基于jdk1.7进行源码阅读
1.chm的类图
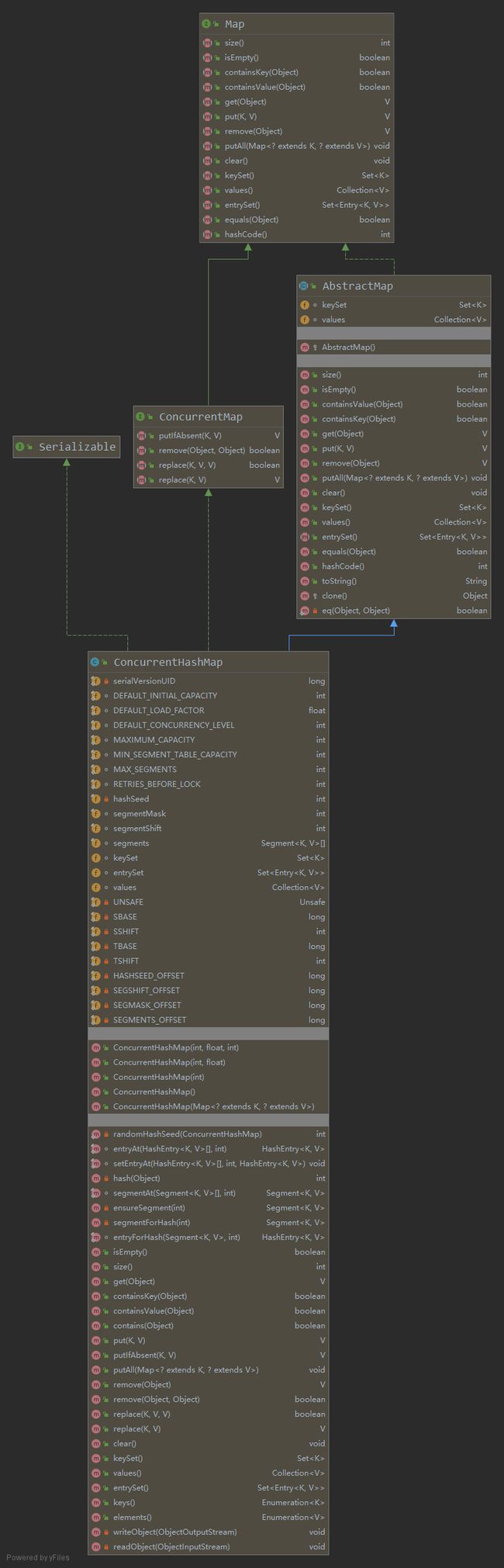
chm的类图.png
2.chm的属性和构造方法

chm的属性.jpg
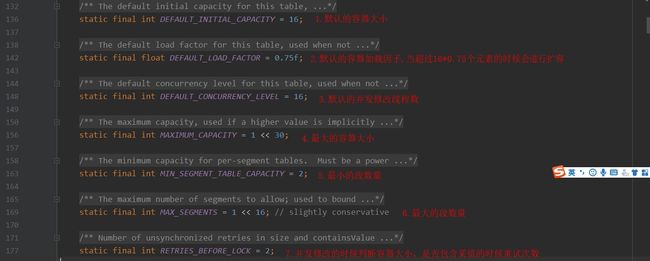
chm的属性 (2).jpg
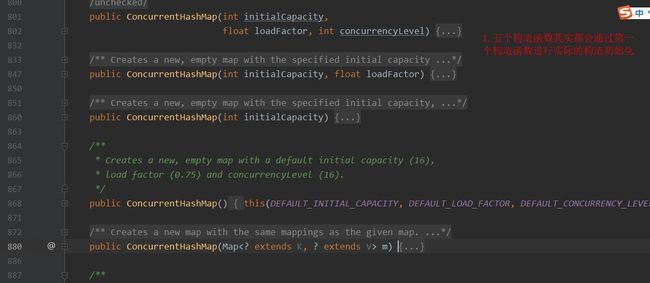
chm的构造函数.jpg
/**
* Creates a new, empty map with the specified initial
* capacity, load factor and concurrency level.
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements.
* @param loadFactor the load factor threshold, used to control resizing.
* Resizing may be performed when the average number of elements per
* bin exceeds this threshold.
* @param concurrencyLevel the estimated number of concurrently
* updating threads. The implementation performs internal sizing
* to try to accommodate this many threads.
* @throws IllegalArgumentException if the initial capacity is
* negative or the load factor or concurrencyLevel are
* nonpositive.
*/
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//进行参数校验
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
//while循环找到比当前concurrencyLevel并发级别大的最小的2的n次方,这里如果默认的话其实
//ssize == concurrencyLevel == 16
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift; //默认情况下计算的偏移量segmentShift是28 sshift就是ssize以2的n次方扩容的n(sshift==n)
this.segmentMask = ssize - 1; //默认情况下计算的段大小是16 segmentMask默认为15
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
//这里的cap指的是每个段中的hash数组的容量大小,通过段的大小ssize进行容量评估,
//类似于分页,ssize就是每页大小,如ssize=16,initialCapacity=50的时候c=4,cap=4;initialCapacity=100,c=7,cap=8
// create segments and segments[0]
//下面先初始化一个Segment段,默认情况下cap * loadFactor = 2 * 0.75 = 1.5取整为1
//注意看最后一个参数(HashEntry[])new HashEntry[cap],在初始化段的时候也就初始化了hash数组
//这里如果使用默认值的话,其实是有16个段,每个段里面hash数组的大小是2
Segment s0 =
new Segment(loadFactor, (int)(cap * loadFactor),
(HashEntry[])new HashEntry[cap]);
//根据计算出的段长度声明一个段数组
Segment[] ss = (Segment[])new Segment[ssize];
//这里使用UNSAFE的API对ss进行数组的赋值
//SBASE是Segment类在内存中的地址相对于实例对象内存地址的偏移量,这里涉及到通过UNSAFE操作内存数据不做过多说明
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
//将声明的ss 段数组进行赋值,此时就完成了整个ConcurrentHashMap基于段的初始化过程
this.segments = ss;
//这里总结一下,对chm进行抽象看的话其实1.7的chm就是一个二维数组,里面的元素就是hash链表,如果把hash链表看成数组的话,
//其实它就是一个三维数组
}
3.Segment类讲解
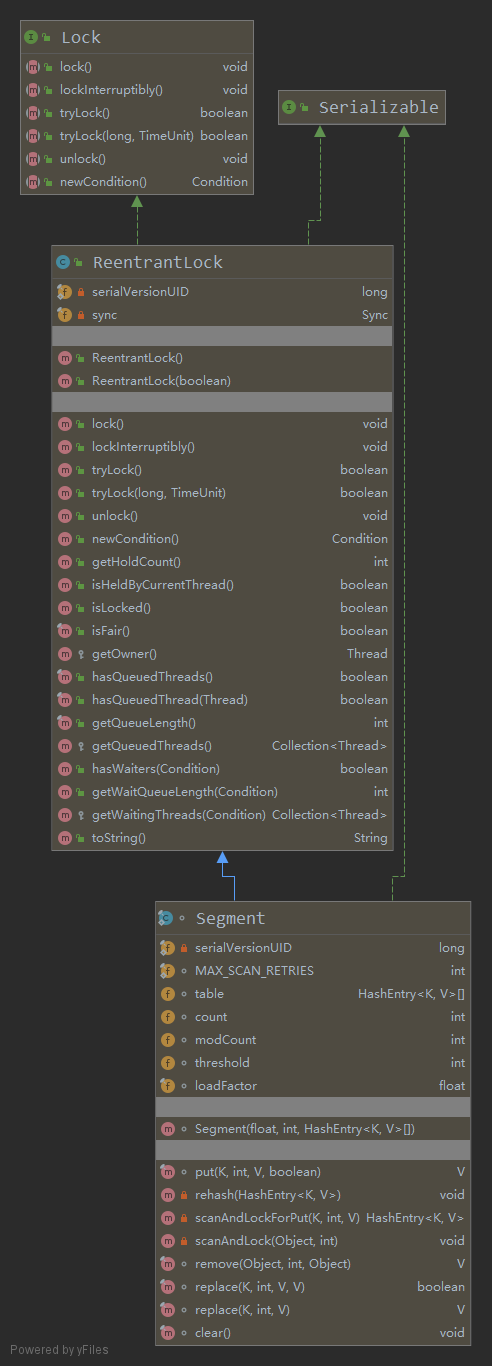
Segment类图.png

segmengt属性.jpg
3.1HashEntry数据结构说明
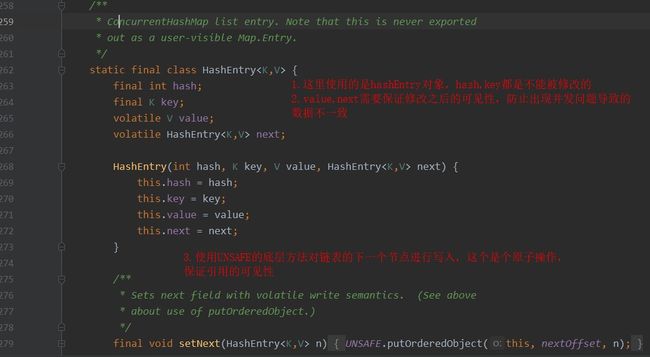
hashentry数据结构.jpg
3.2put/get操作需要依赖的核心方法

putget操作.jpg
4.put操作过程详解
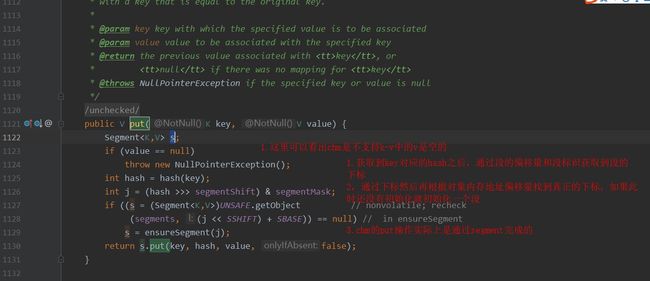
put操作.jpg

hash值计算.jpg
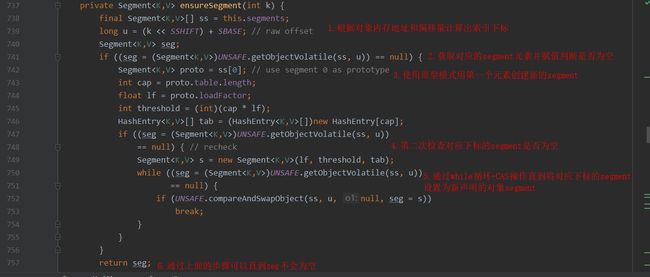
创建segment并初始化到chm的segment数组中.jpg
4.1Segment类中的put操作详解
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//首先尝试上锁,如果成功则往下走,否则通过key,hash找到对应的段并上锁返回初始化的hash entry,下面就不用上锁了直接put
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
//通过hash计算出对应段下的hash entry数组下标
//返回头结点
HashEntry first = entryAt(tab, index);
//
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
//找到并允许覆盖
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
//跳出循环
break;
}
e = e.next;
}
else {
//如果上面的if没有找到同时新节点已经初始化
//则将新建结点加入头结点,旧的头结点作为后续结点
if (node != null)
node.setNext(first);
else
//重新初始化,并将旧的头结点作为后续结点
node = new HashEntry(hash, key, value, first);
int c = count + 1;
//如果当前容量已经大于阈值则进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
//否则将新建节点加入到hash数组中
setEntryAt(tab, index, node);
++modCount;
count = c;
//这里好像没啥用
oldValue = null;
//跳出循环
break;
}
}
} finally {
//释放锁
unlock();
}
//返回旧的值
return oldValue;
}
4.2扫描尝试加锁
/**
* Scans for a node containing given key while trying to
* acquire lock, creating and returning one if not found. Upon
* return, guarantees that lock is held. UNlike in most
* methods, calls to method equals are not screened: Since
* traversal speed doesn't matter, we might as well help warm
* up the associated code and accesses as well.
*
* @return a new node if key not found, else null
*/
private HashEntry scanAndLockForPut(K key, int hash, V value) {
//通过当前segment段与hash值找到对应的hash数组头结点
HashEntry first = entryForHash(this, hash);
HashEntry e = first;
HashEntry node = null;
//定义一个重试的标志位
int retries = -1; // negative while locating node
//如果上锁失败就一直循环
while (!tryLock()) {
HashEntry f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
//如果上锁失败且超过最大重试次数64则直接使用非公平锁策略抢执行权限并返回
//如果走到这一步说明并发写的线程非常多存在严重的竞争
lock();
break;
}
//这里由于上锁失败其他线程可能已经修改了数据了,需要重新遍历
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
4.3rehash操作
/**
* Doubles size of table and repacks entries, also adding the
* given node to new table
*/
@SuppressWarnings("unchecked")
private void rehash(HashEntry node) {
/*
* Reclassify nodes in each list to new table. Because we
* are using power-of-two expansion, the elements from
* each bin must either stay at same index, or move with a
* power of two offset. We eliminate unnecessary node
* creation by catching cases where old nodes can be
* reused because their next fields won't change.
* Statistically, at the default threshold, only about
* one-sixth of them need cloning when a table
* doubles. The nodes they replace will be garbage
* collectable as soon as they are no longer referenced by
* any reader thread that may be in the midst of
* concurrently traversing table. Entry accesses use plain
* array indexing because they are followed by volatile
* table write.
*/
//将当前segment下的hash数组赋值给数组变量oldTable
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
//扩容一倍
int newCapacity = oldCapacity << 1;
//重新计算扩容阈值
threshold = (int)(newCapacity * loadFactor);
//声明新的数组
HashEntry[] newTable =
(HashEntry[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
//for循环进行数据复制到新的数组中
for (int i = 0; i < oldCapacity ; i++) {
HashEntry e = oldTable[i];
if (e != null) {
HashEntry next = e.next;
//根据元素hash值和数组大小标识重新计算属于哪一个数组
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
//没有元素则插入头结点
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry lastRun = e;
int lastIdx = idx;
for (HashEntry last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
//进行hash冲突检查,如果找到有一个不等于当前链表的索引下标就先占用
//这里的作用是如果存在很多冲突的话将冲突的数据分散到数组的其他位置中
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
//这里不管怎么样lastIdx的这个数组位置肯定是空的,但是lastRun这个能是上个数组中的一部分链表元素
newTable[lastIdx] = lastRun;
// Clone remaining nodes
//将上个数组中的其他链表元素复制到新的数组中
for (HashEntry p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry n = newTable[k];
newTable[k] = new HashEntry(h, p.key, v, n);
}
}
}
}
//将新的node数据与新数组进行关联然后设置到当前segment的table属性中,
//此时就完成了当前这个segment下的整个hash数组的扩容
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
5.替换和元素清除方法说明
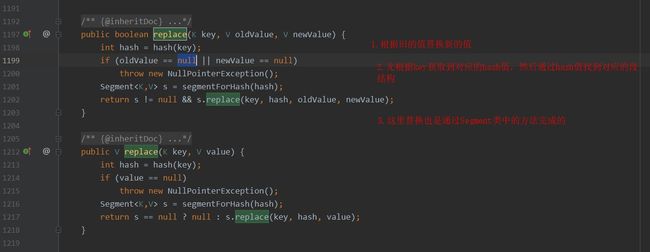
元素替换.jpg
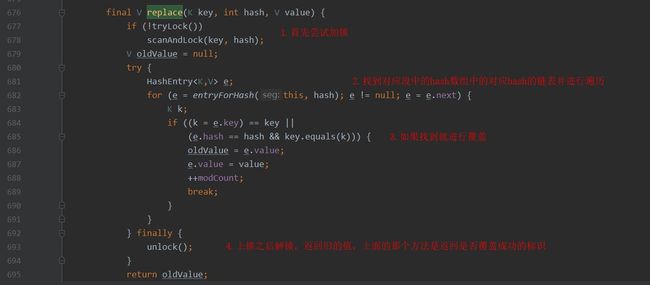
替换实现0.jpg

元素清除.jpg
总结
- 基于jdk1.7实现的ConcurrentHashMap(chm)的数据结构就是Segment数组+HashEntry数组+HashEntry链表,数组中的元素是是entry链表的头结点.
- ConcurrentHashMap的key-value都不可以为空
- ConcurrentHashMap的put/get/replace/clear都是通过Segment实现的且通过Lock机制进行显示的加锁
- ConcurrentHashMap扩容的时候是在put方法进行扩容的,由于扩容过程中已通过put方法进行加锁了,所以不存在并发问题导致的数据错乱和死链问题.
- ConcurrentHashMap中的核心类就是HashEntry(代表核心数据结构)+Segment(代表锁)
- 1.7版本ConcurrentHashMap的源码总体比HashMap稍微复杂点,大概1600行,这里选取比较核心的方法和常用操作进行源码分析。
- 相关链接http://ddrv.cn/a/282926
- 相关链接https://www.cnblogs.com/williamjie/p/9099861.html
- 相关链接https://www.cnblogs.com/heqiyoujing/p/10928423.html