20% (×300%) |
+22% (×195%) |
+20%(×152%) |
+15 (×109%) |
PDNv43 Vs. 双塔 |
+14% (×114%) |
+15% (×86%) |
+14%(×73%) |
+9%(×47%) |

图7 用户按照Trigger数分层与多样性
▐ 公开数据数据集对比
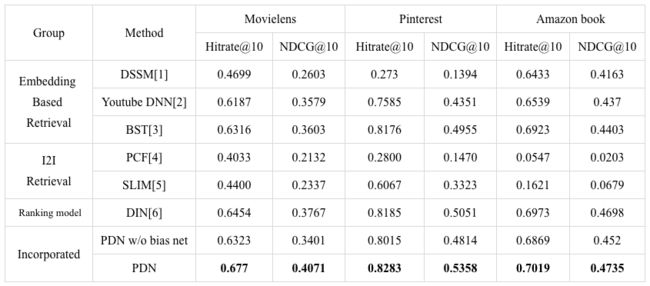
同时也在公开数据集上做了实验。在EBR召回范式中,我们选择了DSSM、Youtube DNN、BST三种模型。这三种模型的区别可以理解为:无用户序列、用户序列mean pooling、用户序列过Transformer。在I2I召回范式中,我们选择了传统的Item-CF、和SLIM。为了突出PDN模型本身具备一定的排序能力,我们同时选择DIN模型作为对比之一。DIN模型在算Hitrate的时候,将对所有的候选集都打一遍,算TopN。
表4
讨论与展望
模型结构也可以理解为两个长度为item corp size(计作N)的稀疏向量进行内积。具体的,对于某个有k次行为的用户来说,其user representation是一个维度为N的向量,但是这个向量上只有k维有值,其他全部为0。对于某一个有m个相似商品的某商品来说,其item representation也是一个维度为N的向量,但其中只有m维有值,其他都为0。又由于k< PDN可以直接当作排序模型来用。这个方向上我们已经在直播信息流的排序模型中进行尝试,目前已经拿到了离线验证的效果。粗排模型的基础上+PDN,相对于粗排模型预测AUC涨+0.6%,已经接近于精排模型的预测AUC。 训练AUC 预测AUC 精排模型:Target Attention + mean pooling 72.2 72.8 粗排模型:User侧Mean pooling + 双塔内积 71.1 72.0 粗排模型的基础上+PDN 72.0 72.63 致谢 感谢邓洪波、飘雪两位老师的的指导。 感谢兄弟团队的合作与支持@云志@为明。 Reference [1] Learning Deep Structured Semantic Models for Web Search using Clickthrough Data. [2] Deep Neural Networks for YouTube Recommendations. [3] Behavior sequence transformer for e-commerce recommendation in Alibaba. [4] Item-Based Collaborative Filtering Recommendation Algorithms. [5] Slim: Sparse linear methods for top-n recommender systems. [6] Deep Interest Network for Click-Through Rate Prediction. ✿ 拓展阅读 作者|济贤、仙基、肖荣 编辑|橙子君 出品|阿里巴巴新零售淘系技术





