Pytorch 语义分割DeepLabV3+ 训练自己的数据集 从数据准备到模型训练
实现自动生成标注的图像分割设计
- 项目需求:本人接触项目要求实现砂石级配,因此第一步是实现砂石语义分割,将平铺的砂石个体分割出来。
- 步骤:获得分割样本->制作标签,VOC2012格式打包->
利用DeepLabV3+完成语义分割工作->进一步研究
目录
- 实现自动生成标注的图像分割设计
-
- 一、数据处理
- 二、制作标签
-
- 使用labelme实现标注
- 标签自动生成
- 三、VOC格式打包
- 四、环境配置
- 五、网络训练
- 六、模型测试
一、数据处理
通过传统图像处理方法获得自动标注数据。
图像处理方法后续单独写一篇介绍,基本采用:阈值分割粗对象、形态学滤除小杂点、色彩空间变换实现。
二、制作标签
这里没有利用经典套路通过开源标注工具(labelme等)进行像素级标注的方法,因为我们的目的是自动标签生成。但是博主仍做了少量数据的人工标注,用作label.png格式的对比和参考。
使用labelme实现标注
参考博文:
mac安装labelme
anaconda 新建labelme环境:
conda create -n labelme python=3.6
进入环境
source activate labelme
使用conda安装以及其他依赖组件
conda install labelme -c conda-forge
# 需要pyqt5
conda install pyqt5
conda install -c conda-forge pyside
安装完成后在命令行打开labelme,即开启可视化界面,可以开始绘制标签啦!
注意我这里labelme似乎只能制作png格式数据,jpg格式无法打开。似乎有解决方法,但mac一键批量导出不香么?解决方法
使用shell将生成的JSON文档转换成PNG、yaml和PNG_viz可视化格式
labelme_json_to_dataset <文件名>.json
批量处理
num=100
for ((i=1;i<num;i++))
do
python json_to_dataset.py dataset/img$i.json -o output/img$i
done
标签自动生成
利用阈值分割的思想处理原图得到像素级标签。这里的“原图”是在实验室的光照、背景合适的理想环境下得到,后续考虑采用迁移学习的方法增强在实际应用场景下的鲁棒性。
from PIL import Image
import cv2
import numpy as np
import os
def auto_label(dirPic, width, height):
file_list = os.listdir(dirPic + 'gray/')
color = [255, 255, 255]
print('start labelling!!!')
for filename in file_list:
path = ''
path = dirPic + 'gray/' + filename
path2 = dirPic + 'gray_512/' + filename
try:
image = cv2.imread(path)
print(f'{filename} is on precessing.')
# resize image
width = 512
height = 512
dim = (width, height)
gray = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
# 单通道转换3通道
# # gray_BGR = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# image = np.expand_dims(gray, axis=2)
# gray_BGR = np.concatenate((image, image, image), axis=-1)
# print('BGR is ok!')
# OTSU阈值分割
ret, th = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
print(f'ret = {ret}')
# 开/闭运算
kernel = np.ones((5, 5), np.uint8)
kernel2 = np.ones((5, 5), np.uint8)
opening2 = cv2.morphologyEx(th, cv2.MORPH_OPEN, kernel)
closing2 = cv2.morphologyEx(opening2, cv2.MORPH_CLOSE, kernel2)
except:
# mac系统自带.DS_Store隐藏文件
print('find .DS_Store!')
continue
if __name__ == '__main__':
dirPic = '/Users/Sigrid/Desktop/stones/dataset/'
auto_label(dirPic, 512, 512)
从原图即可得到二值化后的标签样本:

这里最终要求label.png的像素值在[0~255]中连续,因此0表示背景,即无类别;1表示二分类的对象,这里是stones。如果是多分类就再次基础上2, 3…
可以用PIL包可视化最终的标签结果:
from PIL import Image
imagePath = '/Users/Sigrid/Desktop/stones/dataset/0806_png/gray2/IMG_3709.png'
im = Image.open(imagePath)
im = Image.fromarray(np.uint8(im))
# im = Image.fromarray(np.uint8(im)*20) # 可以看到灰色的标签对象
# 同时实现图像位深度24到8位转换
im.save(imagePath)
im.show()
三、VOC格式打包
参考博文:VOC2012格式详解
细节问题不再赘述,值得注意的点有:
- palette调色板:单通道但是显示彩图的原因
- 8位单通道格式
- 样本和标签的存放位置
- txt文本记录train/val/test数据集索引
尤其是第一点,困扰了博主单休日从早到晚,但其实从原理上理解就不困难:
我们看到的彩色数字图像从采集角度可以分为真彩色和伪彩色图像。真彩色的典型代表是RGB的3通道图像,其实还有其他色彩空间如HSV、HSB和YCrCb等,根据采集设备和光谱的不同波段有关。而伪彩色原始图像是灰度图像,即单通道图像。
但是为什么我们在打开伪彩图是可以看到彩色的图像呢?这就是palette的原理:色彩映射color map。
将不同灰度区间内的灰度值通过colormap,一个N3的矩阵,映射到色彩空间,实现以单通道的形式存储,多通道的格式显示的目的。(这里N表示分类类别,如VOC就是20+1,3表示RGB的3通道)
参考方法:Python为8bit深度图像应用color map
以及:调色板的数据存储机制
使用labelme做数据标注的小伙伴不用担心这个问题,因为在json_to_dataset这一步以及自动完成了。本人是在自己做标签时遇到了这个问题,实际放入SegmentationClass的文件以何种方式存储?还有分割结果可视化时颜色为何与输入不符?
实际标签数据如下图左一,格式如右一所示,中间为了展示将数值为1部分20突出

四、环境配置
使用经典DeepLabV3+作为分割模型,GitHub传送门
数据集处理和环境配置参考博文:灰色海岸线和红色票据
常规操作步骤:
- Clone the repo:
git clone https://github.com/jfzhang95/pytorch-deeplab-xception.git
cd pytorch-deeplab-xception
- Install dependencies:
pip install matplotlib pillow tensorboardX tqdm
- 然和修改模型相关参数,引入自己的数据集
3.1 修改mypath.py
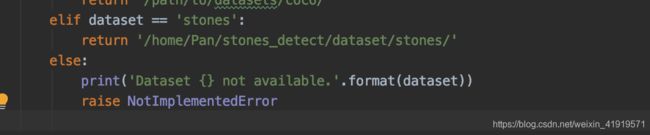
3.2 添加dataloaders/datasets/stones.py。基本参考pascal.py做修改
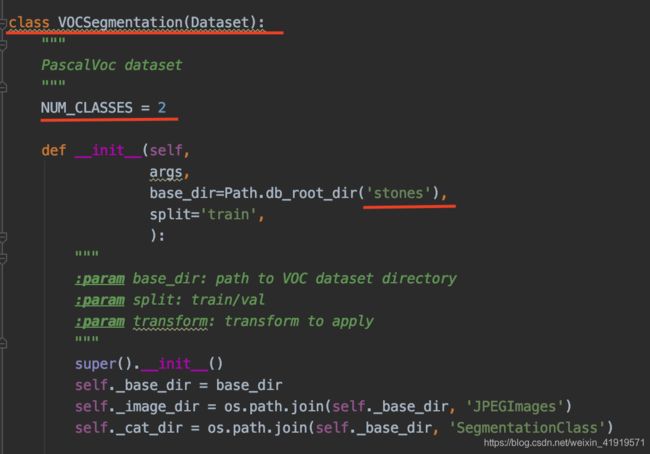
3.3 修改dataloaders/utils.py。修改utils.py文件中的decode_segmap函数,添加自己的数据集和类别信息;同时增加def get_sealand_labels()函数,用于给mask图着色

3.4 修改dataloaders/init.py。添加stones数据集的描述部分。

五、网络训练
python train.py --backbone mobilenet --dataset stones --lr 0.007 --workers 1 --epochs 50 --batch-size 8 --gpu-ids 0 --checkname deeplab-mobilenet
六、模型测试
这里引用前辈博文中写的demo进行测试
python demo.py --in-path /home/pan/Pan/pytorch-deeplab-xception/dataloaders/datasets/test_image --ckpt /home/pan/Pan/pytorch-deeplab-xception/run/stones/deeplab-mobilenet/experiment_10/checkpoint.pth.tar --backbone mobilenet
demo.py
import argparse
import os
import numpy as np
import time
from modeling.deeplab import *
from dataloaders import custom_transforms as tr
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from torchvision.utils import make_grid, save_image
def main():
parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
parser.add_argument('--in-path', type=str, required=True, help='image to test')
# parser.add_argument('--out-path', type=str, required=True, help='mask image to save')
parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
parser.add_argument('--ckpt', type=str, default='deeplab-resnet.pth',
help='saved model')
parser.add_argument('--out-stride', type=int, default=16,
help='network output stride (default: 8)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--gpu-ids', type=str, default='0',
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','invoice'],
help='dataset name (default: pascal)')
parser.add_argument('--crop-size', type=int, default=513,
help='crop image size')
parser.add_argument('--num_classes', type=int, default=2,
help='crop image size')
parser.add_argument('--sync-bn', type=bool, default=None,
help='whether to use sync bn (default: auto)')
parser.add_argument('--freeze-bn', type=bool, default=False,
help='whether to freeze bn parameters (default: False)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn)
ckpt = torch.load(args.ckpt, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}".format(model_load_time))
composed_transforms = transforms.Compose([
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
for name in os.listdir(args.in_path):
s_time = time.time()
image = Image.open(args.in_path+"/"+name).convert('RGB')
# image = Image.open(args.in_path).convert('RGB')
target = Image.open(args.in_path+"/"+name).convert('L')
sample = {
'image': image, 'label': target}
tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
model.eval()
if args.cuda:
tensor_in = tensor_in.cuda()
with torch.no_grad():
output = model(tensor_in)
grid_image = make_grid(decode_seg_map_sequence(torch.max(output[:3], 1)[1].detach().cpu().numpy()),
3, normalize=False, range=(0, 255))
save_image(grid_image,args.in_path+"/"+"{}_mask.png".format(name[0:-4]))
u_time = time.time()
img_time = u_time-s_time
print("image:{} time: {} ".format(name,img_time))
# save_image(grid_image, args.out_path)
# print("type(grid) is: ", type(grid_image))
# print("grid_image.shape is: ", grid_image.shape)
print("image save in in_path.")
if __name__ == "__main__":
main()
# python demo.py --in-path your_file --out-path your_dst_file