python自动化(一)基础能力:9.python基础上之正则表达式
一.正则表达式概述

二.re模块讲解




三.正则表达式字符讲解
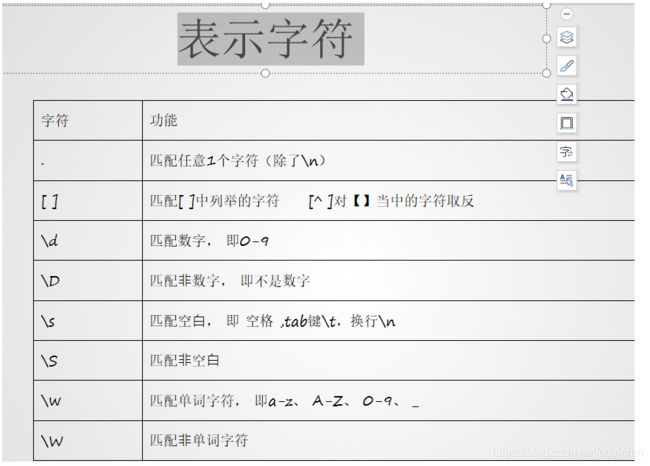


import re
ret = re.match("[hH]","Hello Python")
print(ret.group())
# 结果为H
import re
ret = re.match("[0-9]","7Hello Python")
print(ret.group())
# 结果为:7
import re
ret = re.match("\d","7Hello Python")
print(ret.group())
# 结果为:7
四.原始字符与转义字符


#要匹配一个\
import re
ret1 = re.match("\\\\","\\")
print(ret1.group())
# 结果为\ 因为python中“\\”表示“\”,而在正则表达式中“\\”表示“\” 所以前面的匹配表达式,需要4个“\”来表示“\”
import re
ret = re.match(r"c:\\a",r"c:\a\b\c")
print(ret.group())
#结果为 c:\a 注意:r只能取消python中的转义,不能取消正则表达式中的转义
五.正则表达式中的数量


import re
ret = re.match("[A-Z][a-z]*","AabbBcdef")
print(ret.group())
# 结果为 Aabb
六.正则表达式中的边界


七.正则表达式中的分组





八.贪婪和非贪婪模式


总结
到这里python的基础部分就差不多学完了,对于web框架di’gan’go# 一.正则表达式概述
# 二.re模块讲解# 三.正则表达式字符讲解pythonimport reret = re.match("[hH]","Hello Python")print(ret.group())# 结果为Himport reret = re.match("[0-9]","7Hello Python")print(ret.group())# 结果为:7import reret = re.match("\d","7Hello Python")print(ret.group())# 结果为:7# 四.原始字符与转义字符python#要匹配一个\import reret1 = re.match("\\\\","\\")print(ret1.group())# 结果为\ 因为python中“\\”表示“\”,而在正则表达式中“\\”表示“\” 所以前面的匹配表达式,需要4个“\”来表示“\”import reret = re.match(r"c:\\a",r"c:\a\b\c")print(ret.group())#结果为 c:\a 注意:r只能取消python中的转义,不能取消正则表达式中的转义# 五.正则表达式中的数量pythonimport reret = re.match("[A-Z][a-z]*","AabbBcdef")print(ret.group())# 结果为 Aabb# 六.正则表达式中的边界# 七.正则表达式中的分组# 八.贪婪和非贪婪模式# 总结
到这里python的基础部分就差不多学完了。
