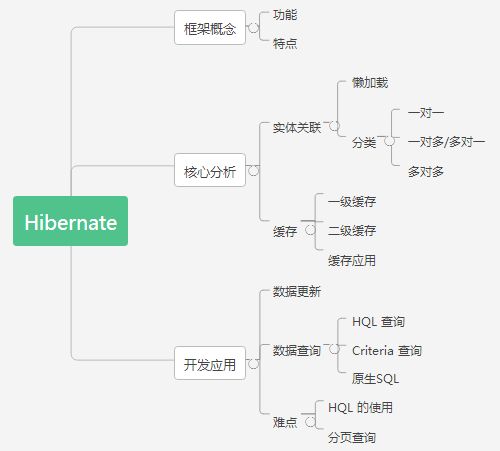
一、 Hibernate 说明
1. Hibernate 功能
(1)Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架。
(2)hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
(3)Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用。
2. HIbernate 优势
(1)对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
(3)Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
(4)hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
(5)hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
二.、 核心原理分析
1. 运行原理
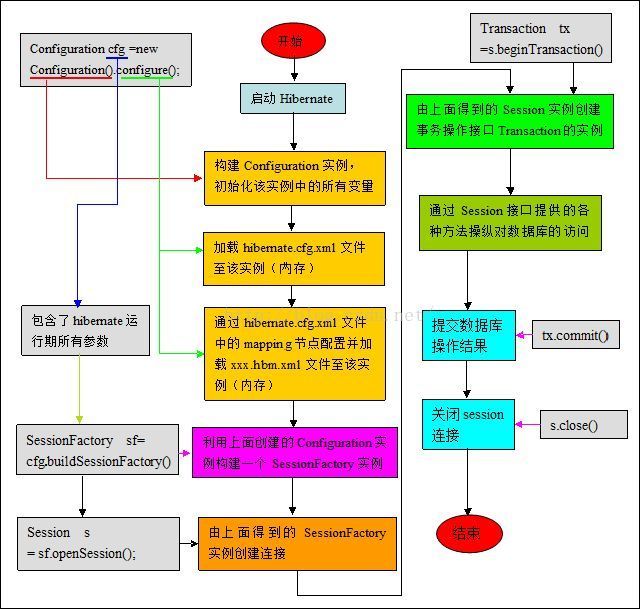
(1)通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
(2)由hibernate.cfg.xml中的读取并解析映射信息
(3)通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
(4)Session session = sf.openSession();//打开Sesssion
(5)Transaction tx = session.beginTransaction();//创建并启动事务Transation
(6)persistent operate操作数据,持久化操作
(7)tx.commit();//提交事务
(8)关闭Session
(9)关闭SesstionFactory
2. 对象状态
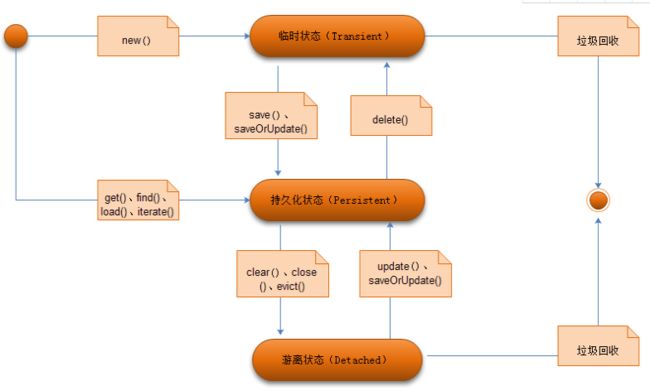
2.1 转化示意
2.2 转化描述
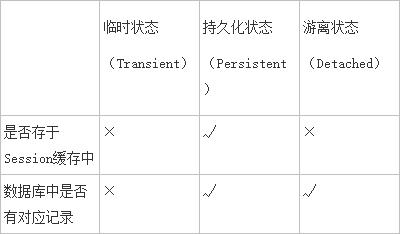
(1)临时状态(Transient):在通过new关键字,实例化一个对象开始,该对象就进入了临时状态,但它还没有被持久化,没有保存在Session当中。
(2)持久化状态(Persistent):对象被加入到Session缓存当中,如通过session.save(entity),Hibernate把实体保存到seesion当中,entity就处在持久化状态中。
(3)游离状态(Detached):对象脱离了session缓存,如通过session清理,将对象保存到数据库中,原来在session中的对象仍然与内存中,该对象就处于游离状态。
3. 核心接口
(1)session:负责被持久化对象CRUD操作
(2)sessionFactory:负责初始化hibernate,创建session对象
(3)configuration:负责配置并启动hibernate,创建SessionFactory
(4)Transaction:负责事物相关的操作
(5)Query和Criteria接口:负责执行各种数据库查询
4. 缓存
4.1 缓存作用
(1)Hibernate是一个持久层框架,经常访问物理数据库,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。
(2)缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
4.2 缓存 分类
(1)Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存。
(2)Hibernate一级缓存又称为“Session的缓存”,它是内置的,只要你使用hibernate就必须使用session缓存。由于Session对象的生命周期通常对应一个数据库事务或者一个应用事务,因此它的缓存是事务范围的缓存。在第一级缓存中,持久化类的每个实例都具有唯一的OID。
(3)Hibernate二级缓存又称为“SessionFactory的缓存”,由于SessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。第二级缓存是可选的,是一个可配置的插件,在默认情况下,SessionFactory不会启用这个插件。
4.3 二级缓存
(1) 适合使用
1)很少被修改的数据
2)不是很重要的数据,允许出现偶尔并发的数据
3)不会被并发访问的数据
4)常量数据
(2) 不适合使用
1)经常被修改的数据
2)绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发
3)与其他应用共享的数据。
三、 开发应用
1. 实体关系
1.1 一对一
(1)数据库设计
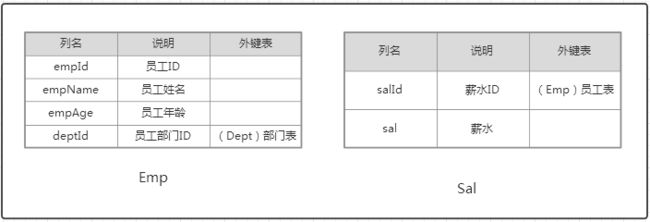
(2)数据实体
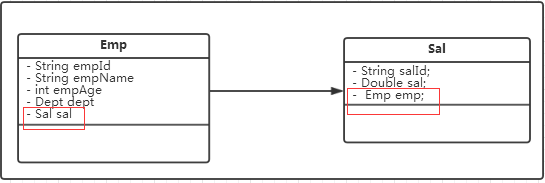
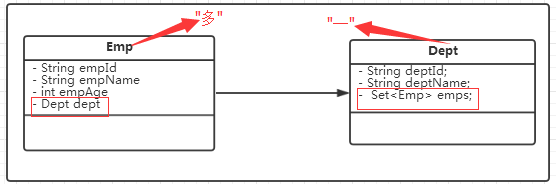
1.2 一对多(多对一)
(1)数据库设计

(2)数据实体
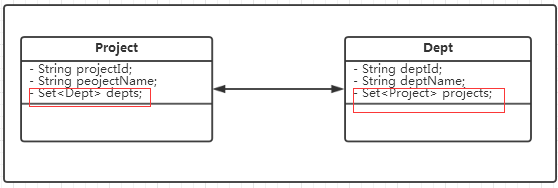
1.3 多对多
(1) 数据库设计
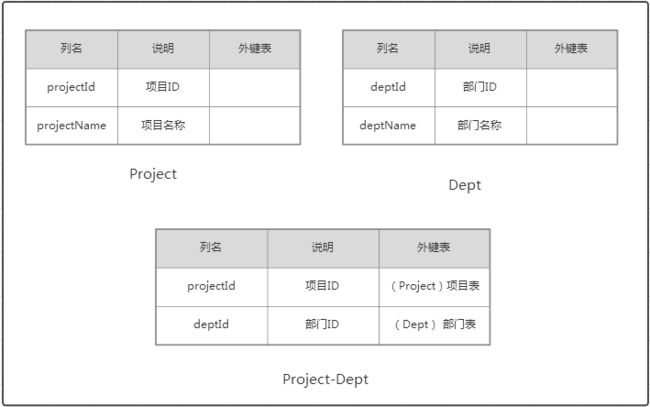
(2) 数据实体
2. 懒加载

2.1 get 方法
对于Hibernate get方法,Hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据 库中没有就返回null。
2.2 load 方法
Hibernate load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
(2)若为false,就跟Hibernate get方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
2.3 get 和 load 对比
(1) 如果未能发现符合条件的记录,Hibernate get方法返回null,而load方法会抛出一个ObjectNotFoundException。
(2)load方法可返回没有加载实体数据的代 理类实例,而get方法永远返回有实体数据的对象。
(3)总之对于get和load的根本区别,hibernate对于 load方法认为该数据在数据库中一定存在,可以放心的使用代理来延迟加载,如果在使用过程中发现了问题,只能抛异常;而对于get方 法,hibernate一定要获取到真实的数据,否则返回null。
3. 数据更新
(1) 数据保存
Session.save()方法用于实体对象的持久化保存,也就是说当执行session.save()方法时会生成对应的insert SQL语句,完成数据的保存。
当执行到session.save()方法时,Hibernate并不会马上生成insert SQL语句来进行数据的保存,而是当稍后清理session的缓存时才有可能执行insert SQL语句
(2) 数据更新
session.update()方法能够将一个处于游离状态的对象,重新纳入Hibernate的内部缓存,变成持久化对象。
(3) 数据删除
delete()方法用于从数据库中删除一个或一批实体所对应的数据,如果传入的对象是持久化对象,当清理缓存时,就会执行delete操作。如果传入的是游离对象,那么首先会使该对象与session相关联,然后当清理缓存时,再执行delete操作。
4. 数据查询
4.1 HQL(Hibernate Query Language) 查询
(1)提供了是十分强大的功能,它是针对持久化对象,用取得对象,不进行update,delete和insert等操作。
(2)HQL是面向对象的,具备继承,多态和关联等特性。
(3) 通过会话对象 session 对象创建对象, 具体操作 session.createQuery(HQL)。
(4) 在HQL语句中支持 from子句、select子句、where子句 、模糊查询、 统计函数、链接查询等常见操作方式,值得注意的是 使用 from 子句 的形式会默认查询所有的属性。
4.2 Criteria(Criteria Query) 查询
(1)当查询数据时,往往需要设置查询条件。在SQL或HQL语句中,查询条件常常放在where子句中。使用次方法的就是不用再写SQL语句。
(2) 常见的使用方法如下:

(3)在实际开发中所见不多,一般的使用流程以如下方式实现:

4.3 原生SQL(Native SQL)查询
(1)本地SQL查询指的是直接使用本地数据库的SQL语言进行查询。这样做对于将 原来的SQL/JDBC程序迁移到Hibernate应用很有用。
(2)通过SQLQuery接口来控制的,它通过调用Session.createSQLQuery()方法来获得。
4.4 命名SQL(Native SQL)查询
将执行的SQL语句在对应的配置文件然后通过直接调用即可(但开发中未见使用)。
5. 操作难点
(1) 唯一值获取
调用Session的createQuery方法创建查询 Query 对象;
由 Query 对象调用 uniqueResult() 获取唯一值;
(2) 分页查询
调用Session的createQuery方法创建查询 Query 对象;
由 Query 对象调用 setFirstResult(intfirstResult) 方法 ,设置返回的结果集从第几条记录开始;
由 Query 对象调用 setMaxResults(intmaxResults) 方法,设置本次查询返回的结果数。
(3) 聚合函数
不要使用count(*) 要count(包名.持久化对象)
四、 Hibernate 知识点