仅供学习必要的都打码处理了!!!
0x01前言
漆黑的房间只有闪烁的电脑灯光,小明独守空房寂寞难耐。只见他注视着电脑屏幕默默掏出了纸巾,擤了一下鼻涕。定睛一看原来是不停的敲打着代码。
言归正传,开始今天的爬虫之路。
Today无意中打开了一个有意思的小网站,里面有一群敬业的小姐姐,即便是衣衫褴褛、寸无遮拦也要坚持自己的表演。为了这群敬业的小姐姐,决定安排一下。
0x02爬虫环境
Python3.7使用到库requests、json、re、bs4 、http.cookiejar
0x03模拟登陆并记录cookie
我们要模拟用户登陆首先要知道怎么和服务器“沟通”的,给服务器说了什么才能让他放我进去。我喜欢用burpsuite抓包,当然也可以用浏览器的开发者选项查看交互过程。
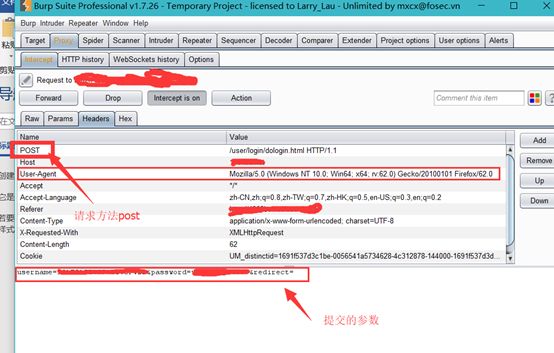
从抓的包上来看,登陆采用POST方法,传入的参数也只有username与password以及一个redirect空值。这就简单了直接使用requests.post就行。登陆后我们可以记录下cookie的值,下次登陆直接调用cookie就行。
def login():
Session = requests.session() #定义Session,下面就用Session代替requests
#因为原始的session.cookies没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,
#这个类实例化的cookie对象,就可以直接调用save方法。
Session.cookies =cookielib.LWPCookieJar(filename = "Cookies.txt") #保存cookie
posturl='这里是登陆post的url'
header = {'User-Agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64; rv:62.0)',
'Referer': '抓包可见'}
postdata = {
'username' : '用户名',
'password' : '密码',
'redirect' : ''
}
try:
print('123')
r = Session.post(url=posturl,data=postdata,headers=header)
print(f"statusCode ={r.status_code}")
print(f"text = {r.text}")
Session.cookies.save()
except Exception as e:
print('[-] info : login fail, pleasetry again ')
exit()
0x04 爬取分页链接
登陆之后发现首页有十五个不同小姐姐,这就说明有十五个链接可以进去。我们先提取出每一页中的链接。
首先还是查看采用的方法,开发者工具“网络“,查看方法。
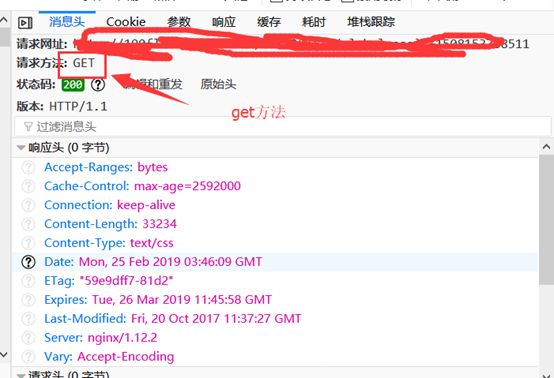
所以用到的核心代码是:r = requests.get(url=url+str(pageNumber),headers=headers)
打开开发者工具,查看代码。

发现每张图片都对应有以上标记的标签,我们直接使用beautifulSoup提取标签里的内容。使用的是a标签,但是a标签很多我们还有匹配class="fly-case-img"才能提取到后面href中的内容。所以核心代码就是:
soup.find_all("a",class_="fly-case-img")[0:]。
匹配之后就是提取herf中的url。整体代码如下:
url = 'http://*******.net/?page=' #每一个分页的url格式
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0)',
'Referer': 'http://**********/user/login/'}
r =
requests.get(url=url+str(pageNumber),headers=headers)
r.encoding = 'utf-8'
soup =BeautifulSoup(r.text,'lxml')
info =soup.find_all("a", class_="fly-case-img")[0:]#提取想要的部分
#print(info)
for tag in info:#提取href中的url
name = tag['href']
print(name)
0x05 提取每个链接中的下载地址
由于前面提取的url之后主站后的链接,所以在之前要先补全url。
并get补全后的地址.
url = 'http://$#@.net'
page = Session.get(url=url+str(name)+'.html',headers=headers)
page.encoding = 'utf-8'
一样的用soup过滤标签,打开源代码查看对应下载地址的标签。

由图可以看到该下载链接存在与一个a标签中,但是整个网页的a标签很多,但是内容存在’mp4’就就这一个a标签,所以可以构造核心代码:
page =Session.get(url=url+str(name)+'.html',headers=headers)
page.encoding = 'utf-8'
soup =BeautifulSoup(page.text,'lxml')
infos =soup.find_all("a",href=re.compile("mp4"))[0:]
fortag in infos:
names = tag['href']
print(names)
在这里遇到了一个小小的坑,提取的url地址下载出来没东西,这就很尴尬,裤子都脱了。接着我就访问了一下链接。

TMD分两个下载节点,打开源码看看

发现爬取的下载链接少一个“1“和“2“,原来就http://d.。。。“,真实的下载地址为http://d1.简单就在原来的链接中加上1。我采用的是字符串拼接。代码如下:
for tag in infos:
names= tag['href'][31:]
print(names)
withopen('url_heji.txt','a+') as f:
f.write('http://d1.********.top/uploads/mp4/'+names+'\n')
0x06 zip文件下载地址提取
网站中除了MP4外还有一种压缩包文件的下载地址。
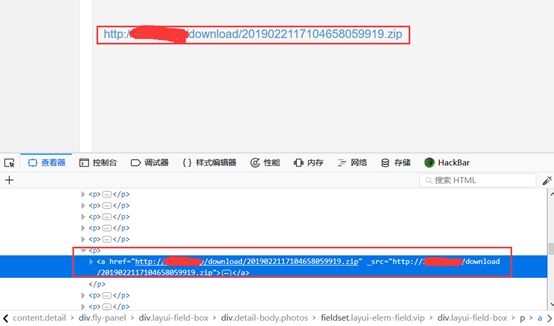
采用同样的方法匹配a标签,再匹配href中的“download”;核心代码如下:
infoss =soup.find_all("a",href=re.compile("download"))[0:]
#print(infos)
#num =re.search('_src.*href',infos).group()[:-1]
for tag in infoss:
namess = tag['href']
print(namess)
withopen('url_heji.txt','a+') as f:
f.write(namess+'\n')
0x07 结果展示


不行了营养更不上了!!
附录:汇总代码
# coding: utf-8
import os
import requests
import json
import re
from bs4 import BeautifulSoup
import http.cookiejar as cookielib
def login():
Session = requests.session()
#因为原始的session.cookies 没有save()方法,所以需要用到cookielib中的方法LWPCookieJar,
#这个类实例化的cookie对象,就可以直接调用save方法。
Session.cookies = cookielib.LWPCookieJar(filename ="Cookies.txt")
posturl='http://****.net/user/login/dologin.html'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64;rv:62.0)',
'Referer': 'http://****.net/user/login/'}
postdata = {
'username' : '用户名',
'password': '密码',
'redirect': ''
}
try:
print('123')
r= Session.post(url=posturl,data=postdata,headers=header)
print(f"statusCode = {r.status_code}")
print(f"text = {r.text}")
Session.cookies.save()
except Exception as e:
print('[-] info : login fail, please try again ')
exit()
def url():
Session.cookies.load()
try:
for pageNumber in range(1,200):
print('目前已经爬取到第'+str(pageNumber)+'页'+'\n')
#Session.cookies.load()
url = 'http://****.net/?page='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0)',
'Referer': 'http://****.net/user/login/'}
r =requests.get(url=url+str(pageNumber),headers=headers)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'lxml')
info = soup.find_all("a",class_="fly-case-img")[0:]
#print(info)
for tag in info:
name = tag['href']
print(name)
url = 'http://****.net'
page =Session.get(url=url+str(name)+'.html',headers=headers)
page.encoding = 'utf-8'
soup =BeautifulSoup(page.text,'lxml')
infos =soup.find_all("a",href=re.compile("mp4"))[0:]
#print(infos)
#num =re.search('_src.*href',infos).group()[:-1]
for tag in infos:
names = tag['href'][31:]
print(names)
withopen('url_heji.txt','a+') as f:
f.write('http://d1.****.top/uploads/mp4/'+names+'\n')
infoss =soup.find_all("a",href=re.compile("download"))[0:]
#print(infos)
#num =re.search('_src.*href',infos).group()[:-1]
for tag in infoss:
namess = tag['href']
print(namess)
withopen('url_heji.txt','a+') as f:
f.write(namess+'\n')
except Exception:
print('可能遇一些问题,脚本即将推出运行')
print('目前已经爬取到第'+str(pageNumber)+'页,下次可从这里继续开始')
sys.exit()
if __name__ == '__main__':
#login()
url()
#palianjie()