飞桨百度领航团零基础学Python之函数(二)
函数进阶
- 1. lambda匿名函数
- 2. 高阶函数
-
- 2.1 map函数
- 2.2 reduce函数
- 2.3 sorted函数
- 3. 装饰器
- 4. 偏函数
- 5. 模块
- 6. 闭包
- 补充:函数作为返回值
1. lambda匿名函数
python 使用 lambda 来创建匿名函数。lambda 只是一个表达式,函数体比 def 简单很多。lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。lambda 函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
lambda匿名函数是很有Python风格的函数,下面来看如何定义lambda匿名函数。
# 定义格式如下:
# lambda 若干个输入参数 : 返回值的表达式
# 例如:lambda arg1, arg2: arg1 + arg2
(lambda arg1, arg2: arg1 + arg2 )(1, 2) # 结果为 3
为了方便表达,也可以给 lambda 函数起个名字
# 加法运算 接受两个参数,返回参数之和
add = lambda arg1, arg2: arg1 + arg2
add(1,2) # 结果为3
再给出一个例子
# 数字转字符串
int2str = lambda x : str(x)
int2str(5) # 结果为'5'
2. 高阶函数
- 函数名其实就是指向函数的变量!
# print 为内建函数
my_print = print
my_print('a') # 结果为 a
- 函数的名字也可以作为一个变量,传入其它函数
def func_x(x, f):
return f(x)
func_x(-1, abs) # 结果为 1
- 一个函数可以接收另一个函数作为参数,这种函数就称之为高阶函数
int2str = lambda x : str(x)
func_x(-112, int2str) # 结果为 '-112'
下面给出 一个更复杂的例子
def func_xy(x, y ,f):
return f(x,y)
add = lambda x,y : x+y
mul = lambda x,y : x*y
SS = lambda x,y : x**2 + y**2
print(func_xy(1,2,add)) # 结果为 3
print(func_xy(1,2,mul)) # 结果为 2
print(func_xy(1,2,SS)) # 结果为 5
2.1 map函数
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
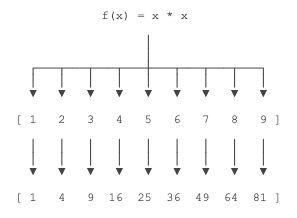
下面给出一个代码示例。使用 map 函数将lambda函数 fx 作用到可迭代对象 ls 上,最后以列表形式输出。
fx = lambda x:x**2
ls = [1,2,3,4,5,6,7,8,9]
rst = map(fx, ls)
list(rst)
最后的结果如下:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
下面再举一个例子:
使用 map 函数将lambda函数 int2str 作用到可迭代对象 ls 上,最后以列表形式输出。
int2str = lambda x : str(x)
rst = map(int2str, ls)
list(rst)
最后的结果如下:
['1', '2', '3', '4', '5', '6', '7', '8', '9']
2.2 reduce函数
用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,依此类推,最后得到一个结果。reduce的操作过程如下图所示。

# 从python3开始,reduce函数移动到了functools这个包,每次使用前要先import
from functools import reduce
mul_xy = lambda x, y: x*y
reduce(mul_xy, [1, 3, 5, 7, 9]) #最后的结果为 945
2.3 sorted函数
排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
- 从小到大排序
sorted([36, 5, -12, 9, -21]) # 结果为 [-21, -12, 5, 9, 36]
- 从大到小排序
sorted([36, 5, -12, 9, -21], reverse=True) # 结果为 [36, 9, 5, -12, -21]
- 按绝对值排序key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序
sorted([36, 5, -12, 9, -21], key=abs) # 结果为 [5, 9, -12, -21, 36]
- 按x坐标排序
points = [(5,2), (7,3), (3,4),(1,1),(2,6)] #
f_x = lambda x:x[0]
sorted(points, key=f_x) # 结果为 [(1, 1), (2, 6), (3, 4), (5, 2), (7, 3)]
- 按y坐标排序
f_y = lambda x:x[1]
sorted(points, key=f_y) # 结果为 [(1, 1), (5, 2), (7, 3), (3, 4), (2, 6)]
- 按与零点距离排序
f_r = lambda x:x[0]**2+x[1]**2
sorted(points, key=f_r) # 结果为[(1, 1), (3, 4), (5, 2), (2, 6), (7, 3)]
3. 装饰器
顾名思义,从字面意思就可以理解,它是用来"装饰"Python的工具,使得代码更具有Python简洁的风格。换句话说,它是一种函数的函数,因为装饰器传入的参数就是一个函数,然后通过实现各种功能来对这个函数的功能进行增强。
# 装饰器输入一个函数,输出一个函数
def print_working(func):
def wrapper():
print(f'{func.__name__} is working...')
func()
return wrapper
def worker1():
print('我是一个勤劳的工作者!')
def worker2():
print('我是一个勤劳的工作者!')
def worker3():
print('我是一个勤劳的工作者!')
worker1 = print_working(worker1)
worker1()
worker2 = print_working(worker2)
worker2()
运行结果如下:
worker1 is working...
我是一个勤劳的工作者!
worker2 is working...
我是一个勤劳的工作者!
使用修饰器
@print_working
def worker1():
print('我是一个勤劳的工作者!')
@print_working
def worker2():
print('我是一个勤劳的工作者!')
@print_working
def worker3():
print('我是一个勤劳的工作者!')
worker1()
worker2()
worker3()
worker1 is working...
我是一个勤劳的工作者!
worker2 is working...
我是一个勤劳的工作者!
worker3 is working...
我是一个勤劳的工作者!
装饰器最大的优势是用于解决重复性的操作,其主要使用的场景有如下几个:
- 计算函数运行时间
- 给函数打日志
- 类型检查
当然,如果遇到其他重复操作的场景也可以类比使用装饰器。
# 带参数的装饰器
def arg_decorator(func):
def wrapper(*args, **kw):
print(f'{func.__name__} is working...')
func(*args, **kw)
return wrapper
@arg_decorator
def student_info(name, age=18, *books, **kw):
print(f'我的名字叫{name}, 今年{age}岁,我有很多本书:')
for book in books:
print(book)
print(kw)
student_info('Molly',18, '语文书','数学书',height=170)
运行结果如下:
student_info is working...
我的名字叫Molly, 今年18岁,我有很多本书:
语文书
数学书
{
'height': 170}
4. 偏函数
通过设定参数的默认值,降低函数调用的难度。
from functools import partial
def student_info(name, age, city):
print(f'我的名字叫{name}, 今年{age}岁,来自{city}')
student_info_beijing = partial(student_info, city='北京')
student_info_beijing('Molly',18)
运行结果如下:
我的名字叫Molly, 今年18岁,来自北京
默认值也可以改变。
student_info_beijing('Molly',18, city='上海')
运行结果如下:
我的名字叫Molly, 今年18岁,来自上海
下面给出另一个例子
def add_xy(x,y):
return x+y
add_100 = partial(add_xy, y=100)
add_100(10) # 结果为 110
5. 模块
import time
# 和装饰器结合
def time_decorator(func):
def wrapper():
time_start = time.time()
func()
time_end = time.time()
print(f'程序执行了{round(time_end-time_start, 3)}秒')
return wrapper
@time_decorator
def a_loop():
for i in range(int(1e7)):
continue
a_loop()
运行结果如下:
程序执行了0.257秒
6. 闭包
python中的闭包从表现形式上定义(解释)为:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure).

返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
def create_pointer(my_string):
def pointer(n):
return my_string[n]
return pointer
pointer = create_pointer('my name is Molly')
pointer(5) # 结果为 'm'
# 一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。
def count():
fs = []
for i in range(1, 4):
def f():
# print(id(i))
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1()) # 结果为9
print(f2()) # 结果为9
print(f3()) # 结果为9
def count():
def f(j):
def g():
# print(id(j))
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
f1, f2, f3 = count()
print(f1()) # 结果为 1
print(f2()) # 结果为 4
print(f3()) # 结果为 9
补充:函数作为返回值
def calc_sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum(1, 3, 5, 7, 9) # 这里暂时还不想计算
f() # 结果为 25
查看函数使用内存
f1 = lazy_sum(1, 3, 5, 7, 9)
print(id(f1))
f2 = lazy_sum(1, 3, 5, 7, 9)
print(id(f2))
运行结果如下:
140410816110672
140410816111104