Python爬虫实战:东方财富网股吧数据爬取(四)
Python爬虫实战系列文章目录
Python爬虫实战:东方财富网股吧数据爬取(一)
Python爬虫实战:东方财富网股吧数据爬取(二)
Python爬虫实战:东方财富网股吧数据爬取(三)
Python爬虫实战:东方财富网股吧数据爬取(四)
目录
- Python爬虫实战系列文章目录
- 前言
- 一、项目说明
- 二、问题重述
- 二、实施过程
-
- 1.登录/注册,进入后台做验证授权
- 2.点击“获取列表”获取API接口
- 3.获取代理IP并访问
- 4.封装函数写入爬虫
- 总结
- 写在最后
前言
本篇文章主要介绍一下代理商提供的IP代理池的使用方法。功能与上篇文章提到的Proxy Pool代理池类似,但相对来说比较稳定一些,大家可以根据实际情况自行选择。
后期的完整代码会公布在我的GitHub上,需要的朋友可以提前关注一下!
我的GitHub地址:LeoWang91

一、项目说明
项目需求:股吧中人们的言论行为和股市涨跌的延迟相关性
数据来源:东方财富网、热门个股吧
数据字段:阅读、评论、标题、作者、更新时间
实现功能:读取每个公司股吧的全部页面的数据并写入excel表中
二、问题重述
Python爬虫实战:东方财富网股吧数据爬取(一)
Python爬虫实战:东方财富网股吧数据爬取(二)
Python爬虫实战:东方财富网股吧数据爬取(三)
【代理云介绍】
代理云是企业级代理服务器池方案提供商,产品线涵盖高性能代理服务器软件开发、部署与运维。并提供公共代理池租用与私有代理池定制等业务。代理云自2014年上线以来,以资源和技术服务双引擎驱动,助力数据效果优化,先后为近百家企业提供解决方案,目前客户已覆盖大数据、互联网传媒、征信、电商、金融、旅游、教育等行业。
二、实施过程
1.登录/注册,进入后台做验证授权
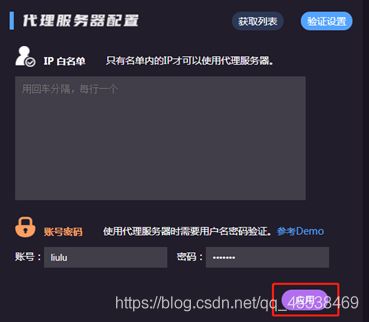
验证方式共有两种,都需要5-10分钟的同步
- IP白名单:将出口IP填入到 IP白名单列表中,需是固定静态IP(百度搜索IP地址即可)。
- 帐号密码验证:可以在后台修改,默认后台的登录帐号密码。
2.点击“获取列表”获取API接口

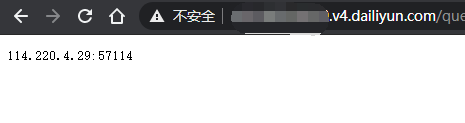
3.获取代理IP并访问
API规则
http://[usernm].v4.dailiyun.com/query.txt?key=[hashid]&word=[word]&count=[count]&rand=[rand]<ime=[ltime]&norepeat=[norepeat]&detail=[detail]&idshow=[idshow]
[usernm] 用户名
[hashid] 用户KEY
[word] 筛选地区 默认 空字符串
[count] 获取的数量 默认 1
[rand] 随机获取 默认 false
[ltime] 至少可用时间(秒) 默认 0
[norepeat] 不重复提取(当日) 默认 false
[detail] 显示细节 默认 true
[idshow] 显示服务器ID 默认 false
4.封装函数写入爬虫
- 我们将此api封装成函数,在爬虫代码中直接使用:
# api函数封装函数
import requests
def get_proxy():
proxy = requests.get("http://wl1498544910.v4.dailiyun.com/query.txt?key=NPD14A59CD&word=&count=1&rand=false<ime=0&norepeat=false&detail=false")
# print(proxy.text)
return proxy.text
# 爬虫代码部分
# 获取网页内容
def getHTMLText(url):
proxy = get_proxy()
# print(proxy) # 可以输出查看每次爬取时所用的IP地址
try:
# 使用代理访问
r = requests.get(url, proxies={
"http": "http://{}".format(proxy)}, timeout=20)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception:
print("获取" + str(url) + "网页内容失败!")
def ......
总结
至此Python爬虫系列文章就到此结束啦,感谢大家的一直关注,想让博主出什么系列的专栏呢?可以在评论区下方留言哟,会的一定教给大家~
点个赞加个关注再走啦!
写在最后
【学习交流】
WX:WL1498544910
【文末小宣传】
----博主自己开发的小程序,希望大家点赞支持一下,谢谢!-----
