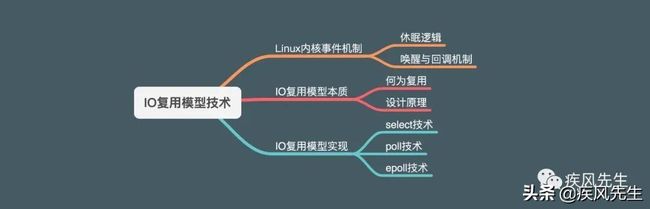
epoll原理_深入分析select&poll&epoll技术原理
首先,我们要了解IO复用模型之前,先要了解在Linux内核中socket事件机制在内核底层是基于什么机制实现的,它是如何工作的,其次,当我们对socket事件机制有了一个基本认知之后,那么我们就需要思考到底什么是IO复用,基于socket事件机制的IO复用是怎么实现的,然后我们才来了解IO复用具体的实现技术,透过本质看select/poll/epoll的技术优化,逐渐去理解其中是为了解决什么问题而出现的,最后本文将围绕上述思维导图列出的知识点进行分享,还有就是文章幅度较长且需要思考,需要认真阅读!
Linux内核事件机制
在Linux内核中存在着等待队列的数据结构,该数据结构是基于双端链表实现,Linux内核通过将阻塞的进程任务添加到等待队列中,而进程任务被唤醒则是在队列轮询遍历检测是否处于就绪状态,如果是那么会在等待队列中删除等待节点并通过节点上的回调函数进行通知然后加入到cpu就绪队列中等待cpu调度执行.其具体流程主要包含以下两个处理逻辑,即休眠逻辑以及唤醒逻辑.
休眠逻辑
- linux 内核休眠逻辑核心代码
// 其中cmd = schedule(), 即一个调用schedule函数的指针#define ___wait_event(wq_head, condition, state, exclusive, ret, cmd)({__label__ __out;struct wait_queue_entry __wq_entry;long __ret = ret;/* explicit shadow */// 初始化过程(内部代码这里省略,直接说明)// 1. 设置独占标志到当前节点entry// 2. 将当前任务task指向节点的private// 3. 同时为当前entry节点传递一个唤醒的回调函数autoremove_wake_function,一旦唤醒将会自动被删除init_wait_entry(&__wq_entry, exclusive ? WQ_FLAG_EXCLUSIVE : 0);for (;;) {// 防止队列中没有entry产生不断的轮询,主要处理wait_queue与entry节点添加或者删除long __int = prepare_to_wait_event(&wq_head, &__wq_entry, state);// 事件轮询检查是否事件有被唤醒if (condition) break;if (___wait_is_interruptible(state) && __int) {__ret = __int;goto __out;}// 调用schedule()方法cmd;}// 事件被唤醒,将当前的entry从队列中移除finish_wait(&wq_head, &__wq_entry);__out:__ret;})- 对此,我们可以总结如下:
- 在linux内核中某一个进程任务task执行需要等待某个条件condition被触发执行之前,首先会在内核中创建一个等待节点entry,然后初始化entry相关属性信息,其中将进程任务存放在entry节点并同时存储一个wake_callback函数并挂起当前进程
- 其次不断轮询检查当前进程任务task执行的condition是否满足,如果不满足则调用schedule()进入休眠状态
- 最后如果满足condition的话,就会将entry从队列中移除,也就是说这个时候事件已经被唤醒,进程处于就绪状态
唤醒逻辑
- linux内核的唤醒核心代码
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode,int nr_exclusive, int wake_flags, void *key,wait_queue_entry_t *bookmark){// 省略其他非核心代码...// 循环遍历整个等待队列list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {unsigned flags = curr->flags;int ret;if (flags & WQ_FLAG_BOOKMARK)continue;//执行回调函数ret = curr->func(curr, mode, wake_flags, key);if (ret < 0)break;// 检查当前节点是否为独占节点,即互斥锁,只能执行一个task,因此需要退出循环if (ret && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)break;if (bookmark && (++cnt > WAITQUEUE_WALK_BREAK_CNT) &&(&next->entry != &wq_head->head)) {bookmark->flags = WQ_FLAG_BOOKMARK;list_add_tail(&bookmark->entry, &next->entry);break;}}return nr_exclusive;}struct wait_queue_entry {unsigned intflags;void*private;// 这里的func就是上述休眠的时候在init_wait_entry传递autoremove_wake_functionwait_queue_func_tfunc;struct list_headentry;};// 唤醒函数int autoremove_wake_function(struct wait_queue_entry *wq_entry, unsigned mode, int sync, void *key){// 公用的唤醒函数逻辑// 内部执行try_to_wake_up, 也就是将wq_entry的private(当前进程)添加到cpu的执行队列中,让cpu能够调度task执行int ret = default_wake_function(wq_entry, mode, sync, key);// 其他为当前唤醒函数私有逻辑if (ret)list_del_init(&wq_entry->entry);return ret;}EXPORT_SYMBOL(autoremove_wake_function);- 对此,基于上述的唤醒逻辑可以总结如下:
- 在等待队列中循环遍历所有的entry节点,并执行回调函数,直到当前entry为排他节点的时候退出循环遍历
- 执行的回调函数中,存在私有逻辑与公用逻辑,类似模板方法设计模式
- 对于default_wake_function的唤醒回调函数主要是将entry的进程任务task添加到cpu就绪队列中等待cpu调度执行任务task
至此,linux内核的休眠与唤醒机制有了上述认知之后,接下来揭开IO复用模型设计的本质就相对会比较容易理解
IO复用模型本质

在讲述IO复用模型之前,我们先简单回顾下IO复用模型的思路,从上述的IO复用模型图看出,一个进程可以处理N个socket描述符的操作,等待对应的socket为可读的时候就会执行对应的read_process处理逻辑,也就是说这个时候我们站在read_process的角度去考虑,我只需要关注socket是不是可读状态,如果不可读那么我就休眠,如果可读你要通知我,这个时候我再调用recvfrom去读取数据就不会因内核没有准备数据处于等待,这个时候只需要等待内核将数据复制到用户空间的缓冲区中就可以了.那么对于read_process而言,要实现复用该如何设计才能达到上述的效果呢?
复用本质
- 摘录电子通信工程中术语,“在一个通信频道中传递多个信号的技术”, 可简单理解: 为了提升设备使用效率,尽可能使用最少的设备资源传递更多信号的技术
- 回到上述的IO复用模型,也就是说这里复用是实现一个进程处理任务能够接收N个socket并对这N个socket进行操作的技术
复用设计原理
在上述的IO复用模型中一个进程要处理N个scoket事件,也会对应着N个read_process,但是这里的read_process都是向内核发起读取操作的处理逻辑,它是属于进程程序中的一段子程序,换言之这里是实现read_process的复用,即N个socket中只要满足有不少于一个socket事件是具备可读状态,read_process都能够被触发执行,联想到Linux内核中的sleep & wakeup机制,read_process的复用是可以实现的,这里的socket描述符可读在Linux内核称为事件,其设计实现的逻辑图如下所示:

- 用户进程向内核发起select函数的调用,并携带socket描述符集合从用户空间复制到内核空间,由内核对socket集合进行可读状态的监控.
- 其次当前内核没有数据可达的时候,将注册的socket集合分别以entry节点的方式添加到链表结构的等待队列中等待数据报可达.
- 这个时候网卡设备接收到网络发起的数据请求数据,内核接收到数据报,就会通过轮询唤醒的方式(内核并不知道是哪个socket可读)逐个进行唤醒通知,直到当前socket描述符有可读状态的时候就退出轮询然后从等待队列移除对应的socket节点entry,并且这个时候内核将会更新fd集合中的描述符的状态,以便于用户进程知道是哪些socket是具备可读性从而方便后续进行数据读取操作
- 同时在轮询唤醒的过程中,如果有对应的socket描述符是可读的,那么此时会将read_process加入到cpu就绪队列中,让cpu能够调度执行read_process任务
- 最后是用户进程调用select函数返回成功,此时用户进程会在socket描述符结合中进行轮询遍历具备可读的socket,此时也就意味着数据此时在内核已经准备就绪,用户进程可以向内核发起数据读取操作,也就是执行上述的read_process任务操作
IO复用模型实现技术
基于上述IO复用模型实现的认知,对于IO复用模型实现的技术select/poll/epoll也应具备上述两个核心的逻辑,即等待逻辑以及唤醒逻辑,对此用伪代码来还原select/poll/epoll的设计原理.注意这里文章不过多关注使用细节,只关注伪代码实现的逻辑思路.
select/poll/epoll的等待逻辑伪代码
for(;;){ res = 0; for(i=0; iselect/poll/epoll的唤醒逻辑伪代码
foreach(entry as waiter_queues){ // 唤醒通知并将任务task加入cpu就绪队列中 res = callback(); // 说明当前节点为独占节点,只能唤醒一次,因此需要退出循环 if(res && current == EXCLUSIVE){ break; } }select技术分析
select函数定义
int select(int maxfd1,// 最大文件描述符个数,传输的时候需要+1 fd_set *readset,// 读描述符集合 fd_set *writeset,// 写描述符集合 fd_set *exceptset,// 异常描述符集合 const struct timeval *timeout);// 超时时间// 现在很多Liunx版本使用pselect函数,最新版本(5.6.2)的select已经弃用// 其定义如下int pselect(int maxfd1, // 最大文件描述符个数,传输的时候需要+1 fd_set *readset,// 读描述符集合 fd_set *writeset,// 写描述符集合 fd_set *exceptset,// 异常描述符集合 const struct timespec *timeout, // 超时时间 const struct sigset_t *sigmask); // 信号掩码指针select技术等待逻辑
// 基于POSIX协议// posix_type.h#define __FD_SETSIZE1024 // 最大文件描述符为1024// 这里只关注socket可读状态,以下主要是休眠逻辑static int do_select(int n, fd_set_bits *fds, struct timespec64 *end_time){struct poll_wqueues table;poll_table *wait;// ...// 与上述休眠逻辑初始化等待节点操作类似(查看下面的唤醒逻辑)poll_initwait(&table);wait = &table.pt;// 获取创建之后的等待节点rcu_read_lock();retval = max_select_fd(n, fds);rcu_read_unlock();n = retval;// ...// 操作返回值retval = 0;for (;;) {//...// 监控可读的描述符socketinp = fds->in;for (i = 0; i < n; ++rinp, ++routp, ++rexp) {bit = 1;// BITS_PER_LONG若处理器为32bit则BITS_PER_LONG=32,否则BITS_PER_LONG=64;for (j = 0; j < BITS_PER_LONG; ++j, ++i, bit <<= 1) {f = fdget(i);wait_key_set(wait, in, out, bit, busy_flag);// 检测当前等待节点是否可读mask = vfs_poll(f.file, wait);fdput(f);if ((mask & POLLIN_SET) && (in & bit)) {res_in |= bit;retval++;wait->_qproc = NULL;}// ...}}// 说明有存在可读节点退出节点遍历if (retval || timed_out || signal_pending(current))break;// ...// 调度带有超时事件的scheduleif (!poll_schedule_timeout(&table, TASK_INTERRUPTIBLE, to, slack))timed_out = 1;}// 移除队列中的等待节点poll_freewait(&table);}select技术唤醒逻辑
// 在poll_initwait -> __pollwait --> pollwake 的方法,主要关注pollwake方法static int __pollwake(wait_queue_entry_t *wait, unsigned mode, int sync, void *key){struct poll_wqueues *pwq = wait->private;DECLARE_WAITQUEUE(dummy_wait, pwq->polling_task);smp_wmb();// 内存屏障,保证数据可见性pwq->triggered = 1;// 与linux内核中的唤醒机制一样,下面的方法是内核执行的,不过多关心,有兴趣可以看源码core.c下面定义// 就是polling_task也就是read_process添加到cpu就绪队列中,让cpu能够进行调度return default_wake_function(&dummy_wait, mode, sync, key);} select技术小结
- select技术的实现也是基于Linux内核的等待与唤醒机制实现,对于等待与唤醒逻辑主要细节也在上文中讲述,这里不再阐述
- 其次可以通过源码知道,在Linux中基于POSIX协议定义的select技术最大可支持的描述符个数为1024个,显然对于互联网的高并发连接应用是远远不够的,虽然现代操作系统支持更多的描述符,但是对于select技术增加描述符的话,需要更改POSIX协议中描述符个数的定义,但是此时需要重新编译内核,不切实际工作.
- 另外一个是用户进程调用select的时候需要将一整个fd集合的大块内存从用户空间拷贝到内核中,期间用户空间与内核空间来回切换开销非常大,再加上调用select的频率本身非常频繁,这样导致高频率调用且大内存数据的拷贝,严重影响性能
- 最后唤醒逻辑的处理,select技术在等待过程如果监控到至少有一个socket事件是可读的时候将会唤醒整个等待队列,告知当前等待队列中有存在就绪事件的socket,但是具体是哪个socket不知道,必须通过轮询的方式逐个遍历进行回调通知,也就是唤醒逻辑轮询节点包含了就绪和等待通知的socket事件,如果每次只有一个socket事件可读,那么每次轮询遍历的事件复杂度是O(n),影响到性能
poll技术分析
poll技术与select技术实现逻辑基本一致,重要区别在于其使用链表的方式存储描述符fd,不受数组大小影响,对此,现对poll技术进行分析如下:
poll函数定义
// poll已经被弃用int poll(struct pollfd *fds, // fd的文件集合改成自定义结构体,不再是数组的方式,不受限于FD_SIZE unsigned long nfds, // 最大描述符个数int timeout);// 超时时间struct pollfd {int fd;// fd索引值short events;// 输入事件short revents;// 结果输出事件};// 当前查看的linux版本(5.6.2)使用ppoll方式,与pselect差不多,其他细节不多关注int ppoll(struct pollfd *fds, // fd的文件集合改成自定义结构体,不再是数组的方式,不受限于FD_SIZE unsigned long nfds, // 最大描述符个数 struct timespec timeout, // 超时时间,与pselect一样 const struct sigset_t sigmask, // 信号指针掩码 struct size_t sigsetsize); // 信号大小poll部分源码实现
// 关于poll与select实现的机制差不多,因此不过多贴代码,只简单列出核心点即可static int do_sys_poll(struct pollfd __user *ufds, unsigned int nfds,struct timespec64 *end_time){// ...for (;;) {// ...// 从用户空间将fdset拷贝到内核中if (copy_from_user(walk->entries, ufds + nfds-todo,sizeof(struct pollfd) * walk->len))goto out_fds;// ...// 和select一样,初始化等待节点的操作poll_initwait(&table);// do_poll的处理逻辑与do_select逻辑基本一致,只是这里用链表的方式遍历,do_select用数组的方式// 链表可以无限增加节点,数组有指定大小,受到FD_SIZE的限制fdcount = do_poll(head, &table, end_time);// 从等待队列移除等待节点poll_freewait(&table);}}poll技术小结
poll技术使用链表结构的方式来存储fdset的集合,相比select而言,链表不受限于FD_SIZE的个数限制,但是对于select存在的性能并没有解决,即一个是存在大内存数据拷贝的问题,一个是轮询遍历整个等待队列的每个节点并逐个通过回调函数来实现读取任务的唤醒
epoll技术分析
为了解决select&poll技术存在的两个性能问题,对于大内存数据拷贝问题,epoll通过epoll_create函数创建epoll空间(相当于一个容器管理),在内核中只存储一份数据来维护N个socket事件的变化,通过epoll_ctl函数来实现对socket事件的增删改操作,并且在内核底层通过利用虚拟内存的管理方式保证用户空间与内核空间对该内存是具备可见性,直接通过指针引用的方式进行操作,避免了大内存数据的拷贝导致的空间切换性能问题,对于轮询等待事件通过epoll_wait的方式来实现对socket事件的监听,将不断轮询等待高频事件wait与低频socket注册事件两个操作分离开,同时会对监听就绪的socket事件添加到就绪队列中,也就保证唤醒轮询的事件都是具备可读的,现对epoll技术分析如下:
epoll技术定义
// 创建保存epoll文件描述符的空间,该空间也称为“epoll例程”int epoll_create(int size); // 使用链表,现在已经弃用int epoll_create(int flag); // 使用红黑树的数据结构// epoll注册/修改/删除 fd的操作long epoll_ctl(int epfd, // 上述epoll空间的fd索引值 int op, // 操作识别,EPOLL_CTL_ADD | EPOLL_CTL_MOD | EPOLL_CTL_DEL int fd, // 注册的fd struct epoll_event *event); // epoll监听事件的变化struct epoll_event {__poll_t events;__u64 data;} EPOLL_PACKED;// epoll等待,与select/poll的逻辑一致epoll_wait(int epfd, // epoll空间 struct epoll_event *events, // epoll监听事件的变化 int maxevents, // epoll可以保存的最大事件数 int timeout); // 超时时间epoll技术实现细节
- epoll_ctl函数处理socket描述符fd注册问题,关注epoll_ctl的ADD方法
// 摘取核心代码int do_epoll_ctl(int epfd, int op, int fd, struct epoll_event *epds, bool nonblock){// ...// 在红黑树中查找存储file对应的epitem,添加的时候会将epitem加到红黑树节点中epi = ep_find(ep, tf.file, fd);// 对于EPOLL_CTL_ADD模式,使用mtx加锁添加到wakeup队列中switch (op) {case EPOLL_CTL_ADD: // fd注册操作// epds->events |= EPOLLERR | EPOLLHUP;// error = ep_insert(ep, epds, tf.file, fd, full_check);break;case EPOLL_CTL_DEL: // // 删除操作:存储epitem容器移除epitem信息break;// 对注册的fd进行修改,但epoll的模式为EPOLLEXCLUSIVE是无法进行操作的case EPOLL_CTL_MOD: // 修改操作,内核监听到事件变化执行修改 //error = ep_modify(ep, epi, epds);break;}// 释放资源逻辑}- EPOLL_CTL_ADD核心代码逻辑
// 添加逻辑static int ep_insert(struct eventpoll *ep, const struct epoll_event *event, struct file *tfile, int fd, int full_check){ // ...struct epitem *epi;struct ep_pqueue epq;// 将fd包装在epitem的epollfile中epi->ep = ep;ep_set_ffd(&epi->ffd, tfile, fd);epi->event = *event;epi->nwait = 0;epi->next = EP_UNACTIVE_PTR;// 如果当前监听到事件变化,那么创建wakeup执行的sourceif (epi->event.events & EPOLLWAKEUP) {error = ep_create_wakeup_source(epi);if (error)goto error_create_wakeup_source;} else {RCU_INIT_POINTER(epi->ws, NULL);}// 添加回调函数epq.epi = epi;init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); // 轮询检测epitem中的事件revents = ep_item_poll(epi, &epq.pt, 1); // 将epitem插入到红黑树中ep_rbtree_insert(ep, epi);// 如果有ready_list 则执行唤醒逻辑wakeup,这个是linux内核的唤醒机制,会将read_process添加到就绪队列中让cpu调度执行if (revents && !ep_is_linked(epi)) {list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);/* Notify waiting tasks that events are available */if (waitqueue_active(&ep->wq))wake_up(&ep->wq);if (waitqueue_active(&ep->poll_wait))pwake++;} // ....// 存在预唤醒,则唤醒轮询等待节点if (pwake) ep_poll_safewake(&ep->poll_wait);return 0;// goto statement code ...}上述代码中存在注册和唤醒逻辑,即对应处理逻辑都在这两个方法ep_ptable_queue_proc & ep_item_poll,现通过流程图如下所示:
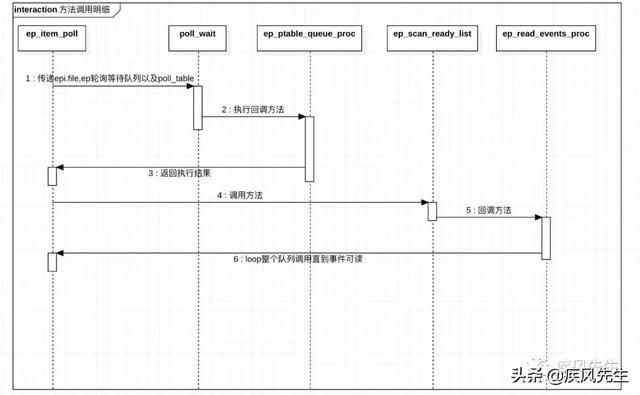
在上述的epoll_ctl技术代码实现的细节中存在着两个逻辑,即socket描述符注册与唤醒逻辑,主要体现在两个核心方法上,即ep_ptable_queue_proc & ep_item_poll对此分析如下:
- 注册逻辑:
- 1) 在epoll空间中创建一个epitem的中间层,初始化一系列epitem的属性,将新增加的socket描述符包装到epitem下的epoll_filefd中,同时添加唤醒任务wakeup,并将epitem的内部ep容器指向epoll空间2) 其次在进行item事件的轮询中,通过队列回调的方式将epitem绑定到队列节点entry上,同时将entry节点添加到epoll空间的等待队列中,并在entry节点上绑定epoll的回调函数来唤醒业务处理3) 最后是将epitem插入以epoll空间为根节点的红黑数中,后续内核可以通过fd查找到对应的epitem,通过epitem也就可以找到其容器epoll空间的引用
- 唤醒逻辑:
- 1) 在item事件轮询中,通过轮询检测epoll空间中的等待队列是否有对应的节点entry可读,如果有退出循环,并且从当前socket描述符对应的中间层epitem开始轮询遍历查询就绪的entry节点并将就绪entry节点的socket描述符添加到ready_list上2) 其次在上述注册的逻辑之后,会检查当前的epitem的ready list节点是否存在,如果存在ready_list,会将epoll空间的等待队列唤醒,让执行处理的read_process添加到就绪队列中,让cpu能够进行调度
- epoll_wait等待逻辑
// epoll_wait -> do_epoll_wait -> ep_poll, 我们关注核心方法ep_pollstatic int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout){// ...fetch_events: // 检测epoll是否有事件就绪// ...for (;;) {// ...// 检测当前ep空间是否有fd事件就绪eavail = ep_events_available(ep);if (eavail)// 是的跳出循环break;if (signal_pending(current)) {res = -EINTR;break;}// 执行休眠方法 schedule()if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) {timed_out = 1;break;}}// ...send_events: // ep有事件就绪,将event_poll转换到用户空间中//...ep_send_events(ep, events, maxevents);}- 从上述可以看出等待处理逻辑主要有fetch_event以及send_events,现分析如下:
- 1) 循环检查当前epoll空间是否有就绪事件,如果有将跳出循环,如果没有将执行schedule的方法进入休眠等待再次轮询,原理与select/poll一致2) 其次当有就绪事件的时候,循环遍历将监听变化的事件拷贝到用户空间中,并且会将就绪事件socket添加到epitem的就绪队列ready_list上
epoll技术解决的问题
- 解决大内存且频繁copy问题
- 1) 首先,epoll通过epoll_create创建epoll空间,在创建epoll空间的同时将其从用户空间拷贝到内核中,此后epoll对socket描述的注册监听通过epoll空间来进行操作,仅一次拷贝2) 其次,epoll注册将拆分为ADD/MOD/DEL三个操作,分别只对相应的操作进行处理,大大降低频繁调用的次数,相比select/poll机制,由原先高频率的注册等待转换为高频等待,低频注册的处理逻辑3) 接着,就是每次注册都通过建立一个epitem结构体对socket相关的fd以及file进行封装,并且epitem的ep容器通过指针引用指向epoll空间,即每次新增加一个socket描述符的时候而是通过单个epitem进行操作,相比fdset较为轻量级4) 最后,epoll在内核中通过虚拟内存方式将内核空间与用户空间的一块地址同时映射到相同的物理内存地址中,这块内存对用户空间以及内核空间均为可见,因此可以减少用户空间与内核空间之间的数据交换
- 解决只对就绪队列进行唤醒循环遍历
- 1) 首先,我们可以看到在注册的过程中,epoll通过epitem将socket描述符存储到epoll_file中,同时将唤醒逻辑read_process也绑定到epitem,这样当处于唤醒状态就会被触发执行,然后将当前epitem存储到队列entry节点上,并且entry节点绑定回调函数,最后将entry节点添加到epoll空间的的等待队列上,而对于select/poll技术实现,会对整个fdset设置对应的callback以及wakeup,epoll则是直接将绑定在wakeup绑定在epitem,并有对应监控socket事件的时候才会创建entry节点并绑定对应的callback函数2) 其次,在进行wiat等待过程中,内核在执行file.poll()后会将等待队列上的节点添加到轮询等待中poll wait,处于半唤醒状态,也就是当前是就绪状态但还没唤醒,同时会将唤醒的socket描述符添加到epoll空间的ready list中3) 接着,每当有一个item被唤醒的时候就会退出上述的轮询遍历并保持当前的item处于唤醒状态,然后epoll空间开始遍历item(单链表存储)并执行回调函数通知,如果item为就绪状态,就将epoll空间的就绪队列ready list拷贝到当前唤醒节点的epitem的ready list中4) 最后,会更新监听变化的事件状态,返回到用户进程,用户进程这个时候获取到ready list中的描述符均为可就绪状态
- epoll其他技术
- 1) epoll支持并发执行,上述的休眠与唤醒逻辑都有加锁操作2) 其次对于就绪状态的ready_list是属于无锁操作,因此为了保证执行并发的安全性在epoll对ready_list进行操作的时候会通过全局加锁的方式完成
epoll技术的边缘触发与水平触发
- 水平触发
- 1) socket接收数据的缓冲区不为空的时候,则一直触发读事件,相当于"不断地询问是否有数据可读"2) socket发送数据的缓冲区不全满的时候,则一直触发写事件,相当于"不断地询问是否有空闲区域可以让数据写入" 本质上就是一个不断进行交流的过程, 水平触发如下图所示:
- 边缘触发
- 1) socket接收数据的缓冲区发生变化,则触发读取事件,也就是当空的接收数据的socket缓冲区这个时候有数据传送过来的时候触发2) socket发送数据的缓冲区发生变化,则触发写入事件,也就是当满的发送数据的socket缓冲区这个时候刚刷新数据初期的时候触发 本质上就是socket缓冲区变化而触发,边缘触发如下图所示:
- 上述的触发事件会调用epoll_wait方法,也就是
- 1) 水平触发会多次调用epoll_wait2) 边缘触发在socket缓冲区中不发生改变那么就不会调用epoll_wait的方式
水平触发与边缘触发代码实现方式
- 水平触发:遍历epoll下的等待队列的每个entry,唤醒entry节点之后从ready_list移除当前socket事件,然后再轮询当前item收集可用的事件,最后添加到ready_list以便于调用epoll_wait的时候能够检查到socket事件可用
- 边缘触发:遍历epoll下的等待队列的每个entry,唤醒entry节点之后从ready_list移除当前socket事件,再轮询当前item收集可用的事件然后唤醒执行的业务处理read_process
你好,我是疾风先生,先后从事外企和互联网大厂的java和python工作, 记录并分享个人技术栈,欢迎关注我的公众号,致力于做一个有深度,有广度,有故事的工程师,欢迎成长的路上有你陪伴,关注后回复greek可添加私人微信,欢迎技术互动和交流,谢谢!

老铁们关注走一走,不迷路