Python爬虫实战:东方财富网股吧数据爬取(二)
Python爬虫实战系列文章目录
Python爬虫实战:东方财富网股吧数据爬取(一)
Python爬虫实战:东方财富网股吧数据爬取(二)
Python爬虫实战:东方财富网股吧数据爬取(三)
Python爬虫实战:东方财富网股吧数据爬取(四)
目录
- Python爬虫实战系列文章目录
- 前言
- 一、项目说明
- 二、问题重述
- 二、实施过程
-
- 1.二次爬取获得年份数据
-
- Ⅰ 查看原始页面网页结构
- Ⅱ 查看跳转页面网页结构
- Ⅲ 二次爬取思路如下:
- 2.完整爬取标题内容,避坑!
- 总结
- 写在最后
前言
昨天有一位朋友私信我如何爬取股吧的年份数据,这才想起来很长时间没有更新这个系列了,十分抱歉。目前项目已经基本结束,已经成功爬取到东方财富网中共2785个股吧的热帖数据。由于目前仍在研究阶段,数据和代码暂时不会公布,之后会上传到Github上,有需要的朋友先可以关注一下~
我的GitHub地址:LeoWang91
一、项目说明
项目需求:股吧中人们的言论行为和股市涨跌的延迟相关性
数据来源:东方财富网、热门个股吧
数据字段:阅读、评论、标题、作者、更新时间
实现功能:读取每个公司股吧的全部页面的数据并写入excel表中
二、问题重述
Python爬虫实战:东方财富网股吧数据爬取(一)
在上篇博客中,我们已经可以初步爬取到东方财富吧中全部发帖信息的阅读、评论、标题、作者及最后更新时间这五个字段的数据,但是由于该网站本身结构的原因,导致我在爬取的过程中踩坑无数,简单归纳为以下几点:
- 股吧中全部发帖信息较多,很容易在爬取过程中被屏蔽IP导致爬取失败,如果你在爬取过程中发现,任意打开一个股吧的网址,出来的都是股市实战吧、财经评论吧,那么很不幸,你的IP也被屏蔽了!解决办法就是使用IP代理池,感谢下面这位大神的分享。时间问题,关于IP代理池的详细使用我们留到下篇博客再说,请大家见谅。
Python爬虫代理IP池(proxy pool))

- 简单看过我第一篇博客的朋友应该都知道,在股吧的页面中,最后更新时间这一个字段没有出现年份数据,没有年份数据做研究也就失去了意义,今天就和大家分享一下如何进行二次爬取。
- 在我爬取过程中,部分标题的网页结构很奇怪,导致我们利用匹配规则不能获取到标题信息,今天和大家分享一下我的解决办法。
二、实施过程
以东方财富吧全部股吧的热帖数据为例
1.二次爬取获得年份数据
Ⅰ 查看原始页面网页结构
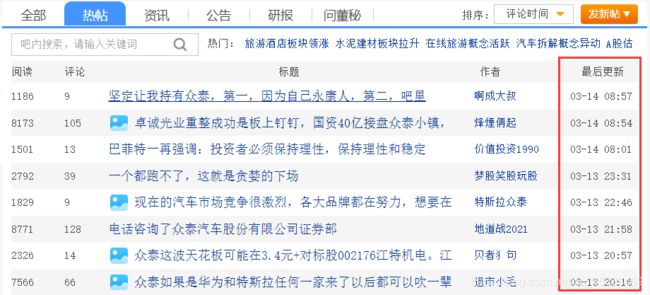
在股吧的热帖页面中,我们可以看到最后更新这一字段并没有年份信息,点击查看网页结构:
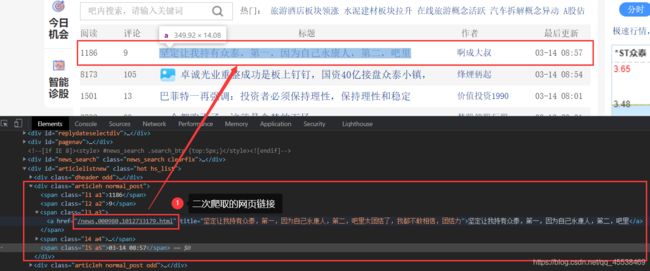
我们可以看到,该标题标签为:
<a href="/news,000980,1012733179.html" title="坚定让我持有众泰,第一,因为自己永康人,第二,吧里太团结了,我都不敢相信,团结力">坚定让我持有众泰,第一,因为自己永康人,第二,吧里a>
Ⅱ 查看跳转页面网页结构
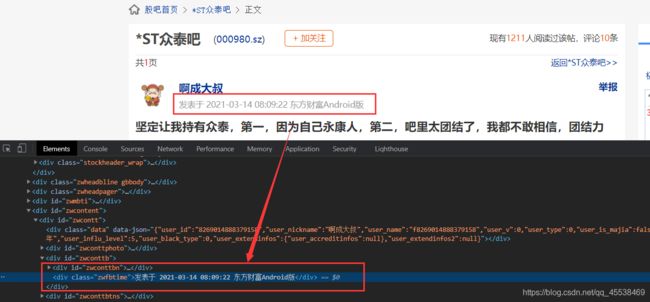
点击网页中这条贴吧,查看网址链接及字段内容:
链接:https://guba.eastmoney.com/news,000980,1012733179.html
Ⅲ 二次爬取思路如下:
我们在一次爬取标题时,可以先获取标题title及所带的链接whole_url:
注意:由于标签中的链接是不完整的,所以需要拼接两个网址
# 需要使用的库
from bs4 import BeautifulSoup
from urllib import parse
# 字段声明
title = [] # 存放当前页面所有标题信息
post_urls = [] # 存放当前页面所有跳转页面的完整链接信息
## 部分代码,不可直接复制
# html是经过解析后的网页内容
# url是当前某一股吧热帖的页面链接
soup = BeautifulSoup(html, "html.parser")
for each in soup.find_all('span', 'l3 a3'):
first = each.select('a:nth-of-type(1)')# 选择器
for i in first:
title.append(i.title)
news_comment_urls = i.get('href')
# print(news_comment_urls)
# 用 urllib 的 urljoin() 拼接两个网址
# 第一个参数是基础母站的url,第二个是需要拼接成绝对路径的url
whole_url = parse.urljoin(url, news_comment_urls)
# print(whole_url)
post_urls.append(whole_url)
现在whole_url中已经获取到该帖的网址链接,则只需解析该网页结构,捕捉到含有年份的数据字段,重新写入time列表中即可:
<div class="zwfbtime">发表于 2021-03-14 08:09:22 东方财富Android版</div>
注意:由于我们只需要时间信息,所以需要对div中的字段做个提取

# 获取网页内容
def getHTMLText(url):
try:
r = requests.get(url, timeout=(3,7))
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("获取" + str(url) + "网页内容失败!")
# 获取年份时间的完整代码
def getTime(html):
time = ''
try:
soup = BeautifulSoup(html, "html.parser")
time = soup.find('div', 'zwfbtime')# 从网页结构得出
if time is None:
time = ''
else:
# 发表于 2021-03-14 08:09:22 东方财富Android版
# ["发表于","2021-03-14","08:09:22","东方财富Android版"]
# 提取时间信息
time = ' '.join(time.string.split(' ')[1:3])
except:
print("未获取到动态时间")
return time
## 部分代码,不可直接复制
time = [] # 存放当前页面所有时间信息
# 先获取到原始页面的时间信息
for each in soup.find_all('span', 'l5 a5'):
time.append(each.string)
time = time[1:] # 除去页面开始含有的“最后更新”字符串
# 二次爬取含有年份的时间信息
for t in range(len(time)):
text = getHTMLText(post_urls[t])
gettime = getTime(text)
# print(time)
time[t] = gettime
这时候我们的最后更新时间字段就全部变成有年份信息的啦!
2.完整爬取标题内容,避坑!
在爬取标题内容的过程中,中间出现很多错误,但是由于忘记打印日志了,一时半会找不到具体例子,所以直接把自己的解决办法拿出来分享啦,主要改变的是上面说的标题title及所带的链接whole_url的代码部分。
# 部分代码,不可直接复制
for each in soup.find_all('span', 'l3 a3'):
first = each.select('a:nth-of-type(1)')
if not first:
title.append('None')
post_urls.append('None')
continue
count = 0
for i in first:
count = count + 1
for i in first:
i.find_all("a")
if i.get('href')[:5] == '//ask':
continue
if i.title== '问董秘' and i.get('href')[:5] != '/news':
continue
if count >= 2:
if i.get('href')[:5] != '/news':
continue
title.append(i.title)
news_comment_urls = i.get('href')
# print(news_comment_urls)
# 用 urllib 的 urljoin() 拼接两个网址
# 第一个参数是基础母站的url,第二个是需要拼接成绝对路径的url
whole_url = parse.urljoin(url, news_comment_urls)
# print(whole_url)
post_urls.append(whole_url)
总结
说到这里,爬取东方财富网股吧数据的细节部分说的差不多了,如果我想到新的内容再和大家分享,关于IP代理池的详细使用说明,就在下一章节中再和大家分享啦,下期再见啦!
写在最后
【学习交流】
WX:WL1498544910
【文末小宣传】
----博主自己开发的小程序,希望大家的点赞支持一下,谢谢!-----
