从零开始,带你用Nanodet目标检测模型完成自动捡球机器人
文章目录
- 前言
- 机械结构
- 电控设计思路
- 视觉思路
-
- 小球的目标检测
-
- 传统方法OR深度学习
- Nanodet目标检测算法训练与部署
-
- 1.手动创建数据集
- 2.数据标注
- 3.数据增强
- 4.xml转json
- 5.配置config文件
- 6.训练模型
- 7.检测模型效果
- 8.转换pth文件为onnx文件
- 9.转换ONNX文件为IR模型(xml和bin)
- 10.在Qt上用C++ 和 opencv部署Nanodet模型
- 11.目标检测效果
- 路径规划算法
-
- 1.路径规划状态机
- 2.选择最佳方向和前进距离
-
- 2.1思路一、遍历每个小球看哪个小球周围的球的个数最多
- 2.2思路二、基于DBSCAN的小球数量-距离权重聚类算法
- 2.3思路三、基于方向的小球数据-距离权重算法
- 总结
前言
- 本项目涉及到的所有代码见github:项目代码
- 一些叽里呱啦的碎碎念:
说来惭愧,自上一次更新博客以来已经有半年多没更新了,中间其实积累了几个项目想要分享的,可惜太懒,日后慢慢补上吧。
这次想要分享的是刚刚结束不久的大创项目,这个令我又爱又恨的项目,值得来记录一下。
2020年5月27号那天,跟组员胡编乱造乱开脑洞地写了个大创项目申请书,谁知道整个实验室只有我们进省赛了,本来完全想水过去的项目,随着时间慢慢逼近又不得不做,记得中期答辩的时候我们拿着一个随意到不能再随意的ppt被评委怼得无话可说,就觉得肯定是做不出来的,看看后面能不能放弃吧。
当后面得知省赛队伍不可以放弃的时候,整个人都是绝望的,因为申请书上面写的强化学习,深度学习对我来说有点天花乱坠,更何况考研才是当前的主线。
时间来到一个月前,看到我的队友们已经把车子都造出来了,觉得我也应该花点时间来弄一下了,不然也浪费了队友这么大的功夫。
谁知道弄着弄着,在最后十天的时候,阴差阳错地弄出了一个模型,然后顺理成章地结合到了机器人上面,最后答辩还拿了个为数不多的优秀,现在想想那种体验就amazing。
在考研期间花十天时间弄这么一个项目,值也不值,值的是确实有点意思,也做出了点东西,跟以前的队友一起合作的感觉也很难得,跟实验室的小伙伴一起讨论着有意思的技术问题也很有趣,大家一起通宵调车到五点累了就躺下睡着,看到最后小车能够完成预期的效果也开心到不行;不值的是考研的朋友在这段时间已经在高数上面远超我的进度,而我最近却丢失了那种先在脑子里算出答案再落笔写过程的感觉,英语单词也前功尽弃只能从头开始。怎么说呢?既然都这样了那就好好结束这个项目,然后好好地准备考研,也算是给自己一个交代吧。
- 好了,说了那么多屁话,来介绍一下这个项目是什么东西。
- 项目名字叫做《多场景下的球体回收分类机器人》,简单理解就是做一个机器人,这个机器人能够通过自带的摄像头来动态规划当前的最优捡球路径进而完成自动捡球和自动避障,同时也可以在各种场景下同时检测多种球体,通过机械结构自动将大小球进行分类。
- 要完成上面所说的东西,单凭我一个人显然是不够的,但是我有超级厉害的队友,各自负责不同的部分,最后再合成这台机器人。
- 我们将项目分成三大部分,分别为机械,电控,视觉,由于我主要负责的是视觉部分,因此本文主要介绍的也是该部分,但为了让大家更加了解整个机器人的运作流程,下面先让我简单介绍一下其他两部分。
机械结构
-
强力队友毓正哥主要负责设计机械结构,将整台机器人组装起来,同时该机械机构可以根据重力筛自动将大小球进行分离。下面是整体的效果,整体机械结构由两部分组成,第一部分是前面的旋转扫板,另一部分是后面的收集滤板以及收集仓。
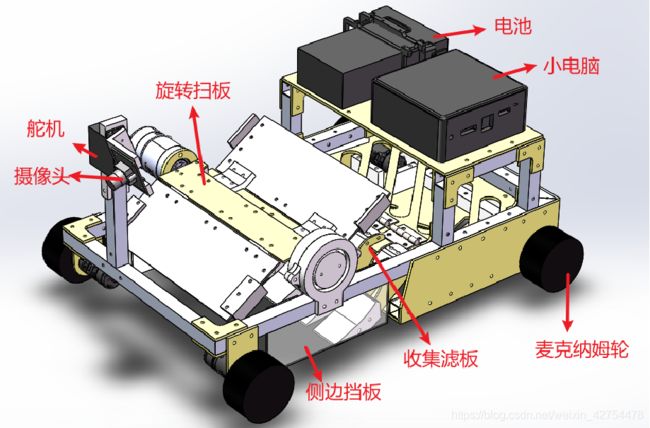
-
大小球在前部旋转扫板的推动下被扫上后部的收集滤板。滤板的滤孔可将大小球进行上下分离。
-
当需要分类的大小球尺寸不同时,我们可以通过更换不同滤孔大小的滤板来实现大小球分离。
-
而当仅收集一种球类时,我们可以将滤板拆除,使收集到的球类全部落入收集仓中。
-
下面是整个机器人的运作视频。
电控设计思路
- 男神马哥则负责电路部分的设计,让机器人能够动起来。下面简单说一下视觉算法得到的决策数据是怎么控制机器人动起来的。
- 机器人分为手动遥控跟自动控制两个模式。显然要实现自动控制,则需要我这边的算法做路径规划然后告诉机器人怎么动(转多少度和向前走多少米)。
- 该部分需要注意的点有几个:
- 1.视觉这边的处理速度(大约是100ms)是要慢于机器人更新信息的速度的,但是我们可以沟通好两边传输数据的规则,电控那边每50ms发送一下它那边的情况。同时我们约定好我这边发送数据的有两个,分别表示当前情况机器人最优的旋转方向和前进距离。而电控方发送给我的数据主要是前一个决策动作做完没有,如果做完了,我这边就做一次新的决策并且发送新的数据,如果没做完,我这边就可以发送前一次的数据,防止前一次发送的数据中途丢失。
- 2.具体的数据传输则需要借助串口通信来完成,可以理解为是tcp中的端口连接通信。我们可以将数据发送到串口,而电控方可以通过串口接受数据。
- 传输流程图如下:

- 执行流程图如下:

- 执行流程图如下:
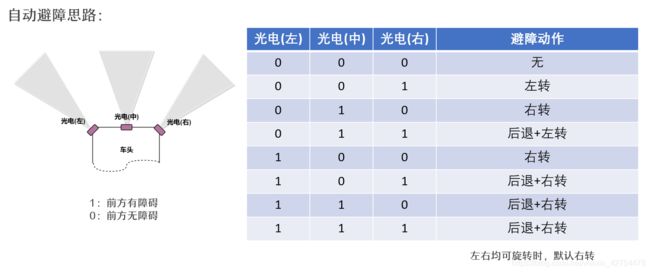
- 申请书中提到了自动避障,但是从视觉方面实现避障功能感觉需要用到激光雷达等高端的东西,在短期内很难做出来,能力也有限,故可通过避障模块进行检测来实现该功能。细节如下:
- 机器人的前方布置了三个光电开关(通过激光检测前方某个距离内是否有障碍物),形成了八种状态,对于每种状态我们采用不同的避障动作即可。
- 下面为整体流程图和效果视频:
视觉思路
- 终于到了本文的主要内容了,视觉部分主要的目标有两个,对小球做目标检测,对小车做路径规划。下面一个个来说。
小球的目标检测
传统方法OR深度学习
-
实际上,刚开始思考的时候是想着能不能用传统的视觉方法来做,因为自己对深度学习这一块确实不熟悉,而且深度学习往往比较慢,不能满足实时的路径规划。
-
但是在思考过后,发现传统的方法有下面的缺点:

-
因此硬是要用传统方法做是做不出来的。于是思考目标检测算法。
-
最主流也最先想到的当然是Yolo-V4算法,毕竟实验室也有朋友之前用过,可以请教一下,于是就先试一试,效果如下图,可见整体来说其准确率还是非常高的,但是却有一个致命的缺点,在我们的电脑上处理一张图片需要30秒,这意味着我们的机器人每做一个动作要等30秒才能做另一个动作,显然不可行。(考虑过神经网络棒加速,但加速后依然满足不了实时的需求)。

Nanodet目标检测算法训练与部署
- 一次实验室的另一位朋友也在研究目标检测,提到用Nanodet模型可以达到10ms每张图片的速度,兴奋起来了!
- 在前面的方法都走不通的情况下,也只能硬着头皮试一试了。
- 然而对这个网络一无所知,也没有任何的数据集的情况下,确实难顶,于是开始了为期四天的训练模型之路。
1.手动创建数据集
- 深度学习的前提是有数据集,然而我们什么都没有,于是一天晚上我去实验室场地上面用手机拍了快一个钟,得到了近两百张小球的图片。

- 实际上还有一种获取图片的方法,就是用手机拍一个小球的视频,可以绕着小球转几圈,让手机摄像头从俯视到平视(尽可能获取多个视角),然后用下面的程序把这个视频导出很多帧图片,即可完成图片的收集。
- 使用的时候只需要修改三个参数即可。
1.DATA_DIR :视频的路径(注意如果粘贴的路径是’‘一定要改成’/‘或者’\’,否则python读取不了)
2.SAVE_DIR :图片保存的文件夹
3.GAP :每个多少帧截取一张图片 - 这里重点说一下GAP的作用,因为拍的视频中两帧之间的间隔是很短的,因此我们看起来图片其实差不多,对于深度学习来说可能前后两帧能提取到的特征都差不多,所以我们可以取10帧截取一张图片的方式,让导出的数据集尽可能不太一样,即让我们的数据集质量更高。
- 需要注意的是,拍视频的时候最好不要走得太快(手机不要晃动得太厉害),不然拍出来的视频中小球会有拖影,这对数据集的质量会降低,训练出来的效果也会下降(毕竟小车最终的视角中球是没拖影的)。
- 使用的时候只需要修改三个参数即可。
#将视频导出为若干帧图片
DATA_DIR = "E:/大三上/大创/视频素材/ball_video_1.mp4" #视频数据主目录
SAVE_DIR = "E:/大三上/大创/第二次训练图片" #帧文件保存目录
GAP = 10 #每隔多少帧导出一张图片
import cv2 #OpenCV库
import os
def getphoto(video_in, video_save):
number = 0
cap = cv2.VideoCapture(video_in) # 打开视频文件
n_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 视频的帧数
fps = cap.get(cv2.CAP_PROP_FPS) # 视频的帧率
dur = n_frames / fps # 视频的时间
num_frame = 0
judge = cap.isOpened()
while judge:
flag, frame = cap.read() # flag是读取状态,frame下一帧
if cv2.waitKey(0) == 27:
break
if flag:
num_frame += 1
if num_frame % GAP == 0:
print("正在保存第%d张照片" % number)
cv2.imwrite(video_save + '/' + str(number) + '.jpg', frame) # cv2.imwrite(‘路径’ + ‘名字’ + ‘后缀’, 要存的帧)
number += 1
else:
break
print("视频时长: %d 秒" % dur)
print("视频共有帧数: %d 保存帧数为: %d" % (n_frames, number))
print("每秒的帧数(FPS): %.1lf" % fps)
def main_1(path):
video_in = path
video_save = SAVE_DIR
getphoto(video_in, video_save)
if __name__=='__main__':
paht= DATA_DIR#视频路径
main_1(paht)
2.数据标注
- 目标检测跟图片的分类最大的不同在于其需要将每张图片进行标注,怎么说,体力活,花时间,没有捷径,就硬标。
- 因为Nanodet用的是Coco数据集,因此我们需要先从每张图片中导出一个个xml文件,再将若干个xml文件转换为json文件。
- 我采用的是labelimg软件进行标注的,怎么说呢…每一张图片都要像下面那样子进行标注,就一个下午加晚上标到直接泪目的程度。

- 标完之后就会得到若干个xml文件:

- 我们打开其中一个xml文件看看其中的格式:要是通过自瞄等方式自动生成xml则需要注意里面的字段是否有缺失或者不一样。
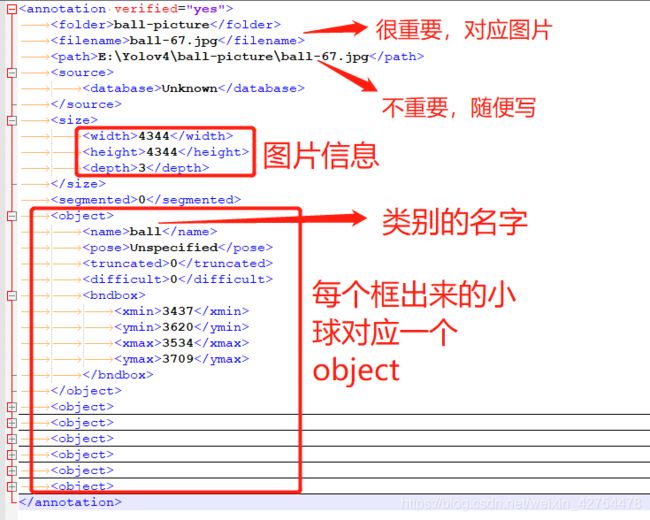
- 同时,如果我们发现想批量修改所有xml文件的某些字段,比如我们想要将类别为“small ball”或者是“big ball”改为“ball”,则可以用到下面的脚本:
- 该脚本还能删除某个类别名的框,比如我们想删掉类别名字为“middle ball”的框,即可把下面代码注释的部分加上。
- 最后还能检查xml文件中的类别是否正确,比如下面两行代码中,我们查看是否有一个框的类别名不为ball,如果有,则输出错误信息。
- 如果你的数据集是有多个类别,则把[‘ball’]改成[‘category_A’,‘category_B’,’ category_C’],表示如果有一个类别名不属于这三个名字之一,则输出错误
if not (name in ["ball"]):
print(filename + "------------->label is error--->" + name)
- 同理,该脚本还需要修改两个路径:
- 原始xml文件夹路径(origin_xml_dir)
- 新生成的xml文件路径(new_xml_dir)
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
import os
import xml.etree.ElementTree as ET
origin_xml_dir = './第二次标注/'# 设置原始标签路径为 Annos
new_xml_dir = './数据集准备/xml/'# 设置新标签路径 Annotations
for dirpaths, dirnames, filenames in os.walk(origin_xml_dir): # os.walk游走遍历目录名
for filename in filenames:
print("process...")
if os.path.isfile(r'%s%s' %(origin_xml_dir, filename)): # 获取原始xml文件绝对路径,isfile()检测是否为文件 isdir检测是否为目录
origin_ann_path = os.path.join(r'%s%s' %(origin_xml_dir, filename)) # 如果是,获取绝对路径(重复代码)
new_ann_path = os.path.join(r'%s%s' %(new_xml_dir, filename))
tree = ET.parse(origin_ann_path) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析"
root = tree.getroot() # 获取根节点
for object in root.findall('object'): # 找到根节点下所有“object”节点
name = str(object.find('name').text) # 找到object节点下name子节点的值(字符串)
# 如果name等于str,则删除该节点
# =============================================================================
# if (name in ["middle ball"]):
# root.remove(object)
# =============================================================================
# 如果name等于str,则修改name
if(name in ["small ball","big ball"]):
object.find('name').text = "ball"
# 检查是否存在labelmap中没有的类别
for object in root.findall('object'):
name = str(object.find('name').text)
if not (name in ["ball"]):
print(filename + "------------->label is error--->" + name)
tree.write(new_ann_path)#tree为文件,write写入新的文件中。
3.数据增强
- 开始还在想带有xml的数据集怎么做数据增强,结果发现已经有人做过了,于是直接拿来用,解放双手。(代码来自:https://github.com/mickkky/XML-Augment.git)
- 我们需要修改的参数有5个(在最底下的main函数里面)(使用前需要先确认原始的图片和xml文件夹内的文件是不是一一对应的,比如图片文件夹有一张abc.jpg,则xml文件夹一定有一个abc.xml文件):
- IMG_DIR :原始数据集图片的文件夹路径
- XML_DIR: 原始xml文件的文件夹路径
- AUG_XML_DIR :数据增强后的图片的文件夹路径
- AUG_IMG_DIR:数据增强后的xml文件的文件夹路径
- AUGLOOP :每张图片增强多少次(我设的是20)
import xml.etree.ElementTree as ET
import pickle
import os
from os import getcwd
import numpy as np
from PIL import Image
import shutil
import matplotlib.pyplot as plt
import imgaug as ia
from imgaug import augmenters as iaa
ia.seed(1)
def read_xml_annotation(root, image_id):
in_file = open(os.path.join(root, image_id))
tree = ET.parse(in_file)
root = tree.getroot()
bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin, ymin, xmax, ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
# (506.0000, 330.0000, 528.0000, 348.0000) -> (520.4747, 381.5080, 540.5596, 398.6603)
def change_xml_annotation(root, image_id, new_target):
new_xmin = new_target[0]
new_ymin = new_target[1]
new_xmax = new_target[2]
new_ymax = new_target[3]
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
xmlroot = tree.getroot()
object = xmlroot.find('object')
bndbox = object.find('bndbox')
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
tree.write(os.path.join(root, str("%06d" % (str(id) + '.xml'))))
def change_xml_list_annotation(root, image_id, new_target, saveroot, id,img_name):
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
elem = tree.find('filename')
elem.text = (img_name + str("_%06d" % int(id)) + '.jpg')
xmlroot = tree.getroot()
index = 0
for object in xmlroot.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(os.path.join(saveroot, img_name + str("_%06d" % int(id)) + '.xml'))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__ == "__main__":
IMG_DIR = "./img_val"
XML_DIR = "./temp_valxml"
# =============================================================================
# AUG_XML_DIR = "./Annotations" # 存储增强后的XML文件夹路径
# =============================================================================
AUG_XML_DIR = "./val2017" # 存储增强后的XML文件夹路径
try:
shutil.rmtree(AUG_XML_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_XML_DIR)
# =============================================================================
# AUG_IMG_DIR = "./JPEGImages" # 存储增强后的影像文件夹路径
# =============================================================================
AUG_IMG_DIR = "./valxml" # 存储增强后的影像文件夹路径
try:
shutil.rmtree(AUG_IMG_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_IMG_DIR)
AUGLOOP = 20 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
iaa.Flipud(0.5), # vertically flip 20% of all images
iaa.Fliplr(0.5), # 镜像
iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBs
iaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),
iaa.Affine(
translate_px={
"x": 15, "y": 15},
scale=(0.8, 0.95),
rotate=(-30, 30)
) # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs
])
for root, sub_folders, files in os.walk(XML_DIR):
for name in files:
print(name)
bndbox = read_xml_annotation(XML_DIR, name)
shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)
shutil.copy(os.path.join(IMG_DIR, name[:-4] + '.jpg'), AUG_IMG_DIR)
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))
n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))
n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))
n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))
if n_x1 == 1 and n_x1 == n_x2:
n_x2 += 1
if n_y1 == 1 and n_y2 == n_y1:
n_y2 += 1
if n_x1 >= n_x2 or n_y1 >= n_y2:
print('error', name)
new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,
name[:-4] + str( "_%06d" % (epoch + 1)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, thickness=0)
Image.fromarray(image_auged).save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,
epoch + 1,name[:-4])
print( name[:-4] + str( "_%06d" % (epoch + 1)) + '.jpg')
new_bndbox_list = []
- 最终我使用了 300 张原始样本来增强到了 6000 张图片(6G大小),下面是数据增强后的图片文件夹的样子,可看到原本的一张图片经过各自旋转,光线变化形成了一个新的数据集。

4.xml转json
- 因为nanodet需要json格式的文件,因此我们需要将xml文件转成json文件。
- 训练集的所有xml文件会得到一个大的json文件,验证集同理。
- 使用前需要修改两个参数(在最下面):
- xml_path :xml文件夹的路径(注意!是文件夹,不是文件)
- json_file :要导出的json文件的路径
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = 0
image_id = 'ball-'
id_num = 0
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id,id_num
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_item = dict()
temp = str(id_num)
image_item['id'] = image_id + temp
id_num += 1
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_item['id']
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
#bbox[] is x,y,w,h
#left_top
seg.append(bbox[0])
seg.append(bbox[1])
#left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
#right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
#right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
#elem is , , ,
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
#add img item only after parse tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
#subelem is , , , ,
for subelem in elem:
bndbox ['xmin'] = None
bndbox ['xmax'] = None
bndbox ['ymin'] = None
bndbox ['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
#option is , , , , when subelem is
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
#only after parse the
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
#x
bbox.append(bndbox['xmin'])
#y
bbox.append(bndbox['ymin'])
#w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
#h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id, bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox )
if __name__ == '__main__':
xml_path = "./trainxml"
json_file = './annotations/instances_train2017.json'
parseXmlFiles(xml_path)
json.dump(coco, open(json_file, 'w'))
- 执行后得到两个json文件(训练集和验证集各一个)

- 打开其中一个文件可看到接送文件的格式如下,分为image,types,annotations三大部分。

5.配置config文件
-
完成前面的步骤后,我们的数据集就能创建完成了,如下图所示。
-
然后我们需要在Nanodet的官网上下面训练所需要的源码(Nanodet训练源码),具体文件如下:

-
下一步需要配置Nanodet的cfg文件(在config/ 目录下)

-
我们打开nanodet-m.yml,需要修改下面的参数:
-
save_dir: workspace/nanonet_secondtrain #改成生成的模型及log文件的路径
-
num_classes: 1 #改成数据集的类别
-
指明训练集和验证集的图片文件夹和json文件路径:


-
一些训练的参数修改:

-
class_names: [‘ball’] #修改为各个类别的名字,有多个则在中括号内用逗号隔开
-
6.训练模型
- 我们将终端定位到下载下来的nanodet文件夹下(即如下面所示的文件夹目录),然后在终端输入下面的命令即可:
python tools/train.py CONFIG_PATH
#比如我们刚刚的CONFIG_PATH则为 config/nanodet-m.yml

- 训练过程中有可能会出错,网上搜搜基本都有答案,大多数问题为config文件的路径没写对,或者找不到某个xml文件对应的jpg文件,这时候就需要对数据集进行检查了。
- 同时也有可能会出现训练到几十个epochs就突然中断的情况,但没关系,我们可以打开模型保存的文件夹,会发现它会帮我们自动保存中断前训练的最后一个模型(效果可能还不错)。
- 下面是训练完之后生成的模型:
7.检测模型效果
- 好了,现在我们得到了模型,可以在中断来验证我们模型的效果。
- 如果要测试某张图片,则使用下面的命令:
- 其中,CONFIG_PATH 为开始的config文件,MODEL_PATH 为刚刚生成的pth文件,IMAGE_PATH为图片的路径
python demo/demo.py image --config CONFIG_PATH --model MODEL_PATH --path IMAGE_PATH
- 测试视频则使用下面的代码:
python demo/demo.py video --config CONFIG_PATH --model MODEL_PATH --path VIDEO_PATH
8.转换pth文件为onnx文件
- 实际上,我们最终的模型是希望在Qt上面用C++跟opencv来运行的,而要想让opencv来导入我们的模型,还需要将pth格式的文件转换为onnx。具体操作如下:
- 我们先定位到之前下载下来的nanodet目录,进入tools目录,打开export.py文件,配置cfg_path model_path out_path三个参数。
- cfg_path 为最开始配置的 aaa.yml
- model_path 为训练生成的 bbb.pth
- out_path 为我们希望导出的 ccc.onnx 这里的可以随便写
- 再次定位到nanodet目录,运行 python tools/export.py 得到转换后的onnx模型
- 我们先定位到之前下载下来的nanodet目录,进入tools目录,打开export.py文件,配置cfg_path model_path out_path三个参数。
9.转换ONNX文件为IR模型(xml和bin)
- 实际上,我们还能通过openvino来对工程进行加速,但是过程中遇到了许多坑,而且本项目最终也没有用到openvino,因此此处不展开,有兴趣的可以参考下面的文章:
- 手把手教你使用OpenVINO部署NanoDet模型
- openvino踩坑记录——onnx模型转换成IR中间模型
- 实验室的小伙伴还发现了一个坑,如果将onnx转换为IR模型(xml和bin文件)的过程中出现了“ opset_version=11”的错误,可以把 export.py中的torch.onnx.export(model, dummy_input, output_path, verbose=True, keep_initializers_as_inputs=True, opset_version=11)的11改成10.
- 或者,如果你也是在linux多次失败被折磨到心态炸裂也可以跟我一样在Windows配置openvino然后进行模型转换:【OpenVINO】Win 10安装配置OpenVINO指南
10.在Qt上用C++ 和 opencv部署Nanodet模型
- 首先我们需要下载网上一位大神的项目代码:nanodet-opncv-dnn

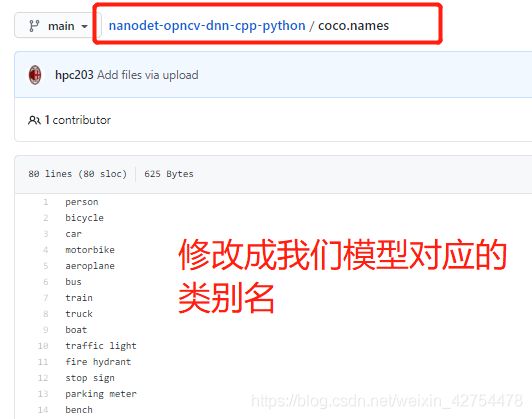
- 然后需要修改其中的coco.names为我们自己模型的类别的名字:
- 在Qt中的pro文件配置好Opencv的lib路径后,导入main.cpp,修改其中的onnx文件为我们自己训练出来的onnx文件:

- 修改测试图片的路径为我们要测试的图片路径:
- 修改 NanoDet nanonet(320, 0.2, 0.6);中的第二个参数,表示置信度为多少的时候才框出小球,值在0-1之间,设得越大则越严格。
- 到这里,我们就基本完成了将模型部署到Qt上的步骤了,运行之后应该能显示出我们检测出来的小球的图片。
11.目标检测效果
- 我们测试了不同场景下对于不同小球的效果,发现效果还可以。

路径规划算法
- 做到这一步的话,这个项目基本上完成一半了,因为你会发现配环境和训练模型才是这个项目中最头疼的一步,接下来的事情无非可以看作是一道算法题来解决。算法有好有坏,但至少能够做出来。
- 其中无非就是在上面部署好的项目上面把测试图片改成用摄像机实时获取图片然后实时处理,而对于每帧图片,先做一次目标检测得到当前检测到的小球的vector< Point2i >信息(坐标和个数),然后再针对这些信息来进行数学上的运算以得到我们所需要的决策信息,最后再加入串口通信的代码将我们的信息发送给电控即可。
1.路径规划状态机
- 先来看一下路径规划的整体算法思路:
- 我将整个程序分成五个模式。
- 首先是开机通过shell脚本自启动我们的项目工程,通过目标检测模型判断当前视野中是否能够看到小球,如果能看到小球,那就进入捡球模式,如果看不到小球,那就进入原地旋转模式。
- 如果在捡球的过程中我们的视野也看不到小球了,也会进入原地旋转模式。
- 我们通过测量摄像头的广角为40度,因此在原地旋转的状态下,我们一次顺时针转40°:
- 转完之后如果检测到了小球,那就进入捡球模式
- 如果还是看不到小球,就继续顺时针转40°。
- 如果转了一圈还是看不到小球,说明当前的范围内是没有小球的,我们就需要进入到环形找球的模式中。
- 在环形找球模式下,我们按照如下图所示的类似迷宫一样的环形进行地图的遍历:
- 在遍历的过程中如果看到有球,则马上进入捡球模式
- 如果走过了一定范围还没有看到小球,则进入关机状态。
- 有两个细节是需要注意的:
- 1.在捡球状态下以及原地旋转状态下的操作是具有原子性的:
- 比如我们在捡球状态下执行前进1米的操作中途突然看不到小球,这时候不会立刻切换到原地旋转状态,而是等走完这一米再切换。
- 同样我们在原地旋转状态下如果转的过程中突然看到了小球,也不会突然切换到捡球状态,而是等转完40°再做判断。(这是因为如果旋转过程中看到第一个球就去捡,那效率会非常低)
- 2.在环形找球状态下的操作不具有原子性,这是因为如果我们等走完当前的路径再去切换状态,很有可能走的过程中看到了小球,但是走完之后小球就消失了。而原地旋转则不会出现这种现象。
- 1.在捡球状态下以及原地旋转状态下的操作是具有原子性的:
- 实际上评委老师还提到了一个思路,即可以先原地转一周,然后看看哪个方向上的小球最多,再转到那个方向上去捡。
- 之所以不考虑这个方法,是因为在测试中发现我们的小车是绕着车尾为圆心进行转的,而转的过程中会发生偏移,即转完一周之后,它的位置基本上不在原来的位置上了。
- 因此我的思路是不能转太多再做决策,否则会误差很大。

- 下面是更加详细的流程图:

2.选择最佳方向和前进距离
- 上面从宏观上介绍了整个路径规划算法,实际上非常简单,而最难的地方是在捡球的状态下,我们怎么根据当前摄像机的视野来决定要往哪个方向进行移动。
- 而我们的衡量标准是走最短的路,捡最多的球。因为问题就转化为怎么按照这个标准找到最佳的结果。
2.1思路一、遍历每个小球看哪个小球周围的球的个数最多
- 通过对每个小球进行遍历,看看半径为r的范围内有几个小球,找到最多小球的那个方向进行前进。
- 其中r为我们小车的捡球铲子所能铲过的范围。
- 而前进的距离则根据该前进方向上面最远的那个小球距离小车的距离
2.2思路二、基于DBSCAN的小球数量-距离权重聚类算法
- 该方法是跟实验室的一个朋友讨论出来的思路,因为DBSCAN算法可以进行聚类,我们可以把当前获得的图像看成是一个二维坐标系,而每个小球则相当于一个点。
- 而每个点都能算出其中心点来代表其在二维坐标系上的位置,因此就可以用DBSCAN对整个坐标系进行聚类,同时每一个小球能根据其在二维坐标上的坐标通过非线性地映射函数大致得到其在三位坐标上的距离,再根据这个距离计算出一个权重(距离越远权重越小)
- 我们求出每个类的小球的价值总和,选择价值最高的方向并计算出其质心,作为前进的方向。
- 而前进的距离则根据该前进方向上面最远的那个小球距离小车的距离
2.3思路三、基于方向的小球数据-距离权重算法
-
最终我还是选择了思路三,因为感觉这个方法虽然最简单,但是又最有效果。
-
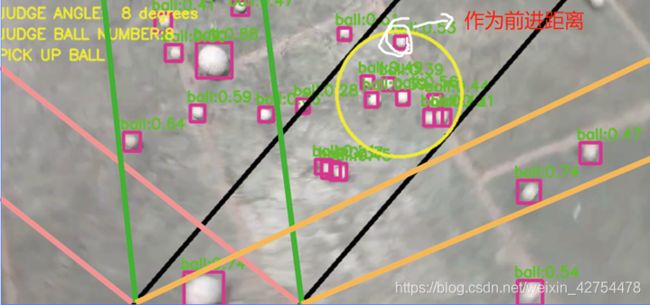
我们通过遍历不同方向,模拟出各个方向上可以简单的小球的个数。同时通过距离映射函数计算出每个小球的权重,进而计算出每个方向上面的权重之和。最后选出价值最大的方向作为前进的方向,而前进的距离则根据该前进方向上面最远的那个小球距离小车的距离,算法示意图如下所示。
-
下面详细说一下非线性映射函数怎么计算出来。
- 首先我们在真实世界中每隔10cm摆一个小球,然后通过摄像机摆出其在二维图像上面的坐标,然后我们可以得到一个二维坐标到三维距离的映射表。
- 可以看到在图像下方的小球每相隔10cm其纵坐标差得很多,而在图像上方的小球则相差不大,因此其类似一个幂函数。
- 我们通过excel的曲线拟合则可以计算出一个映射函数。

-
下面是该算法检测运动中的小球的动态图:
总结
- 上面大致为该项目的整体流程,而实际上上面都是从宏观的角度进行介绍,具体的实现可以到github上面通过代码来深入了解。
- 总得来说,该项目还有很多细节可以完善,毕竟为了赶进度在代码的细节上有较多不规范的地方,而算法部分有些地方也可以做到更精确,让捡球的效率更高。