Outlier Detection for Improved Data Quality and Diversity in Dialog Systems-学习笔记
Outlier Detection for Improved Data Quality and Diversity in Dialog Systems
- 论文按如下方式检测数据集中的异常值:
1.生成每个实例的矢量表示。
2.平均向量以获得均值表示。
3.计算每个实例与平均值的距离。
4.按距离升序排列。
5.(删除列表,仅将前k%作为离群值。)
最后一步用括号括起来,因为在实践中使用动态阈值方法,允许用户根据喜好浏览或多或少的列表。
- 论文提出了一种使用句子的连续表示的新的异常值检测方法。可结合神经距离嵌入和基于距离的离群值检测来检测短文本语料库中的错误样本和唯一样本。
- 与集合中其他示例相距甚远的示例可能是一个异常值,原因有两个:(1)它不是这个类的有效实例(即一个错误),或者(2)它是这个类的一个不寻常的示例(即唯一的)。
- 离群值检测不仅可以用于发现错误,还可以用于其他方面。没有错误的异常值可能是数据集中最有趣,信息量最大的示例。使用这些示例在迭代过程中指导数据收集,可以产生更多不同的数据。
- Universal Sentence Encoder(USE; Cer et al.,2018)一种深度平均网络方法,该方法对单词嵌入进行平均并通过前馈网络传递结果。平滑逆频率(SIF; Arora et al., 2017)词嵌入的加权平均值,权重由语料库中的词频确定。
- Borda计数将同一项目集的多个排名列表汇总到一个排名列表中。首先,将点分配给每个列表中的每个项目,一个项目在长度为N的排名列表中的位置i上获得N–i个点。接下来,在所有列表中汇总项目得分。最后,按总点数对项目进行排名,从而产生最终排名。
- 人工数据集通过混合来自不同意图的数据来注入噪声。 这提供了一种控制异常数据的数量和类型的简便方法。
PPT
提高对话系统数据质量和多样性的离群点检测
Outlier Detection
论文提出了一种使用句子的连续表示的新的异常值检测方法。可结合神经距离嵌入和基于距离的离群值检测来检测短文本语料库中的错误样本和唯一样本。

最后一步用括号括起来,因为在实践中使用动态阈值方法,允许用户根据喜好浏览或多或少的列表。能够捕获每个类空间的语义结构。与集合中其他示例相距甚远的示例可能是一个异常值,原因有两个:(1)它不是这个类的有效实例(即一个错误),或者(2)它是这个类的一个不寻常的示例(即唯一的)。这种方法独立地应用于每一类数据。

作为示例应用程序,论文中考虑对话系统的两个任务:意图分类和插槽填充。 为了进行分类,分别考虑每个可能的意图标签的数据,这意味着通过一次考虑一个意图类别来发现数据中的异常值。 对于插槽填充,根据插槽的组合将数据分组。
这个离群点检测方法很简单,因为它只依赖于句子嵌入方法、距离度量和阈值k;不涉及任何超参数。而且,这种方法不需要训练。
 离群值检测不仅可以用于发现错误,还可以用于其他方面。没有错误的异常值可能是数据集中最有趣,信息量最大的示例。论文中建议使用这些示例在迭代过程中指导数据收集,以产生更多不同的数据为目标。为了证明这一想法,该论文开发了一种新颖的众包管道进行数据收集。
离群值检测不仅可以用于发现错误,还可以用于其他方面。没有错误的异常值可能是数据集中最有趣,信息量最大的示例。论文中建议使用这些示例在迭代过程中指导数据收集,以产生更多不同的数据为目标。为了证明这一想法,该论文开发了一种新颖的众包管道进行数据收集。
data collection pipeline
论文还提出了一种建立在该论文的检测技术之上的新颖的数据收集管道,可以自动并迭代地挖掘唯一的数据样本,同时丢弃错误的样本。

图1a显示了一个常见的众包管道。任务设计人员编写种子语句,目标是意图(用于分类)或槽(用于槽填充)。群众工作人员读种子,写释义。这些释义随后传递给另一组工作人员,他们验证这些释义是否确实准确。该标准管道有两个主要缺点。首先,验证步骤会增加每个示例的成本。其次,释义的多样性取决于给定的种子句。论文中引入了一个新管线,如图1b所示,该管线使用异常检测来(1)减少要检查的句子数量,(2)收集更多示例。
该方法使用异常检测来选择要检查的句子子集:即,被排列为最有可能成为离群值的句子。通过专注于最可能是错误的句子,可以减少工作量。
为了尝试增加多样性,论文中还介绍了一个包含多轮数据收集的过程。
1.在一轮中收集的异常值复述用于播种下一轮数据收集。可以在验证步骤中直接使用标记为正确的句子,但是尽管这些句子是正确的,但它们可能与期望的语义有所不同(例如,与期望类有所不同)。
2.为了避免下一轮的混乱,论文增加了一个步骤,在该步骤中,向工作人员显示了另一个意图中基于句子嵌入距离最相似的句子,并询问新种子是否更类似于其预期意图或替代示例。仅保留被判断为更接近其预期意图的种子。
该迭代过程旨在通过激发工作人员思考当前数据中未充分涵盖的意图措辞的方式来收集更多数据。
实验结果与分析

所有实验都是在英语数据上进行的。论文中进行了两组实验来探讨论文的离群点检测方法的有效性。首先考虑错误检测,比较人工和实际数据方案中的各种排名方法。
人工数据集通过混合来自不同意图的数据来注入噪声。 这提供了一种控制异常数据的数量和类型的简便方法。其中考虑的特定数据是来自生产中对话系统的20个意图的集合。 为了生成给定意图类别Xi的离群值,从其他意图中随机抽取了 p ·|Xi| 个句子(例如p = 0.04或4%)。

来自真实数据集的示例。 “我有多少钱”示例被标记为与平衡意图非常相似的错误。 “我能负担得起什么?”,“我的银行信息”和“没有复选框,还有更多?” 这些示例由于过于模糊和模棱两可而被标记为错误。

使用平均精度(MAP)作为列表质量的总体度量。MAP是以下目的的均值。
在排名列表中选择阈值k时,想要了解精度-召回权衡。

表1给出了在两种设置(人工和真实)下用于错误检测的MAP和Recall @ k。为了进行比较,论文考虑了四个简单的基线:对样本进行随机排序(随机),从最短到最长排序(短),从最长到最短排序(长),以及计算由一袋单词定义的向量空间中的距离(BoW)。
在这两种情况下,神经方法都优于基线,这证明了论文中提出的方法的有效性。
但是,神经方法的相对性能在两种设置之间有很大差异。 具体来说,(1)SIF在人工数据上的表现要好于未加权平均值,但在实际数据上我们看到了相反的趋势,(2)将排名与Borda结合在一起似乎对人工数据有所帮助,但对实际数据却无济于事,(3 )按长度排序对真实数据出乎意料地有效,并且(4)结果往往低于真实数据(甚至更低的p值)。 最后一点表明,常用的数据设置不能完美地捕获实践中发生的错误类型。
 图2显示了两种方法中每种方法的分布。神经方法尤其是USE的有效性再次明确。 在实际数据中,仅考虑列表中的前20%,USE平均会覆盖85%以上的错误。
图2显示了两种方法中每种方法的分布。神经方法尤其是USE的有效性再次明确。 在实际数据中,仅考虑列表中的前20%,USE平均会覆盖85%以上的错误。
 一个对于USE较难的例子是“我的银行有多少钱”,目的是要求用户的余额。直到最后一句话,此示例看起来都是一个有效的余额请求。这些示例表明,该系统在质量上符合我们对错误检测的期望。
一个对于USE较难的例子是“我的银行有多少钱”,目的是要求用户的余额。直到最后一句话,此示例看起来都是一个有效的余额请求。这些示例表明,该系统在质量上符合我们对错误检测的期望。
 带插槽填充任务的示例注释语句。 插槽名称是(外观顺序)度量标准,金额,货币和日期。
带插槽填充任务的示例注释语句。 插槽名称是(外观顺序)度量标准,金额,货币和日期。

第三种情况相当于图1a中的标准管道。所有三条管道都从第一轮开始,然后在随后的几轮中变化,如图4所示。每个管道收集了三轮的数据。 每种方法的最终数据集结合了从所有三个回合中收集的数据。
在这两个任务中,都要求工作人员将每个种子语句重新措辞5次,然后将每个种子语句显示给15个工人。 对于分类,每个意图有3个种子句子。 对于插槽填充,定义了4个示例场景,每个场景都对应于插槽的特定组合。 对于异常值检测模型,将Borda USE + SG的k设置为10%。

分类:表3列出了每种方法在每个回合中收集的示例数量和数据多样性。使用论文中提出的独特方法选择的种子,多样性始终较高。
表4显示了每种训练和测试组合的准确性得分和覆盖范围。最高分在对角线上-对相同的源数据进行训练和测试。对唯一数据进行训练会生成一个健壮的模型,该模型在所有三个测试集中均表现良好。相反,对相同或随机数据的训练会产生在唯一测试集上表现较差的模型。该趋势也显示在表格底部的覆盖率得分中。
 表7显示了一些独特和随机方法产生的种子语句。这些示例说明了指标的趋势,而随机方法的种子通常非常相似。同时,独特的方法产生具有语法变异的种子,并引入了完全不同的表达方式,例如“ ABA”而不是“ routingnumber”。
表7显示了一些独特和随机方法产生的种子语句。这些示例说明了指标的趋势,而随机方法的种子通常非常相似。同时,独特的方法产生具有语法变异的种子,并引入了完全不同的表达方式,例如“ ABA”而不是“ routingnumber”。
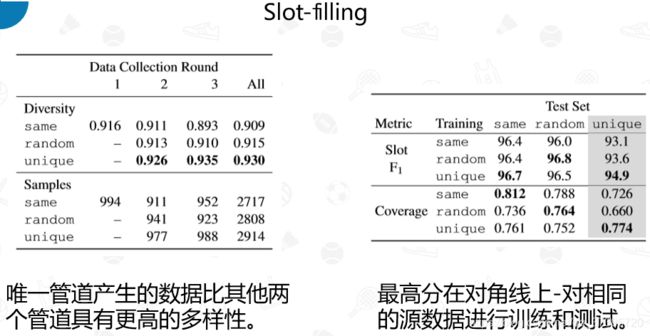
插槽填充:表5显示了每个数据收集管道每轮收集的样本数量以及集合的多样性。 正如在分类实验中一样,可以观察到唯一管道产生的数据比其他两个管道具有更高的多样性。
表6显示了每种训练测试组合的F1分数和覆盖率。 可以再次看到了相同的趋势,在相同或随机的数据集上进行训练会导致唯一数据集的结果较低,但不是相反,在覆盖率上也会出现类似的情况,尽管差距小于分类。