HDFS数据安全与Java API的简单使用
HDFS数据安全与Java API的简单使用
- HDFS数据安全
-
- 元数据安全
-
- 元数据产生
- 元数据存储
- SecondaryNameNode
- Java API的简单使用
-
- 应用场景
- 相关配置
-
- Maven配置
- 本地开发环境配置
- 集群启动
-
- 启动ZooKeeper
- 启动HDFS
- 启动YARN
- 构建连接
- 释放资源
- 获取集群信息
- 创建目录及列举
- 上传及下载
- 合并上传
- 权限
- 集群关机
-
- 关闭HDFS
- 关闭YARN
- 关闭ZooKeeper
- 断电
先看这2篇:
ZooKeeper概述
HDFS概述
HDFS数据安全
元数据安全
元数据产生
格式化的时候就会产生磁盘元数据文件,在node1使用:
cd /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas/current/
切换目录并ll -ah查看:
[root@node1 current]# cd /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas/current/
[root@node1 current]# ll -ah
总用量 24K
drwxr-xr-x 2 root root 222 4月 25 23:12 .
drwxr-xr-x 3 root root 40 4月 25 21:36 ..
-rw-r--r-- 1 root root 0 4月 25 23:12 edits.xml
-rw-r--r-- 1 root root 3.3K 4月 25 21:56 fsimage_0000000000000000501
-rw-r--r-- 1 root root 62 4月 25 21:56 fsimage_0000000000000000501.md5
-rw-r--r-- 1 root root 3.5K 4月 25 22:56 fsimage_0000000000000000519
-rw-r--r-- 1 root root 62 4月 25 22:56 fsimage_0000000000000000519.md5
-rw-r--r-- 1 root root 0 4月 25 23:10 fsimage.xml
-rw-r--r-- 1 root root 4 4月 25 22:56 seen_txid
-rw-r--r-- 1 root root 203 4月 25 21:36 VERSION
这些fsimage就是元数据文件。
元数据存储
元数据存储在NameNode维护的内存中,在磁盘中还有fsimage文件(HDFS首次格式化时产生,用以持久化元数据文件),NameNode启动时会被加载到内存。但是NameNode需要经常读写元数据,如果元数据都存储在硬盘的文件中会导致读写性能极差,都存储在内存中,如果宕机重启,原先存储在内存的数据会大量丢失。
∴需要edits文件,将内存中的元数据的变化记录在deits文件中,宕机重启时,NameNode启动时会将fsimage文件与edits文件合并,生成原来的数据。有点像增量保存,或者快照。
SecondaryNameNode
如果长时间开机,edits文件的体积会变得很大,由于记录的是变化情况,时间久远的大量无用数据很占用硬盘,NameNode启动时还会从最开始一步一步恢复状态,很多步骤显然是多余的。
此时就需要SecondaryNameNone,阶段性地合并fsimage文件和edits文件,生成最新的fsimage文件,当下次NameNode启动时,只需要加载最新的fsimage文件和少量的edits文件的内容即可快速完成元数据的恢复。
没有SecondaryNameNode集群照样可以跑起来,但是会导致集群启动越来越慢。实际上,由于一般使用HA模式确保数据安全性,更愿意使用闲置的NameNode(Standby状态)代替SecondaryNameNode的功能。
Java API的简单使用
应用场景
使用命令行Client一般用作管理类操作,大规模读写当然不可能使用手动命令行读写的方式,会累死人的。。。需要大规模读写大量数据的适合显然需要通过编程的方式自动进行。
一般使用分布式计算程序封装HDFS Java API,然后利用分布式计算程序实现对HDFS数据的读写。
相关配置
Maven配置
在新项目的pom.xml添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>
锁定编译版本为JDK1.8:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
最后记得把log4j.properties拖到resources里。
本地开发环境配置
先配置win10的环境变量:
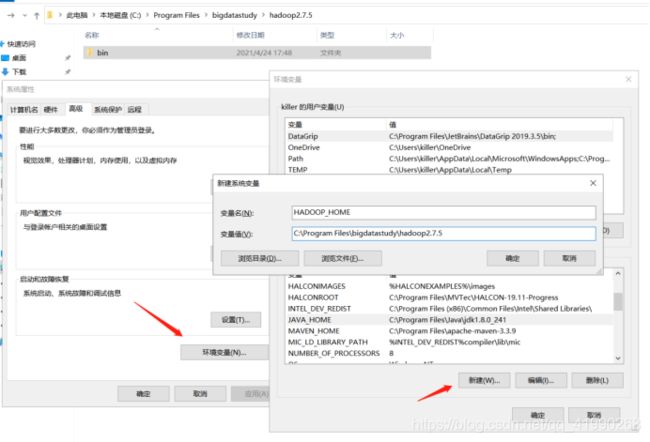
笔者把Hadoop包放C盘了,故新建HADOOP_HOME和C:\Program Files\bigdatastudy\hadoop2.7.5。
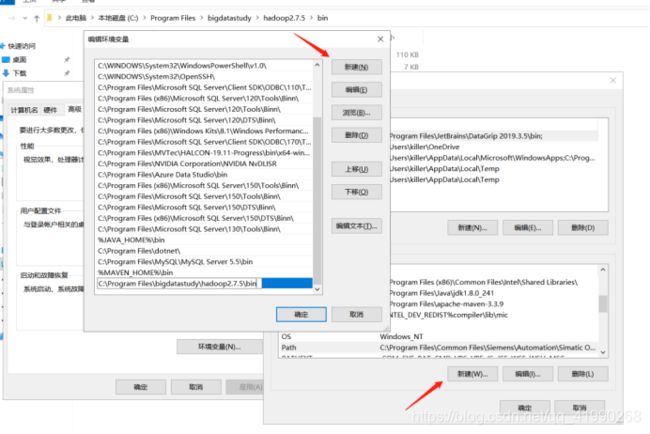
在Path里新建:C:\Program Files\bigdatastudy\hadoop2.7.5\bin:
集群启动
由于笔者的集群宕机了:ens33网卡丢失,无奈reboot,没办法从挂起状态直接恢复了,只好重新启动。。。
启动ZooKeeper
3台虚拟机都使用cd /export/server/zookeeper-3.4.6/切换目录。
使用
bin/zkServer.sh status
查看ZooKeeper状态,未启动则在node1使用:
bin/zkServer.sh start
启动ZooKeeper服务,任何再次查看ZooKeeper的状态:
[root@node1 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[root@node2 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
[root@node3 zookeeper-3.4.6]# bin/zkServer.sh status
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
此时node1和node3为follower,node
2为leader,状态正常。
启动HDFS
node1使用:
start-dfs.sh
即可启动HDFS:
[root@node1 zookeeper-3.4.6]# start-dfs.sh
Starting namenodes on [node1]
node1: starting namenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-namenode-node1.out
node3: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node3.out
node2: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node2.out
node1: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node1.out
Starting secondary namenodes [node1]
node1: starting secondarynamenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-secondarynamenode-node1.out
启动YARN
node1使用:
start-yarn.sh
即可启动YARN:
[root@node1 zookeeper-3.4.6]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-resourcemanager-node1.out
node2: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node2.out
node3: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node3.out
node1: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node1.out
3台机都使用jps查看进程:
[root@node1 zookeeper-3.4.6]# jps
2000 NameNode
2560 NodeManager
2704 Jps
1830 QuorumPeerMain
2138 DataNode
2301 SecondaryNameNode
[root@node2 zookeeper-3.4.6]# jps
2066 NodeManager
1956 DataNode
1852 QuorumPeerMain
2189 Jps
[root@node3 zookeeper-3.4.6]# jps
2160 DataNode
2393 Jps
2013 QuorumPeerMain
2270 NodeManager
集群的启动也是件麻烦事。。。貌似有必要重新写个一键启动的shell脚本了。。。
构建连接
在new新对象时,一定要导对包(导Hadoop的包)
先构建文件系统的连接对象:
FileSystem fs = null;
然后构建连接的实例:
@Before
public void getFS() throws Exception {
//构建Configuration对象,每个Hadoop都需要对象,用于管理当前程序的所有配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node1:8020");
//构建文件系统实例
fs = FileSystem.get(conf);//给定配置,必须知道服务端地址
//fs = FileSystem.get(new URI("hdfs://node1:8020"),conf);//给定配置以及服务端地址
//fs = FileSystem.get(new URI("hdfs://node1:8020"),conf,"root");//给定配置、服务端地址、用户身份
}
这一步,可以使用配置文件,也可以手动使用conf.set()方法逐一设置。
如果配置文件中没有写Server地址,或者需要强制使用Linux的用户身份,就需要后2种方法(默认按照配置文件,用户身份为当前的Windows用户)。
释放资源
由于每一步测试都新建了对象,为了防止程序结束后没有回收资源导致发生端口挤占等后果,影响程序运行,先把最后一步写好:
@After
public void closeFS() throws IOException {
fs.close();
}
之后的测试段代码就可以放在@Before和@After之间。
获取集群信息
//打印每个DataNode节点的状态信息
@Test
public void printDNinfo() throws IOException {
//集群管理,必须构建分布式文件系统对象
DistributedFileSystem dfs = (DistributedFileSystem) this.fs;
//调用方法
DatanodeInfo[] dataNodeStats = dfs.getDataNodeStats();
//遍历输出iter
for (DatanodeInfo dataNodeStat : dataNodeStats) {
System.out.println("dataNodeStat.getDatanodeReport() = " + dataNodeStat.getDatanodeReport());
}
}
运行后:
dataNodeStat.getDatanodeReport() = Name: 192.168.88.9:50010 (node1)
Hostname: node1
Decommission Status : Normal
Configured Capacity: 37688381440 (35.10 GB)
DFS Used: 1134592 (1.08 MB)
Non DFS Used: 3649200128 (3.40 GB)
DFS Remaining: 34038046720 (31.70 GB)
DFS Used%: 0.00%
DFS Remaining%: 90.31%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Apr 25 21:59:54 CST 2021
dataNodeStat.getDatanodeReport() = Name: 192.168.88.10:50010 (node2)
Hostname: node2
Decommission Status : Normal
Configured Capacity: 37688381440 (35.10 GB)
DFS Used: 1134592 (1.08 MB)
Non DFS Used: 3030994944 (2.82 GB)
DFS Remaining: 34656251904 (32.28 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.95%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Apr 25 21:59:54 CST 2021
dataNodeStat.getDatanodeReport() = Name: 192.168.88.11:50010 (node3)
Hostname: node3
Decommission Status : Normal
Configured Capacity: 37688381440 (35.10 GB)
DFS Used: 1134592 (1.08 MB)
Non DFS Used: 3136466944 (2.92 GB)
DFS Remaining: 34550779904 (32.18 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.67%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Apr 25 21:59:54 CST 2021
Process finished with exit code 0
看样子,宕机重启之后问题不大。。。
创建目录及列举
//创建目录及列举查看
@Test
public void mkdirAndList() throws Exception{
//构建创建的路径对象
Path path = new Path("/bigdata");
//判断目录是否存在
if(fs.exists(path)){
//如果存在先删除
fs.delete(path,true);
}
//创建
fs.mkdirs(path);
//列举文件/目录的状态
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
//遍历输出iter
for (FileStatus fileStatus : fileStatuses) {
System.out.println("fileStatus.getPath().toString() = " + fileStatus.getPath().toString());
}
}
执行后:
fileStatus.getPath().toString() = hdfs://node1:8020/bigdata
fileStatus.getPath().toString() = hdfs://node1:8020/tmp
fileStatus.getPath().toString() = hdfs://node1:8020/user
fileStatus.getPath().toString() = hdfs://node1:8020/wordcount
Process finished with exit code 0
浏览器打开node1:50070:
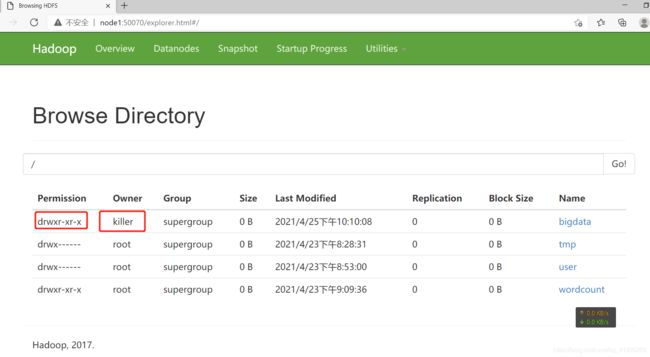
是以本机用户名创建的目录。。。有时候为了避免出问题,就会使用上文构建连接时的其它方式创建对象。
也可以用另一种方式(迭代器)来遍历所有的文件:
//只能遍历文件
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/tmp"), true);
while (listFiles.hasNext()) {
System.out.println("listFiles.next().getPath().toString() = " + listFiles.next().getPath().toString());
}
执行后:
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0001-1619180910263-root-word+count-1619180974197-3-1-SUCCEEDED-default-1619180919881.jhist
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0001.summary
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0001_conf.xml
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0002-1619181906959-root-hadoop%2Dmapreduce%2Dclient%2Djobclient%2D2.7.5%2Dtests.jar-1619181942320-10-1-SUCCEEDED-default-1619181915720.jhist
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0002.summary
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0002_conf.xml
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0003-1619182045083-root-hadoop%2Dmapreduce%2Dclient%2Djobclient%2D2.7.5%2Dtests.jar-1619182068279-10-1-SUCCEEDED-default-1619182049875.jhist
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0003.summary
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/hadoop-yarn/staging/history/done_intermediate/root/job_1619179579492_0003_conf.xml
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0001/node3_39678
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0002/node1_45723
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0002/node2_38036
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0002/node3_39678
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0003/node1_45723
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0003/node2_38036
listFiles.next().getPath().toString() = hdfs://node1:8020/tmp/logs/root/logs/application_1619179579492_0003/node3_39678
Process finished with exit code 0
为神马使用这种远程迭代器?远程迭代器的好处这一篇有解释过。
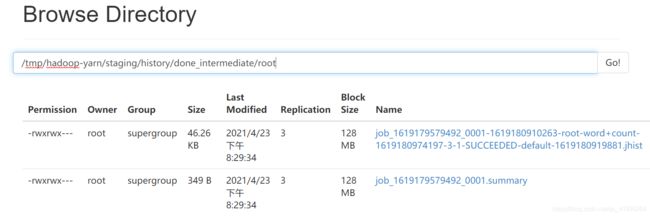
结果显然是正确的。
上传及下载
//实现文件的上传与下载
@Test
public void uploadAndDownload() throws Exception {
//上传:将本地文件放入HDFS
Path localPath1 = new Path("file:///E:\\bigdata\\hello.txt");
Path hdfsPath1 = new Path("/bigdata");
fs.copyFromLocalFile(localPath1,hdfsPath1);
//下载:将HDFS文件放到本地
Path localPath2 = new Path("file:///E:\\bigdata");
Path hdfsPath2 = new Path("/tmp/logs/root/logs/application_1619179579492_0001/node3_39678");
fs.copyToLocalFile(hdfsPath2,localPath2);
}

上传成功!!!
下载也成功!!!
合并上传
这种功能会把小文件合并为一个大文件进行存储:
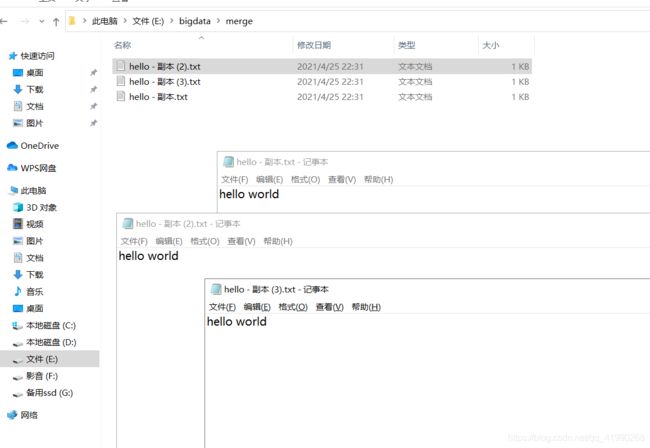
执行代码:
//合并上传小文件
@Test
public void nergeFile() throws IOException {
//打开要合并的所有文件,构建输入流
LocalFileSystem local = FileSystem.getLocal(new Configuration());
//构建一个HDFS输出流,生成文件
FSDataOutputStream outputStream = fs.create(new Path("/bigdata/merge.txt"));
//遍历文件iter
FileStatus[] fileStatuses = local.listStatus(new Path("E:\\bigdata\\merge"));
for (FileStatus fileStatus : fileStatuses) {
//打开每个文件并创建输入流
FSDataInputStream inputStream = local.open(fileStatus.getPath());
//将输入流的数据放入输出流
IOUtils.copyBytes(inputStream,outputStream,4096);
//关闭输入流
inputStream.close();
}
//循环结束,关闭输出流
outputStream.close();
//关闭文件系统
local.close();
}
之后,可以看到:
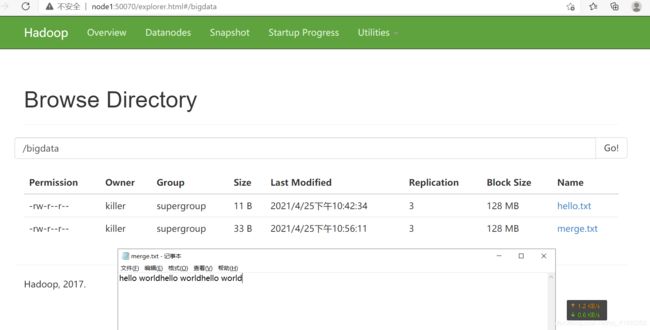
内容被合并!!!
权限
HDFS默认开启了权限,但是之前使用:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
禁用了权限管理。
fs = FileSystem.get(new URI("hdfs://node1:8020"),conf,"root")
这种方式就是冒充root用户进行操作的。。。
集群关机
为了避免之前的故障,不使用挂起了。。。使用关机貌似更安全。。。
关闭HDFS
node1使用:
stop-dfs.sh
关闭YARN
node1使用:
stop-yarn.sh
关闭HDFS时可能已经关闭了YARN,为了确保万无一失,还是再使用一次,并使用jps查看进程确保安全。
关闭ZooKeeper
这一步其实可以不用做。。。∵每次开机都要启动它。。。
cd /export/server/zookeeper-3.4.6/
bin/zkServer.sh stop
断电
3台机统一:
poweroff